Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Fixed
-
11.1.1, 11.2.0, 10.6, 10.7(EOL), 10.8(EOL), 10.9(EOL), 10.10(EOL), 10.11, 11.0(EOL), 11.1(EOL), 11.2(EOL)
Description
The issue with growing innodb_history_length (aka growing disk footprint of UNDO logs) that was originally reported in MDEV-29401 is still not solved for certain workloads.
Attachments
{kind=link}
Issue Links
- blocks
-
MDEV-16260 Scale the purge effort according to the workload
-

- Open
-
- causes
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
- relates to
-
-
- Open
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
MDEV-32573 Document UNDO logs still growing for write-intensive workloads
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Open
-
-
-
- Confirmed
-
-
-
- Open
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
- mentioned in
-
Page Loading...
Activity
| Field | Original Value | New Value |
|---|---|---|
| Link |
This issue relates to |
| Link |
This issue relates to |
| Summary | UNDO logs still growing for write-intesive workloads | UNDO logs still growing for write-intensive workloads |
| Link | This issue relates to PERF-411 [ PERF-411 ] |
| Affects Version/s | 11.2.0 [ 29033 ] | |
| Affects Version/s | 11.1.1 [ 28704 ] |
| Fix Version/s | 11.1 [ 28549 ] | |
| Fix Version/s | 11.2 [ 28603 ] |
| Assignee | Axel Schwenke [ axel ] | Marko Mäkelä [ marko ] |
I tested workload TPC-C (sysbench tpcc) for recent versions of MariaDB and with 3 different settings specific for limiting the UNDO log size.
configuration variants:
- no specific UNDO settings
- innodb_max_purge_lag = 500000, innodb_max_purge_lag_delay = 5000
- innodb_undo_log_truncate = ON
throughput goes down when UNDO log growth is limited
| variant | mariadb-10.11 | mariadb-11.1.1 | mariadb-11.1.2 |
|---|---|---|---|
| 1 | 4651.4 | 4441.2 | 4595.4 |
| 2 | 4183.4 | 4058.4 | 4187.0 |
| 3 | 3749.1 | 3896.7 | 3720.1 |
total size of UNDO logs after the benchmark run (MB)
| variant | mariadb-10.11 | mariadb-11.1.1 | mariadb-11.1.2 |
|---|---|---|---|
| 1 | 12403 | 12235 | 11339 |
| 2 | 4743 | 6659 | 4327 |
| 3 | 32 | 33 | 33 |
MariaDB 10.11 was commit 725bd568346 with the madvise patch applied (MDEV-31953).
So the customer has the choice between bad performance and growing UNDO logs.
| Description | The issue with growing innodb_history_length (aka growing disk footprint of UNDO logs) that was originally reported in |
| Description | The issue with growing innodb_history_length (aka growing disk footprint of UNDO logs) that was originally reported in |
The issue with growing innodb_history_length (aka growing disk footprint of UNDO logs) that was originally reported in |
I think that the logic that was introduced in MDEV-26356 may require closer examination.
| Link |
This issue relates to |
wlad pointed out that the history list length is not shrinking after a server bootstrap. thiru suggested a simple mtr test to reproduce this, which I wrote as follows:
--source include/have_innodb.inc
|
SHOW GLOBAL STATUS LIKE 'Innodb_history_list_length'; |
On 10.5, this would show 12 to me right after bootstrap. On 10.6, I see 7, thanks to MDEV-22343 and simplification of DDL operations (MDEV-25506 and friends). After my first and incorrect attempted fix, the shutdown after bootstrap would shrink the history to 0.
I believe that the main motivation for the parameter innodb_purge_rseg_truncate_frequency is to avoid frequent calls to trx_purge_free_segment(). The rest of the operations done in trx_purge_truncate_rseg_history() should hopefully be less disruptive.
Edit: the attempted fix would introduce a resource leak similar to MDEV-31234. The history list length actually corresponds to the combined length of the TRX_RSEG_HISTORY lists. The patch would remove pages from that list and then fail to mark the pages as freed for reuse.
| Fix Version/s | 10.6 [ 24028 ] | |
| Fix Version/s | 10.10 [ 27530 ] | |
| Fix Version/s | 10.11 [ 27614 ] | |
| Fix Version/s | 11.0 [ 28320 ] | |
| Affects Version/s | 10.6 [ 24028 ] | |
| Affects Version/s | 10.7 [ 24805 ] | |
| Affects Version/s | 10.8 [ 26121 ] | |
| Affects Version/s | 10.9 [ 26905 ] | |
| Affects Version/s | 10.10 [ 27530 ] | |
| Affects Version/s | 10.11 [ 27614 ] | |
| Affects Version/s | 11.0 [ 28320 ] | |
| Affects Version/s | 11.1 [ 28549 ] | |
| Affects Version/s | 11.2 [ 28603 ] | |
| Labels | performance | |
| Priority | Major [ 3 ] | Critical [ 2 ] |
wlad correctly pointed out that srv_wake_purge_thread_if_not_active() may invoke useless wake-up of the purge coordinator task. Maybe, if we fix that, the performance penalty of setting innodb_purge_rseg_truncate_frequency=1 will be bearable. That would allow the history list to shrink as fast as possible, at the end of each purge batch.
I am working on a revised wake-up condition that would pass tests and result in good performance.
| Status | Open [ 1 ] | In Progress [ 3 ] |
I think that it could make sense to move the time-consuming trx_purge_truncate_rseg_history() to a separate task from the purge coordinator, so that the processed undo pages can be freed concurrently with the next purge batch. I also improved the wakeup.
This did not seem to help at all in a 256-connection, 60-second memory-bound oltp_update_index test (5×10000 rows, 100M buffer pool and log file). The throughput would gradually worsen in both cases.
Replacing the default innodb_purge_threads=4 with the maximum innodb_purge_threads=32 does not make any noticeable difference for this workload. Using the maximum innodb_purge_batch_size=5000 instead of the default 300 lowered the throughput earlier, but with that setting the throughput would not monotonically decrease during the workload.
I think that I must use offcputime from the BPF Compiler Collection to find the bottlenecks.
To get reasonable stack traces from offcputime (working around https://github.com/iovisor/bcc/issues/1234), I compiled libc++ and libstdc++ with -fno-omit-frame-pointer as follows:
libc++
Added to glibc-2.37/debian/sysdeps/amd64.mk the line
extra_cflags = -fno-omit-frame-pointer
|
and built with dpkg-buildpackage, copied the libc.so.6* somewhere from the build directory while the tests were running
libstdc++
mkdir build
|
cd build
|
../gcc-13.2.0/libstdc++-v3/configure CXXFLAGS='-fno-omit-frame-pointer' CFLAGS='-fno-omit-frame-pointer' --disable-multilib --disable-libstdcxx-dual-abi --with-default-libstdcxx-abi=new --disable-libstdcxx-pch --without-libstdcxx-zoneinfo
|
make -j$(nproc)
|
cp -a src/.libs/libstdc++.so* ../some_safe_place
|
With LD_LIBRARY_PATH pointing to these self-built libc and libstdc++, I executed the workload script and concurrently
sudo offcputime-bpfcc --stack-storage-size=1048576 -df -p $(pgrep -nx mariadbd) 30 > out.stacks
|
flamegraph.pl --color=io --title="Off-CPU Time Flame Graph" --countname=us < out.stacks > out.svg
|
to record stacks for 30 seconds (which was shorter than my workload). In my first run, I am seeing a wait for rseg->latch in trx_undo_assign_low() (during an UPDATE statement, allocating the first undo log) as well as in trx_t::write_serialisation_history(). There are only 128 rollback segments, and I was using 256 concurrent transactions.
This run was with 32 tables of 10000 rows each. I was actually hoping that unlike the previous runs using 5 tables, this would have shown an improvement when increasing the default innodb_purge_threads=5 to innodb_purge_threads=32, but that was not the case.
I think that I must test with fewer concurrent connections to see where the other bottlenecks are. Adding more than 128 rollback segments would require significant changes to the file format.
| Attachment | purge-bottleneck-5-10000-128-40s-50s.svg [ 72068 ] |
I made another oltp_update_index test, with 5×10000 rows, 100MiB buffer pool and log file, but only 128 concurrent connections. I recorded 10 seconds of offcputime starting at around 40 seconds when the throughput starts to drop. In the flame graph, I observe 63% of waits in ha_innobase::update_row(). 10% is due to trx_undo_report_row_operation() (waiting for rseg->latch, an undo page latch, or the system tablespace latch), and 51% is due to row_upd_sec_index_entry(), mostly waiting for page latches in btr_cur_t::search_leaf(). Until MDEV-17598 has been implemented, MVCC and lock checks for secondary indexes will suffer heavily from purge lag; MDEV-20301 only helped a little.
I repeated the test with innodb_undo_tablespaces=32 instead of the 10.6 default innodb_undo_tablespaces=0. This alleviates the bottleneck on the system tablespace latch that can be seen in purge-bottleneck-5-10000-128-40s-50s.svg![]() for trx_undo_seg_create(), but the impact is only some 0.5% of waits.
for trx_undo_seg_create(), but the impact is only some 0.5% of waits.
The impact of the purge lag is heavily amplified when using a small buffer pool. After I increased the buffer pool and log to 1GiB, the throughput remained unchanged, even though most history was accumulated until the end of the test. Purging the history took 27 seconds (about 1/3 of the time that it took when using 10% of that buffer pool size with the same workload).
It could make sense to monitor the waits during a slow shutdown when the history is being purged, maybe using a small buffer pool. That should highlight the bottlenecks in the purge subsystem itself.
According to offcputime, during the slow shutdown, most threads are idle. When using a small buffer pool, I see some io_uring threads; with a larger buffer pool they disappear. The waits in purge are a small fraction of the total waits, and those are dominated by the secondary index checks (to be fixed by MDEV-17598).
I also checked top during the workload and shutdown. During the workload with 128 concurrent client connections, I got about 3300% CPU usage (33 cores used). During the slow shutdown, that dropped to 100%. For some reason, the purge coordinator appears to be doing all work by itself here. This could be the key. The next step could be to add some diagnostic messages to the purge worker callback, to confirm if this really is the case.
I repeated the oltp_update_index benchmark with 32×1560 rows, innodb_undo_tablespaces=32 and 32 concurrent connections for 60 seconds. I used a 4GiB buffer pool to avoid any page I/O, and I ran it on RAM disk. In this benchmark, the purge_coordinator_callback will spend 5/6 of its waiting time in TrxUndoRsegsIterator::set_next(), waiting for purge_sys->rseg.latch. Under this workload, the following patch made almost no difference.
diff --git a/storage/innobase/trx/trx0purge.cc b/storage/innobase/trx/trx0purge.cc
|
index ad92ebff7b6..72c74c39bbf 100644
|
--- a/storage/innobase/trx/trx0purge.cc
|
+++ b/storage/innobase/trx/trx0purge.cc
|
@@ -108,20 +108,13 @@ TRANSACTIONAL_INLINE inline bool TrxUndoRsegsIterator::set_next()
|
|
trx_id_t last_trx_no;
|
{
|
-#ifdef SUX_LOCK_GENERIC
|
- purge_sys.rseg->latch.rd_lock(SRW_LOCK_CALL);
|
-#else
|
- transactional_shared_lock_guard<srw_spin_lock> rg
|
- {purge_sys.rseg->latch};
|
-#endif
|
+ purge_sys.rseg->latch.wr_lock(SRW_LOCK_CALL);
|
last_trx_no = purge_sys.rseg->last_trx_no();
|
|
purge_sys.hdr_offset = purge_sys.rseg->last_offset();
|
purge_sys.hdr_page_no = purge_sys.rseg->last_page_no;
|
|
-#ifdef SUX_LOCK_GENERIC
|
- purge_sys.rseg->latch.rd_unlock();
|
-#endif
|
+ purge_sys.rseg->latch.wr_unlock();
|
}
|
|
/* Only the purge_coordinator_task will access this object |
I was expecting that this could slow down the transaction start and commit, but the throughput in fact remained almost unchanged. There was slightly less history to purge at the end of the 60-second test. This synchronization primitive used to be a mutex, until MDEV-25062 changed it, as well as removed some latch acquisition from DML code paths.
I am trying to refactor purge_coordinator_callback so that it will continuously hold an exclusive purge_sys.rseg->latch for a little longer time, basically across one call of trx_purge_fetch_next_rec(), that is, choosing the next undo log record to process. That would hopefully reduce the waits in the purge coordinator as well as act as a natural throttle for the producers (transaction start or commit in DML operations).
My initial refactoring to acquire and release purge_sys.rseg->latch less often improved things a tiny bit in my benchmark. trx_purge() would now account for 2.58% of all waits, instead of previous 3.0%, and the majority (2.04%) would be due to trx_purge_choose_next_log().
It could make sense to keep holding purge_sys.rseg->latch for several consecutive parsed undo log records, or until a different purge_sys.rseg is chosen. To reduce the impact on DML, we might make transaction start avoid the rollback segment that the purge coordinator task is currently working on.
I ran a benchmark of commit ac29a54908e (HEAD of bb-10.6-MDEV-32050) vs. commit 52e7016248d (HEAD~3, baseline). Workload was TPC-C, 32 threads, 1 hr runtime. Results:
32 thd, innodb_purge_threads=4 (default)
| metric | 52e7016248d (baseline) | ac29a54908e ( |
|---|---|---|
| throughput (qps) | 4591.5 | 4533.4 |
| UNDO logs after load | 1619 | 1003 |
| UNDO logs after run | 11335 | 1003 |
32 thd, innodb_purge_threads=32
| metric | 52e7016248d (baseline) | ac29a54908e ( |
|---|---|---|
| throughput (qps) | 4450.9 | 4554.3 |
| UNDO logs after load | 1623 | 883 |
| UNDO logs after run | 8763 | 883 |
Observations:
- while the UNDO logs were growing during loading of the data set, they did not grow during the one hour runtime for
MDEV-32050 - also the initial growth (during load) is lower with
MDEV-32050 - both the initial growth and the runtime growth were lower with innodb_purge_threads=32 (that was expected)
- but innodb_purge_threads=32 did not affect throughput much
The encouraging results made me repeat the benchmark with 64 threads:
64 thd, innodb_purge_threads=4 (default)
| metric | 52e7016248d (baseline) | ac29a54908e ( |
|---|---|---|
| throughput (qps) | 5598.8 | 5530.3 |
| UNDO logs after load | 1623 | 971 |
| UNDO logs after run | 18915 | 1335 |
64 thd, innodb_purge_threads=32
| metric | 52e7016248d (baseline) | ac29a54908e ( |
|---|---|---|
| throughput (qps) | 5555.5 | 5546.2 |
| UNDO logs after load | 1619 | 935 |
| UNDO logs after run | 18927 | 1659 |
The results are not as good as before, we had some UNDO log growth during the run. But the growth of the UNDO logs was much smaller for MDEV-32050.
The fact that the innodb_purge_threads setting does not affect throughput but results in smaller UNDO logs, is worth noting. We should give that tuning advise to customers. And maybe raise the default (make it relative to nproc?)
| Link |
This issue relates to |
axel, thank you, this is very promising. Today, I diagnosed the reason why a shutdown with innodb_fast_shutdown=0 quickly degrades to employing no purge_worker_task. At the start of the shutdown, the loop in purge_coordinator_state::do_purge() would invoke trx_purge() with 32 threads, then 31, 30, …, 1, and then keep using 1 thread until the very end. I made an experiment to revert the throttling logic that had been added in MDEV-26356. I am hoping that the changes in this branch or some earlier changes (such as MDEV-26055 and MDEV-26827) provide an alternative fix to the problem that was reported as MDEV-26356.
I see that one of my test scenarios in MDEV-26356 was to use slow storage, too high innodb_io_capacity, and small innodb_log_file_size and possibly innodb_buffer_pool_size. I did not test that yet.
I posted some results from my experiment to MDEV-26356. I think that it is a misconfigured setup: too high innodb_io_capacity and tiny innodb_log_file_size to force frequent checkpoint flushing. The log was overwritten more than 7 times during the 1 hour the server was running. I hope that this experiment will fare well in axel’s testing.
The oltp_update_non_index benchmark in MDEV-26356 highlighted another potential bottleneck: table lookup. I did not check offcputime of that yet, but the slow shutdown only employed 1.7 CPU cores.
In a modified variant of the MDEV-26356 test case, I can reproduce <200% CPU usage in purge on the slow shutdown, in a CPU-bound oltp_update_non_index running on RAM disk:
| parameter | value |
|---|---|
| tables | 100 |
| table_size | 150 |
| innodb_buffer_pool_size | 500M |
| innodb_log_file_size | 500M |
| threads | 512 |
| time | 5 |
Here are some figures after a 5-second workload using 16,000 rows (starting with 128 tables×250 rows/table) and the default innodb_purge_threads=4:
| tables | transactions | history list length | slow shutdown time/s |
|---|---|---|---|
| 128 | 995070 | 887199 | 12 |
| 64 | 969956 | 893821 | 9 |
| 32 | 936214 | 833270 | 4 |
| 16 | 925928 | 767956 | 2 |
| 8 | 915764 | 857336 | 3 |
| 4 | 875552 | 637400 | 2 |
Based on perf record analysis, I suspect that the bottleneck are the waits for dict_sys.latch in a table ID lookup. Maybe each purge task should maintain a larger local cache that maps table ID to table pointers. Eviction of those tables from dict_sys would be prevented by dict_table_t reference counters.
A possible enhancement could be that in trx_purge_attach_undo_recs(), which is run by purge_coordinator_task, we would look up the tables. We already associate each unique table_id with a purge worker there:
std::unordered_map<table_id_t, purge_node_t*> table_id_map;
|
…
|
table_id_t table_id = trx_undo_rec_get_table_id(
|
purge_rec.undo_rec);
|
|
|
purge_node_t *& table_node = table_id_map[table_id];
|
|
|
if (table_node) { |
…
|
} else { |
…
|
}
|
|
|
node->undo_recs.push(purge_rec);
|
If only the purge_coordinator_task looks up the tables, there will be no “unhealthy competition” with purge workers. Also, if a table has been dropped, the purge coordinator will be able to immediately discard any undo log records, without adding them to node->undo_recs. We could add another lookup table to purge_node_t and perform the table lookup in the else branch above. At the end of the purge batch, the purge coordinator would go through the lookup tables and release the table references.
I implemented a crude prototype of the idea. This improved the slow shutdown time after a 5-second run of my MDEV-26356 test case. Before the fix, slow shutdown would occupy 2 threads and take 14 seconds. After it, slow shutdown would at least for some time occupy more than 11 threads and finish in 4 seconds.
Some problems related to DDL will need to be addressed:
- Any waits related to processing SYS_INDEXES records (the crash recovery of operations like DROP INDEX or DROP TABLE) must not take place until all MDL have been released at the end of the batch.
- If a table lookup temporarily fails (a metadata lock cannot be granted immediately), the lookup and processing must be retried after all MDL have been released.
It looks like I was able to remove the copying of undo log records in rollback, online ALTER TABLE and purge. I think that it is needed (or is simplest to retain) the copying in MVCC reads.
I noticed some repeated buf_pool.page_hash lookups in purge. It could be worthwhile to save more references to buffer-fixed undo pages while a purge batch is active, or maybe even to construct a local hash table from page identifiers to buffer-fixed pages.
The DDL related problems have not been addressed yet.
It looks like I may have sorted out the trouble with DDL operations, at least when it comes to the regression test suite, but something is still causing hangs with some tests on indexed virtual columns.
I think that adding a cache for buf_pool.page_hash could be a possible future enhancement.
Thanks to some help from nikitamalyavin and wlad, I think that this now is ready for some performance and stress tests.
| Link | This issue blocks MDEV-16260 [ MDEV-16260 ] |
I got terrible performance yesterday. In response, I implemented the cache for buf_pool.page_hash lookup. In this way, only the purge_coordinator_task will buffer-fix and buffer-unfix undo log pages. That alone did not help much, but a larger innodb_purge_batch_size did. This will give the purge threads a chance to run for a longer time per batch, reducing the setup time.
I think that we need to consider enlarging the maximum value of innodb_purge_batch_size and increasing the default from 300 to 1000. Partly this could be due to a different accounting: the new page cache would count each and every accessed undo page, while the old code only counted some of them. The batch size is a simple limit of undo pages that may be processed during a batch.
Is there (or will there be) a GLOBAL STATUS that hints at whether `innodb_purge_batch_size` is too small or too large?
| Status | In Progress [ 3 ] | In Testing [ 10301 ] |
| Assignee | Marko Mäkelä [ marko ] | Matthias Leich [ mleich ] |
rjasdfiii, we can’t easily determine the ideal size of each batch, but we might count the number of times when innodb_purge_batch_size is the limiting factor. Provided that purge_sys.view is advancing at a steady rate (there are no long-running transactions or old read views active), the growth rate of such a counter would be a hint that increasing the innodb_purge_batch_size might help.
@MarkoMakela - Thanks for the comment. I spend a lot of time helping others with problems. But I don't know all the internal details. When there is a [[VARIABLE]] that looks tempting to tune, I am often at a loss of how to measure whether to, and how much to, raise or lower it. Some variables even have multiple hints ([[buffer_pool]], [[table_open_cache]]) to simplify the task.
bb-10.6-MDEV-32050-rerebase performed well in RQG testing.
|
Regarding the annoying amount of cases (~ 0.7% of all test runs) where RQG claims to have met a server hang:
|
A comparison to
|
origin/10.6 bf7c6fc20b01fa34a15aa8cb86d33bf08c03ca6f 2023-10-18T16:33:11+03:00
|
origin/10.6 88dd50b80ad9624d05b72751fd6e4a2cfdb6a3fe 2023-08-16T10:02:18+04:00
|
showed that bb-10.6-MDEV-32050-rerebase has ~ 20% less cases where RQG claims to
|
met a server hang.
|
Please be aware that the DB server hang detection in RQG is a bit imperfect.
|
There is some fraction of false alarms.
|
| Assignee | Matthias Leich [ mleich ] | Marko Mäkelä [ marko ] |
| Status | In Testing [ 10301 ] | Stalled [ 10000 ] |
| Status | Stalled [ 10000 ] | In Testing [ 10301 ] |
This was approved by wlad and vlad.lesin and is now waiting for a final performance test, to see if increasing the default value of innodb_purge_batch_size from 300 to 1000 would be reasonable.
| Assignee | Marko Mäkelä [ marko ] | Axel Schwenke [ axel ] |
Based on the tests by axel, we will also change the default value of innodb_purge_batch_size from 300 undo log pages to 1000.
| issue.field.resolutiondate | 2023-10-25 08:22:08.0 | 2023-10-25 08:22:08.354 |
| Fix Version/s | 10.6.16 [ 29014 ] | |
| Fix Version/s | 10.10.7 [ 29018 ] | |
| Fix Version/s | 10.11.6 [ 29020 ] | |
| Fix Version/s | 11.0.4 [ 29021 ] | |
| Fix Version/s | 11.1.3 [ 29023 ] | |
| Fix Version/s | 11.2.2 [ 29035 ] | |
| Fix Version/s | 10.6 [ 24028 ] | |
| Fix Version/s | 10.10 [ 27530 ] | |
| Fix Version/s | 10.11 [ 27614 ] | |
| Fix Version/s | 11.0 [ 28320 ] | |
| Fix Version/s | 11.1 [ 28549 ] | |
| Fix Version/s | 11.2 [ 28603 ] | |
| Assignee | Axel Schwenke [ axel ] | Marko Mäkelä [ marko ] |
| Resolution | Fixed [ 1 ] | |
| Status | In Testing [ 10301 ] | Closed [ 6 ] |
| Link |
This issue relates to |
| Link |
This issue relates to |
| Link |
This issue relates to |
| Link |
This issue causes |
Pretty excited about this one and the MDL race condition fix in 10.6.16. Letting it bake for a week or so before landing it on any production instance. I just upgraded from 10.5.13 to 10.6.15 on Monday. Performance went up already by almost a factor of 2 on the NVMe drives, but undo does not flush fast enough. Will check back in in a few weeks.
| Link |
This issue relates to |
TheWitness, I’m looking forward to your results. This was indeed long overdue. I think that the next big thing to reduce purge lag will be MDEV-17598, which will involve a file format change.
| Link | This issue relates to MDEV-17598 [ MDEV-17598 ] |
I'll keep you posted. They update is scheduled on 11/28. The other ticket also a big bit of work.
It looks like these changes increased the likelihood of some regression test failures. Hopefully after this fixup no such failures will occur.
| Link |
This issue relates to |
Marko,
I'm planning on upgrading tomorrow. With these regressions, do you think I should wait? I'll be pulling the latest 10.6.16 RPM's
Ope, just saw it's moved @ Enterprise level till 12/11. Waiting for two more weeks then ![]()
TheWitness, the fixups that I mentioned involve modifying some regression tests only, no code changes.
| Remote Link | This issue links to "Page (MariaDB Confluence)" [ 36306 ] |
| Link | This issue relates to MDEV-14602 [ MDEV-14602 ] |
| Link |
This issue relates to |
| Link |
This issue relates to |
MDEV-33112 and MDEV-33213 are further important improvements in this area.
@Marko Mäkelä, I just upgraded from 10.6.15 to 10.6.16-11 this morning. So far, the history is looking under control. I'm presently watching I/O levels and will track MariaDB's ability to keep it in check over the next few days. If we can keep it under 5M, that'll be good. I've got a few things disabled, that I will re-enable once we get good measurements with this specific components disabled.
TheWitness, the high level summary is that this change MDEV-32050 is speeding up the processing of undo log records in purge, while MDEV-33213 is fixing a starvation problem where rollback segments cannot be truncated or freed because of a constant stream of small new transactions that keep added to TRX_UNDO_CACHED pages. That is, the undo log records inside the rollback segments could already have been processed a long time ago, but we can’t free the pages.
As soon as MDEV-33213 has passed the review, I am happy to provide a custom build based on 10.6.16-11 if needed. With that and MDEV-33112 it might even be feasible to set innodb_undo_log_truncate=ON during a heavy write workload.
| Attachment | screenshot-1.png [ 72803 ] |
@Marko Mäkelä,
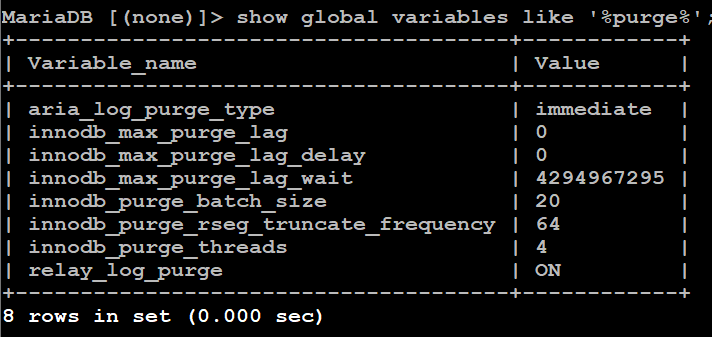
Yea, I need something as the undo log is growing pretty consistently unlike 10.6.15-9 where is was staying under 2M consistently. Here are my current purge settings if you want me to tune anything.
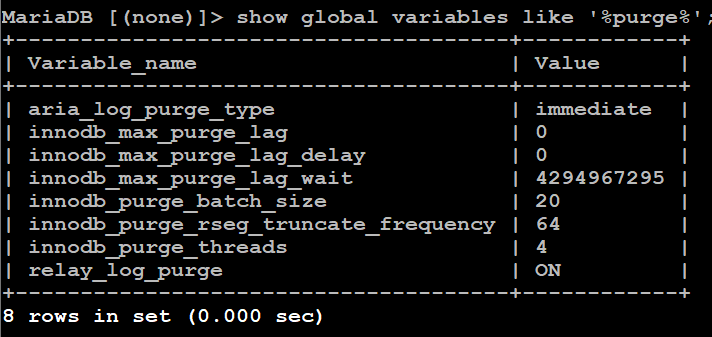
Let me know where to go to get the custom binary as I suspect it's going to grow over night.
Larry
| Attachment | screenshot-2.png [ 72804 ] |
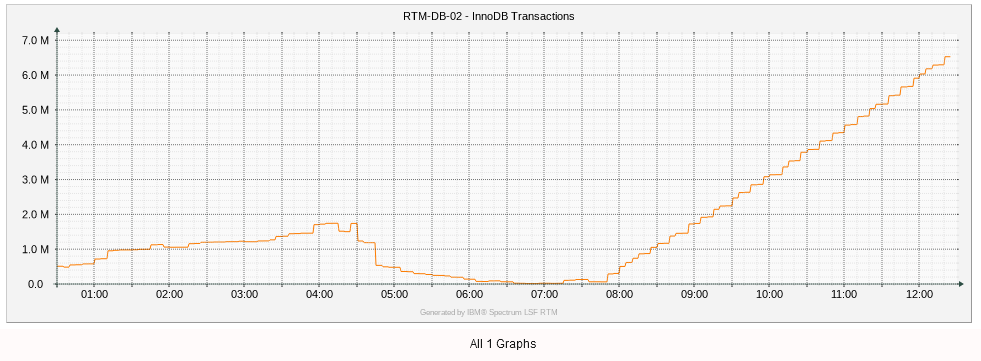
Here is the last 12 hours. You can see when I did the upgrade, it started increasing linearly as soon as I applied the patch.
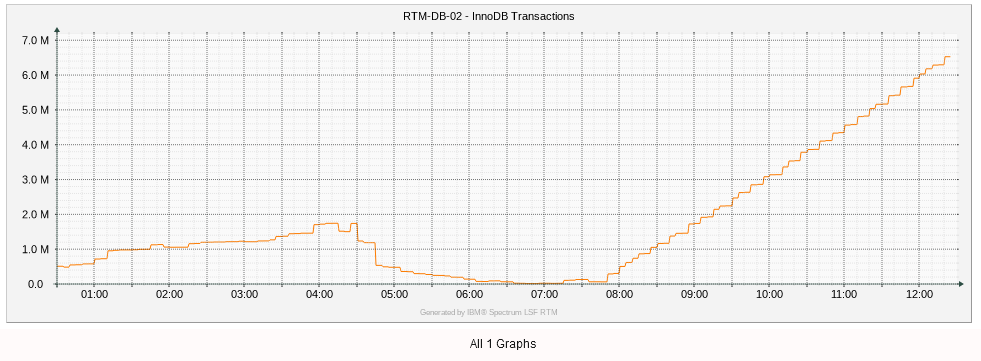
| Attachment | screenshot-3.png [ 72805 ] |
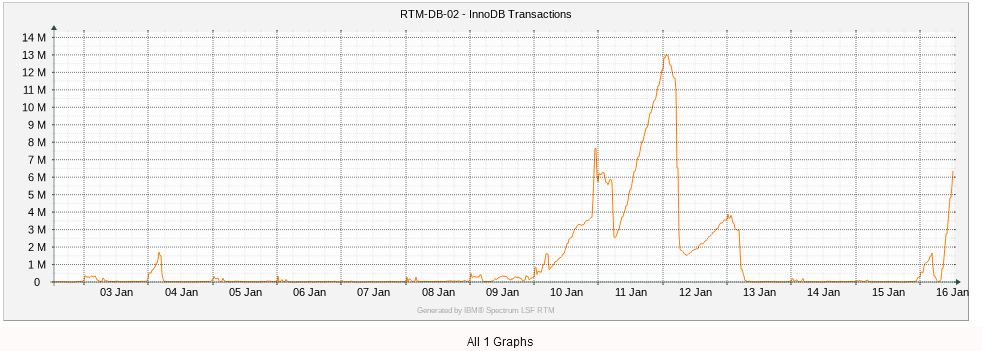
Last two weeks. You can see it's gone up before. Have to watch it over night.
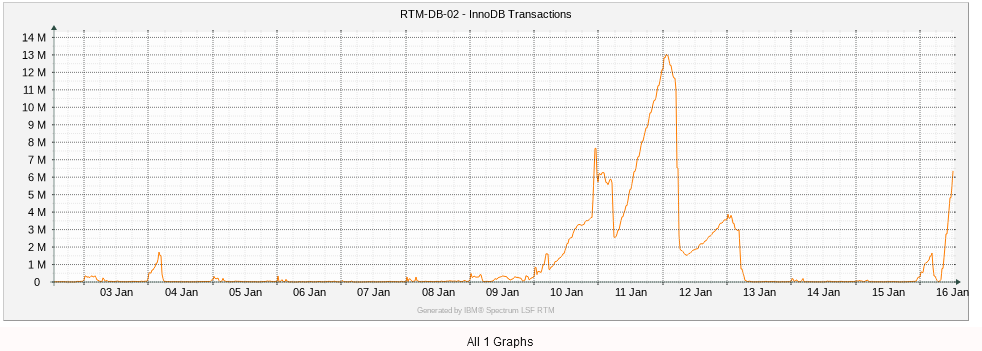
I was running some pretty long analytic queries last week when the undo log was going up. None today though.
I either need that patch, or need to roll back to 10.6.15. Let me know ASAP. Not sure what to download and from where. The history is up to over 35M this morning.
Larry
https://ci.mariadb.org/42505/ contains the packages for the 10.6 main branch for the fix of MDEV-33213.
Marko,
The RHEL8 RPM's are missing. Seems the only ones missing the RPM's. Can you get that fixed?
Larry
Take the next build, https://ci.mariadb.org/42507/
It has only has changes in test files, so the server is the same. The additional commit is:
commit 6a514ef6727
|
Author: Marko Mäkelä <marko.makela@mariadb.com>
|
Date: Wed Jan 17 12:50:44 2024 +0200
|
|
|
MDEV-30940: Try to fix the test
|
|
|
mysql-test/suite/innodb/r/lock_move_wait_lock_race.result | 3 ++-
|
mysql-test/suite/innodb/t/lock_move_wait_lock_race.test | 3 ++-
|
2 files changed, 4 insertions(+), 2 deletions(-)
|
Thanks Sergei,
I rolled back to 10.6.15-10 Enterprise last night. I'll wait on another signal from Marko before taking other actions. The history list length is slowly winding down towards zero again. It's not as aggressive as I would like, but at least going in the right direction now.
Larry
| Link | This issue causes MENT-2044 [ MENT-2044 ] |
| Link | This issue causes MENT-2044 [ MENT-2044 ] |
| Assignee | Marko Mäkelä [ marko ] | Valerii Kravchuk [ valerii ] |
| Assignee | Valerii Kravchuk [ valerii ] |
| Assignee | Marko Mäkelä [ marko ] |
| Link |
This issue relates to |
| Link |
This issue causes |
| Link |
This issue relates to |
| Link |
This issue relates to |
| Link |
This issue causes |
| Zendesk Related Tickets | 201658 108492 181007 130146 | |
| Zendesk active tickets | 201658 |
| Link | This issue relates to MDEV-18746 [ MDEV-18746 ] |
| Zendesk active tickets | 201658 | CS0000 201658 |
| Link | This issue relates to MDEV-35895 [ MDEV-35895 ] |
@axel said in slack to marko: