Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
10.5(EOL)
Description
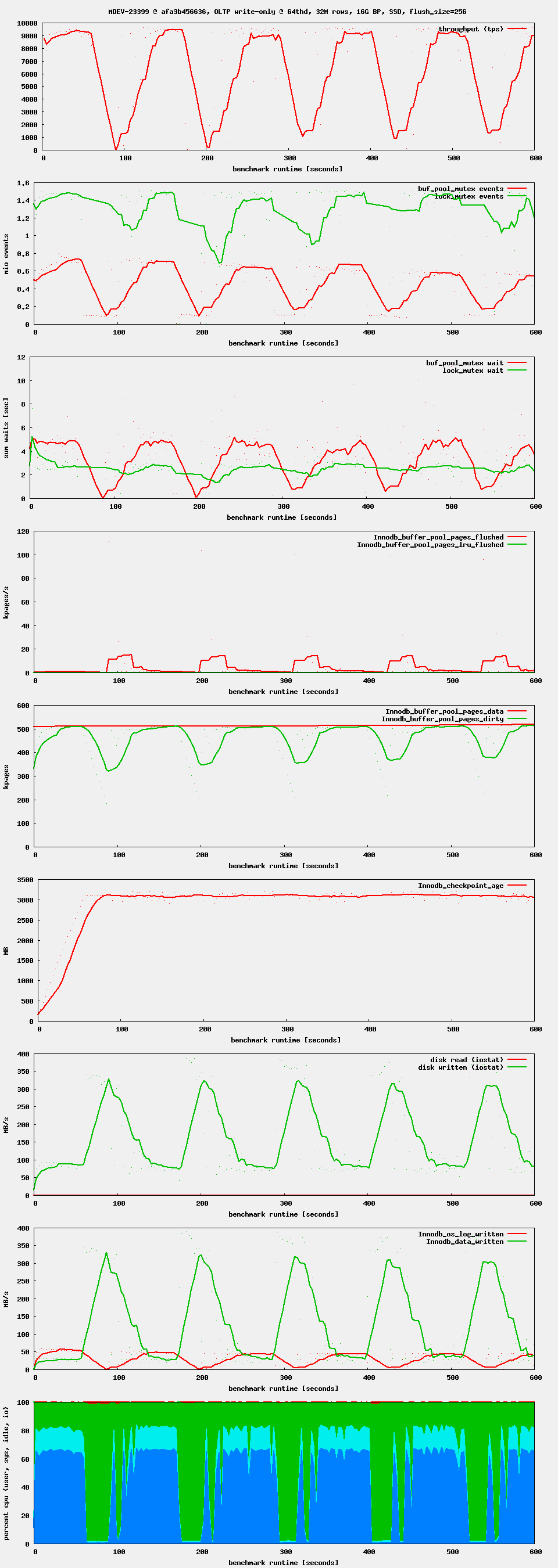
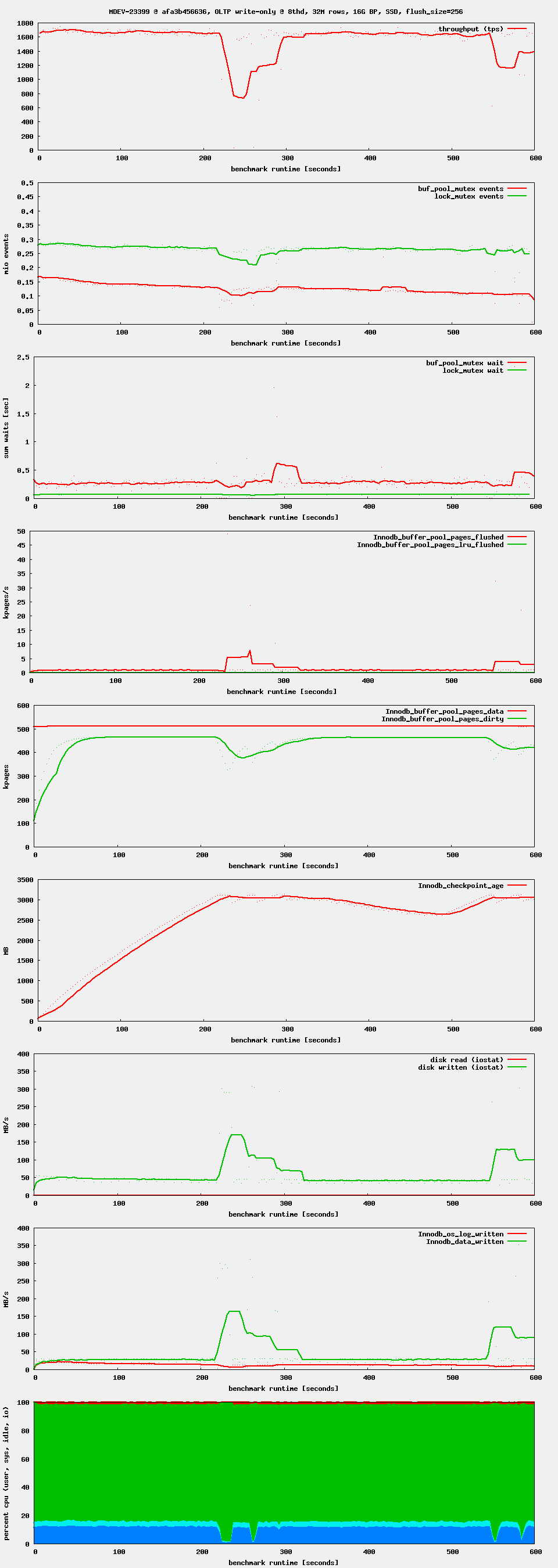
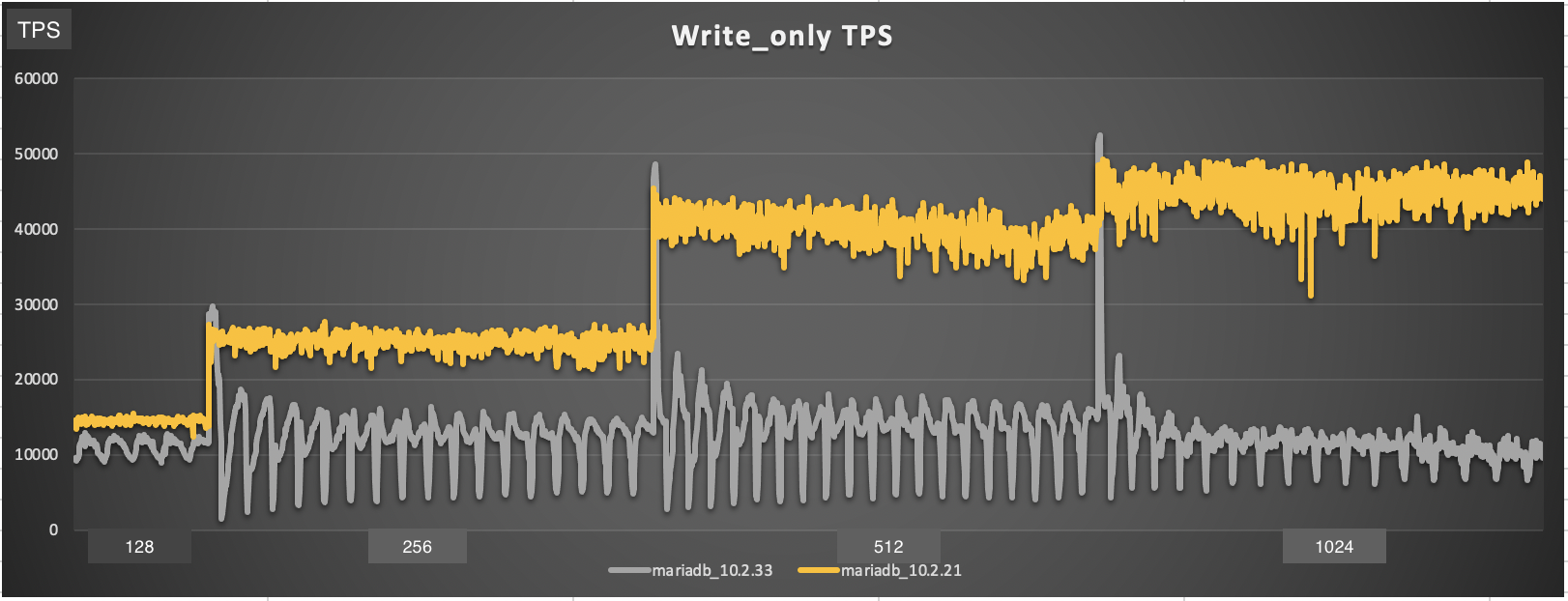
Workload: sysbench OLTP write-only, i.e. as it is used by the regression benchmark suite in t_writes_innodb_multi.
Setup: 16G buffer pool. 4G redo log. 4G or 8G data set. innodb_flush_neighbors = 0, innodb_io_capacity = 1000 (or 5000, 10000)
Observation: after starting high, performance drops after ~ 1 minute. If waiting long enough, one can see oscillations in throughput. This seems to be related to Innodb_checkpoint_age reaching Innodb_checkpoint_max_age. There seems to be no LRU flushing at all, only flush_list flushing.
Attachments
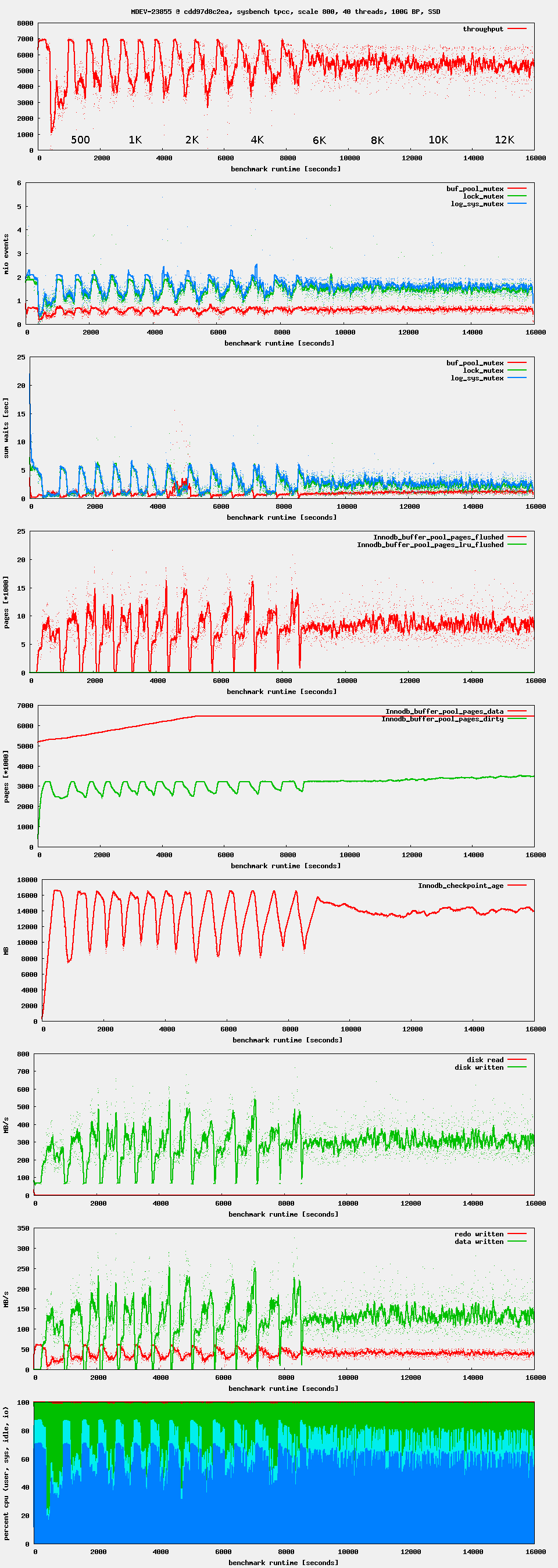
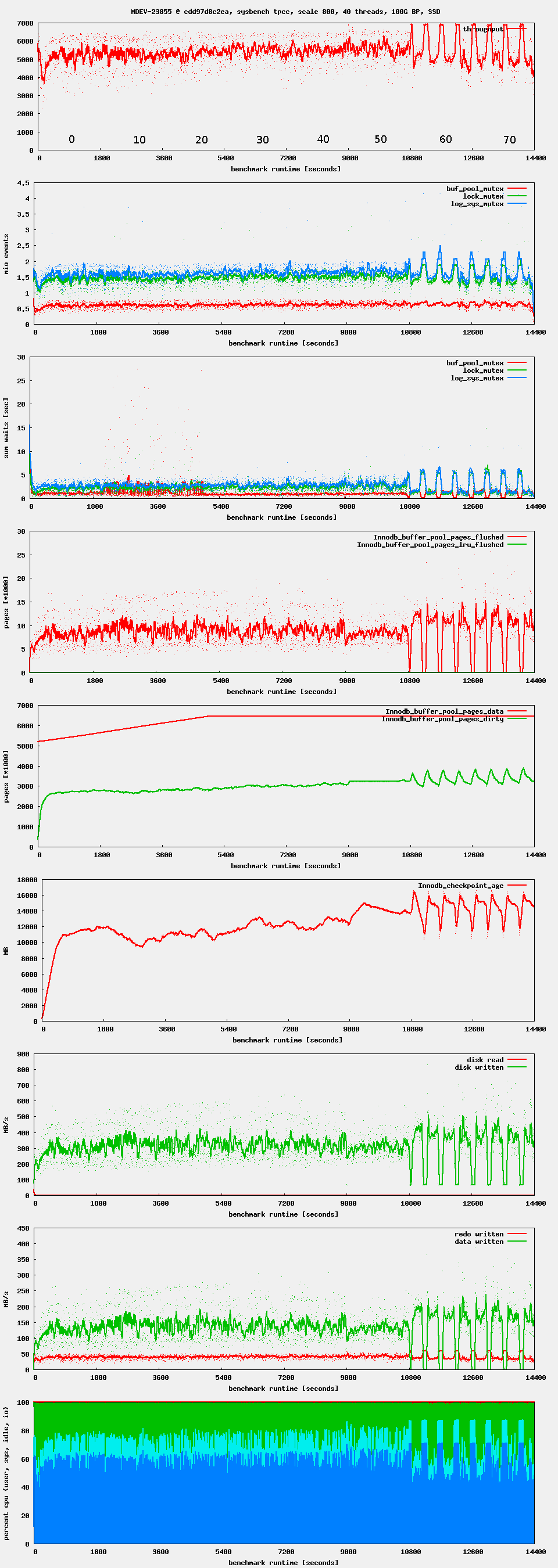
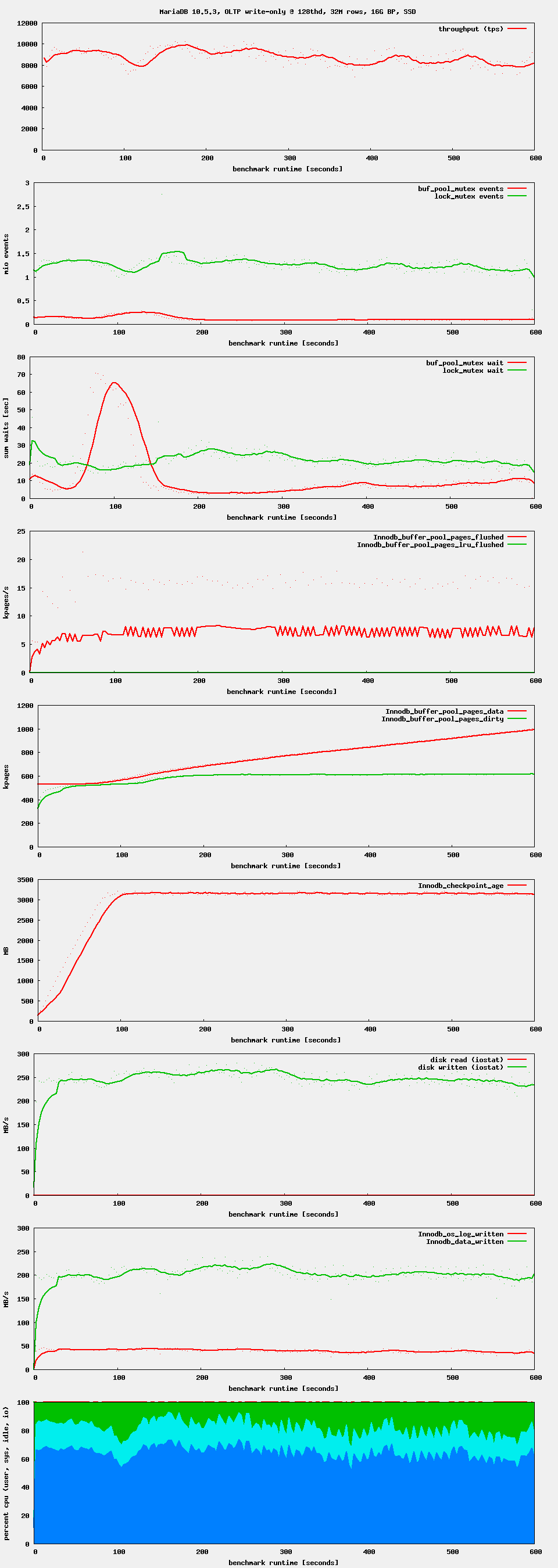

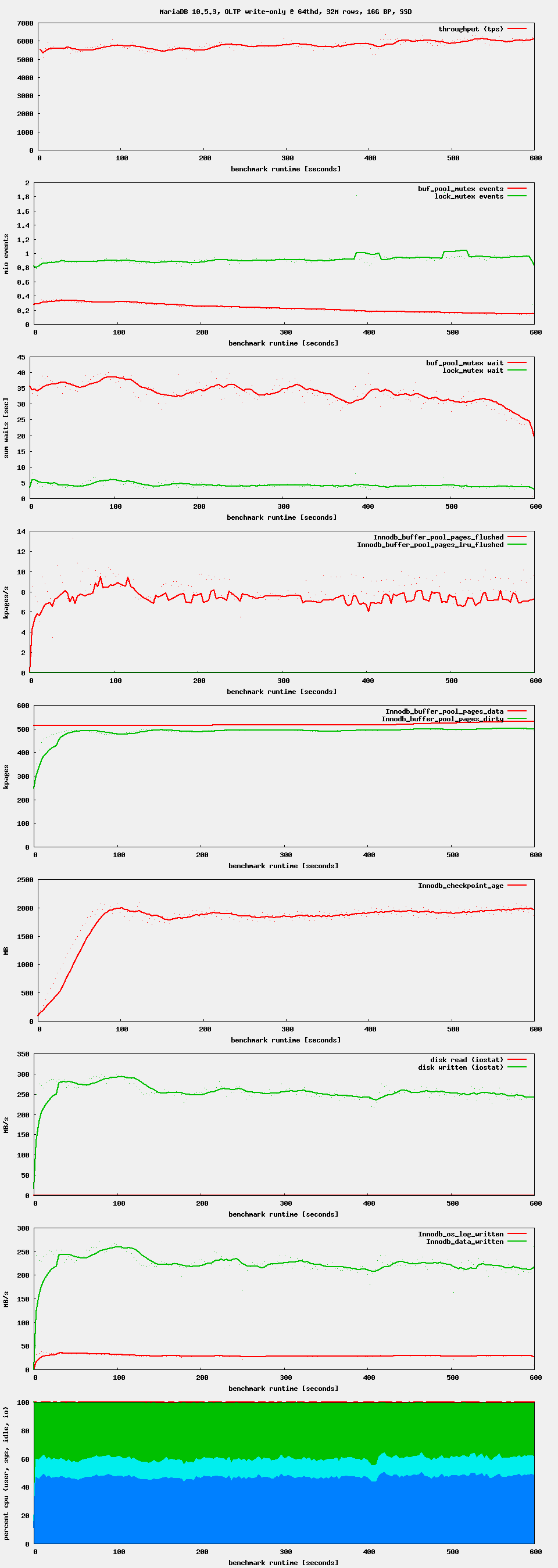
Issue Links
- blocks
-
MDEV-11659 Move the InnoDB doublewrite buffer to flat files
-
- Closed
-
-
-
- Open
-
-
-
- Closed
-
- causes
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
- is blocked by
-
-
- Closed
-
-
-
- Closed
-
- relates to
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Confirmed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
