Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
10.6
-
GNU/Linux on ARMv8 (Aarch64)
Description
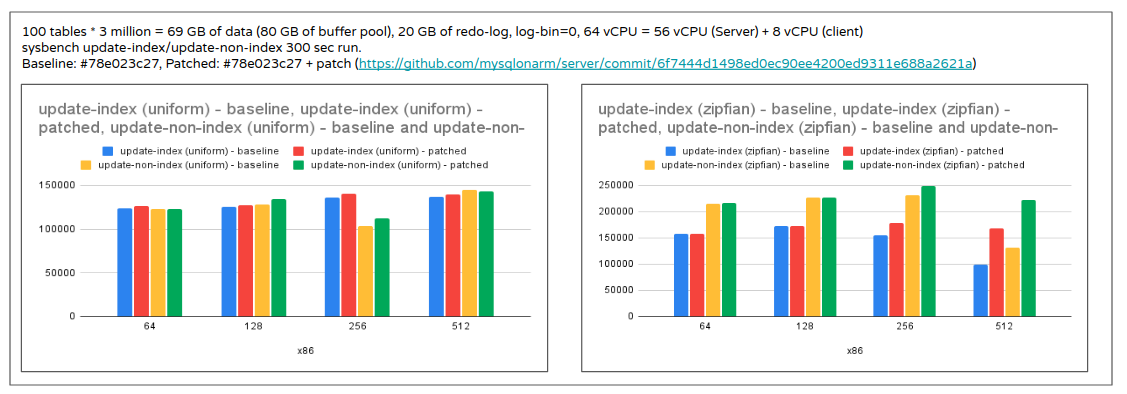
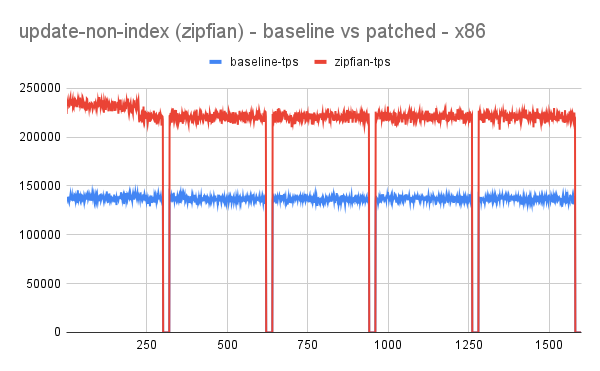
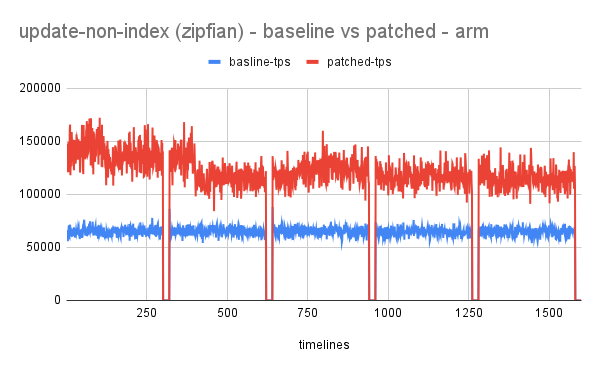
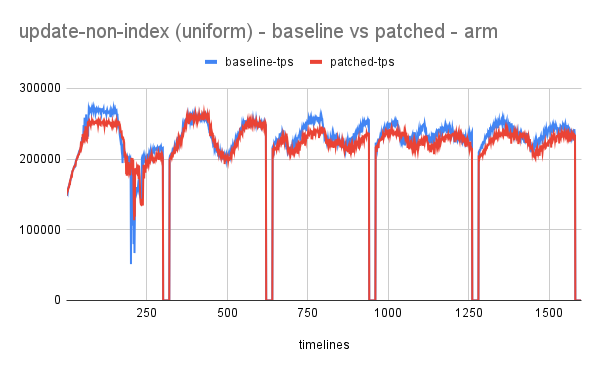
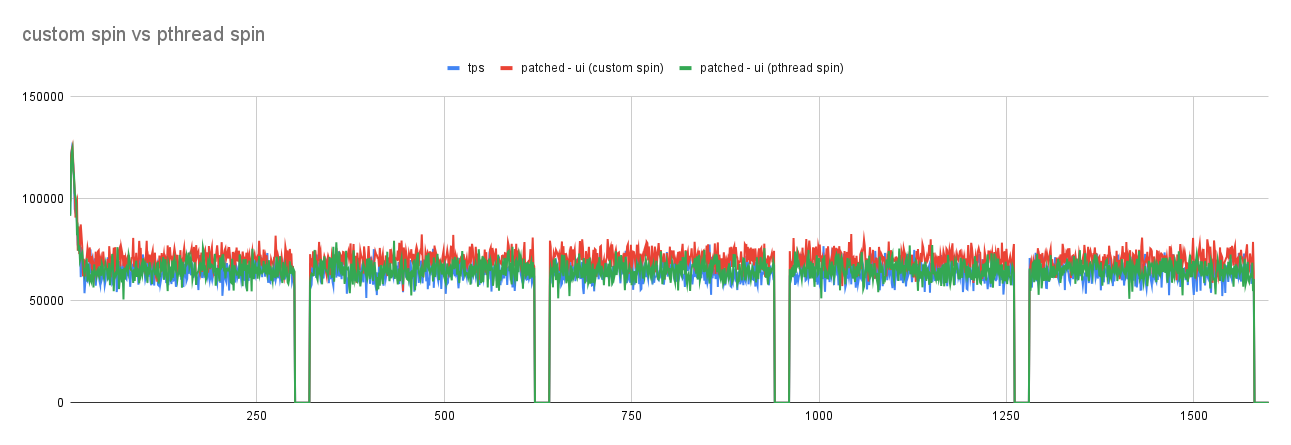
reduce lock_sys.wait_mutex contention by using spinloop construct
- wait_mutex plays an important role when the workload involves conflicting transactions.
- On a heavily contented system with increasing scalability
quite possible that the majority of the transactions may have to wait
before acquiring resources.
- This causes a lot of contention of wait_mutex but most of this
the contention is short-lived that tend to suggest the use of spin loop
to avoid giving up compute core that in turn will involve os-scheduler with additional latency.
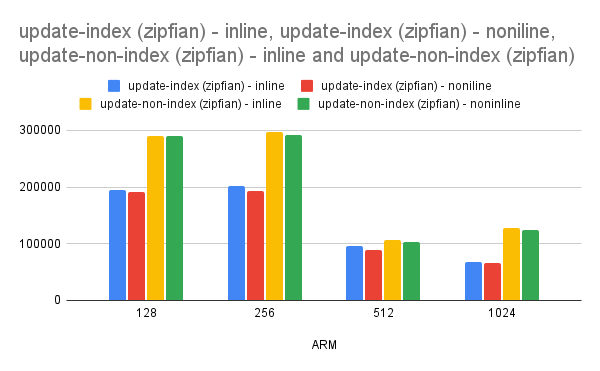
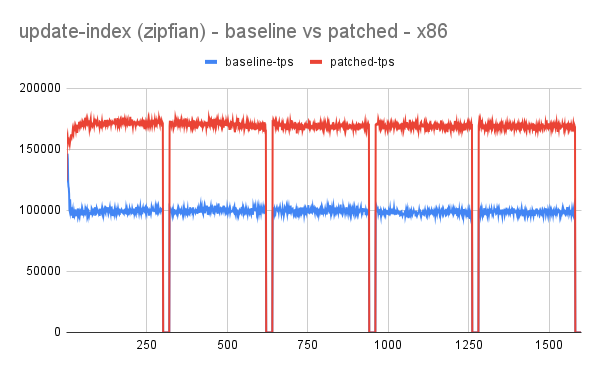
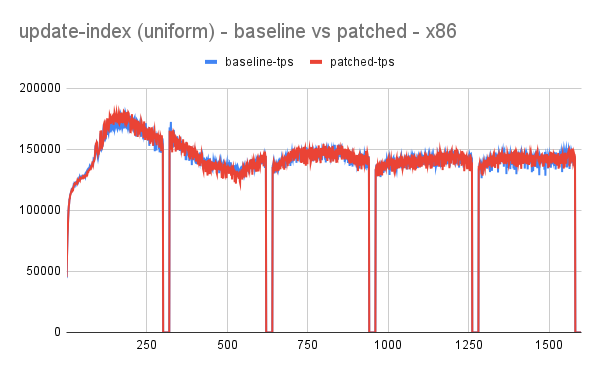
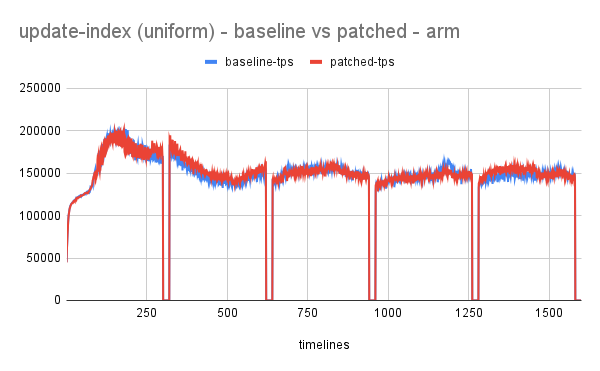
- Idea has shown promising results with performance improving up to 70-100% for write workload.
Attachments




Issue Links
- is caused by
-
-
- Closed
-
- relates to
-
MDEV-16232 Use fewer mini-transactions
-
- Stalled
-
-
-
- Open
-
