Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Fixed
-
10.6, 10.7(EOL)
Description
Users can configure the number of purge threads to use.
Currently, the existing logic looks at the increasing history length and accordingly increases the purge threads (respecting the user-set threshold). User active user workload causes history length to increase that, in turn, leads to more purge threads to get scheduled.
Purge operation generates redo-records in addition to user workload redo-records. This dual redo generations cause intense pressure on redo-log which can easily cause redo-log to hit the threshold and there-by-causing jitter in overall throughput (including furious flushing).
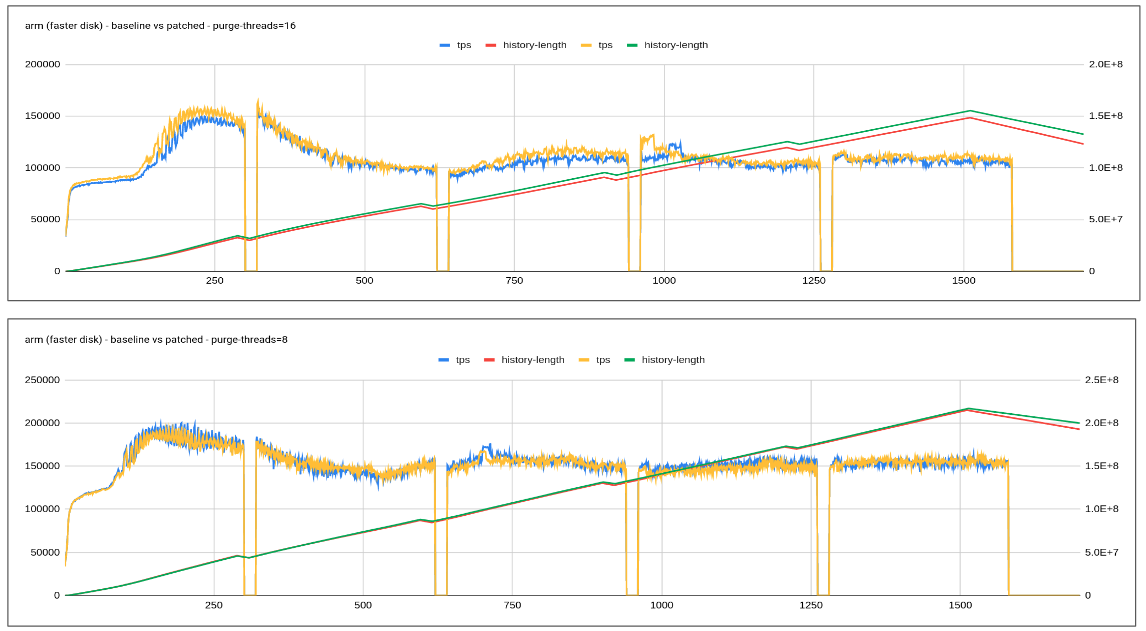
In order to improve the user workload performance and it is important to ensure background activity like a purge is not overdone while ensuring history length is kept in check to avoid an increase in select latency.
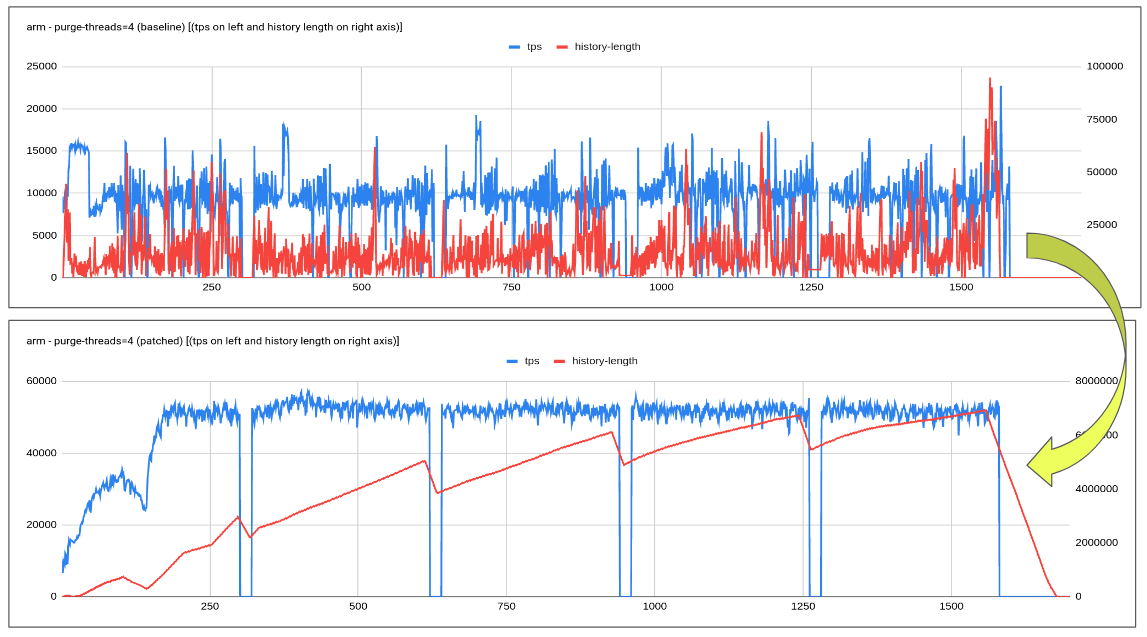
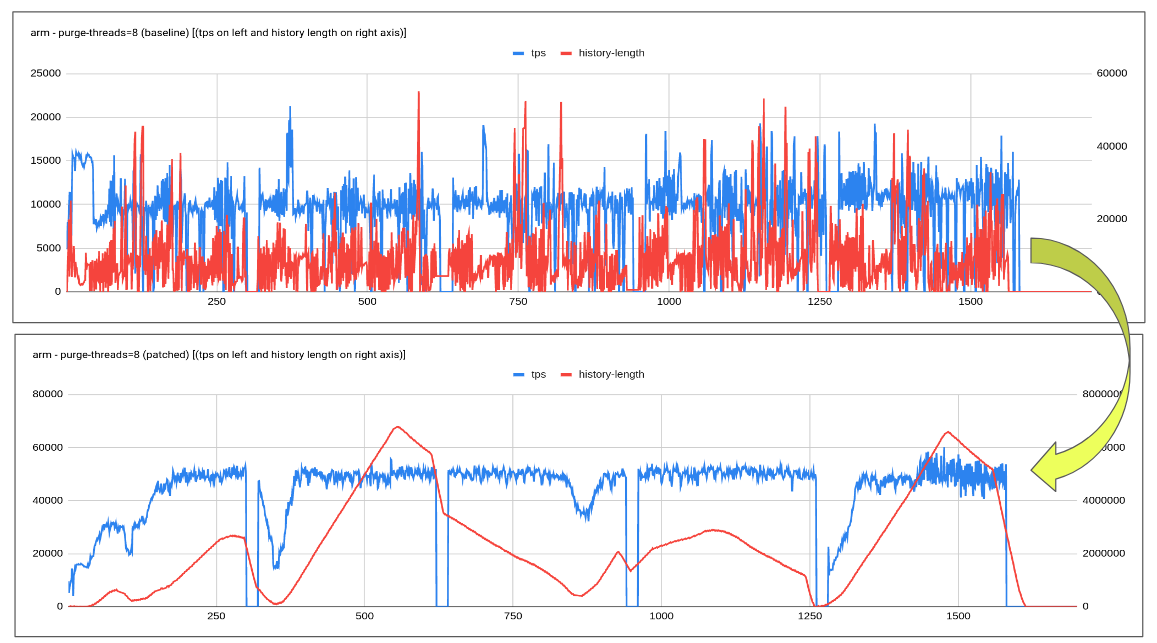
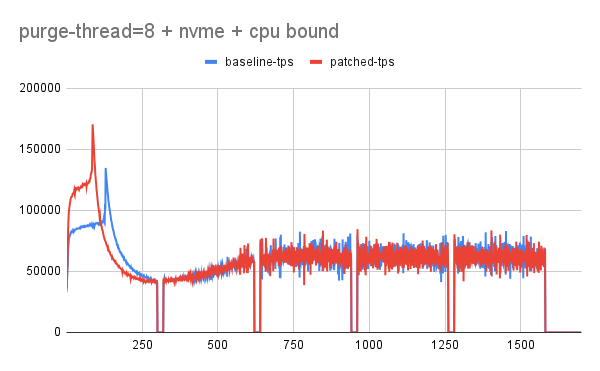
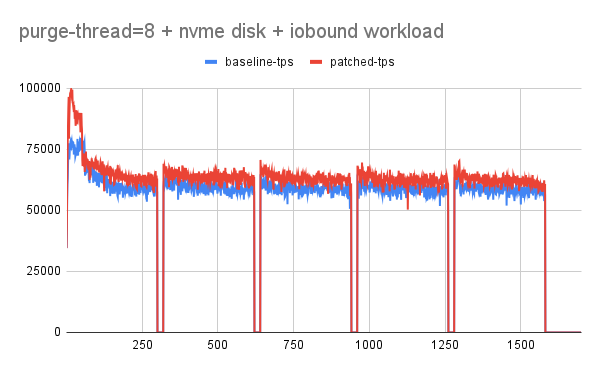
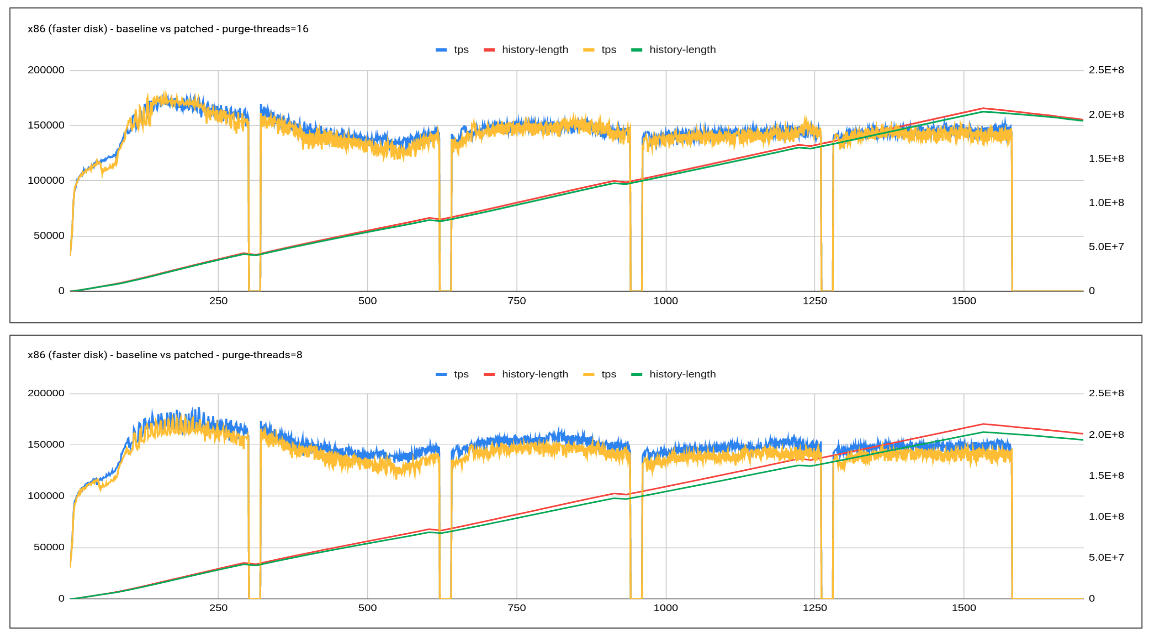
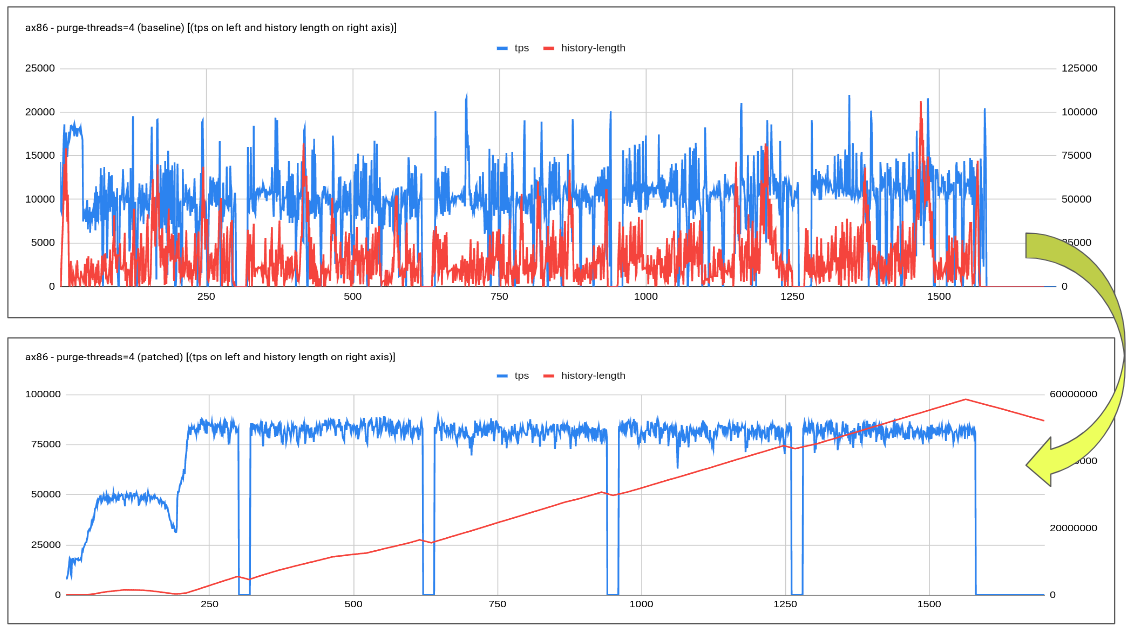
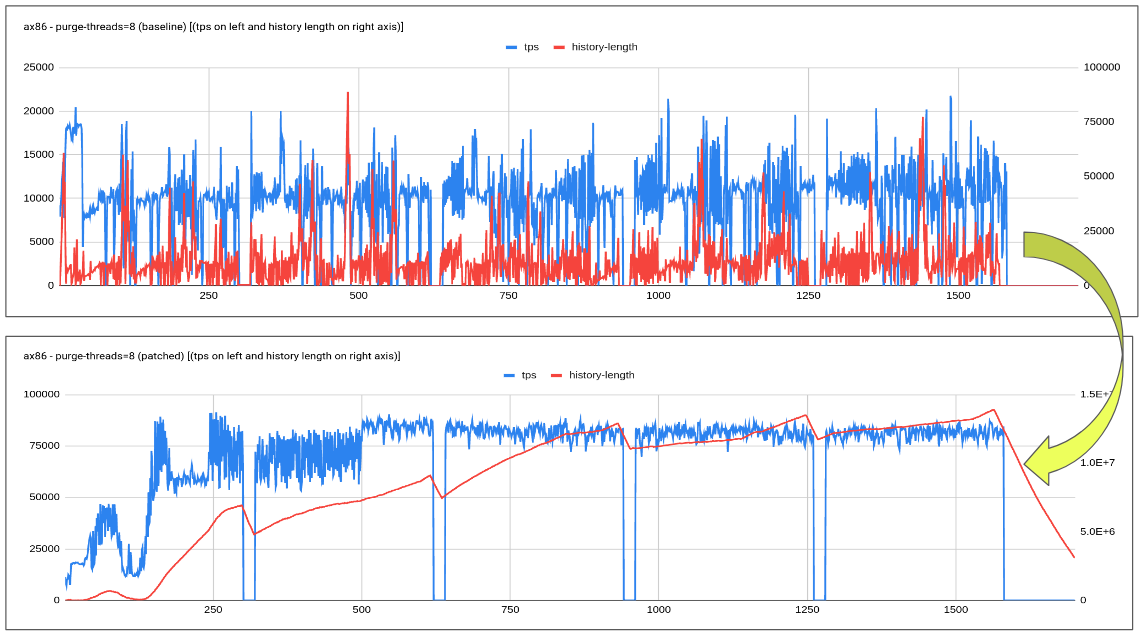
The proposed patch explores an adaptive purge thread scheduling approach based on the redo log fill factor. Logic tends to dynamically increase or decrease the purge threads based on how much redo log is filled, leaving enough space/resources/flush bandwidth for the user workload.
Testing done so far has revealed quite encouraging results especially with slower disk where-in flush is unable to catch up with redo log generation rate. Increasing in history length doesn't tend to have a regressing effect on the queries.
Attachments
Issue Links
- causes
-
-

- Confirmed
-
- is blocked by
-
-
- Closed
-
- relates to
-
MDEV-21751 innodb_fast_shutdown=0 can be unnecessarily slow
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
MDEV-16260 Scale the purge effort according to the workload
-
- Open
-
-
-
- Closed
-
-
-
- Closed
-
