Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
10.5
Description
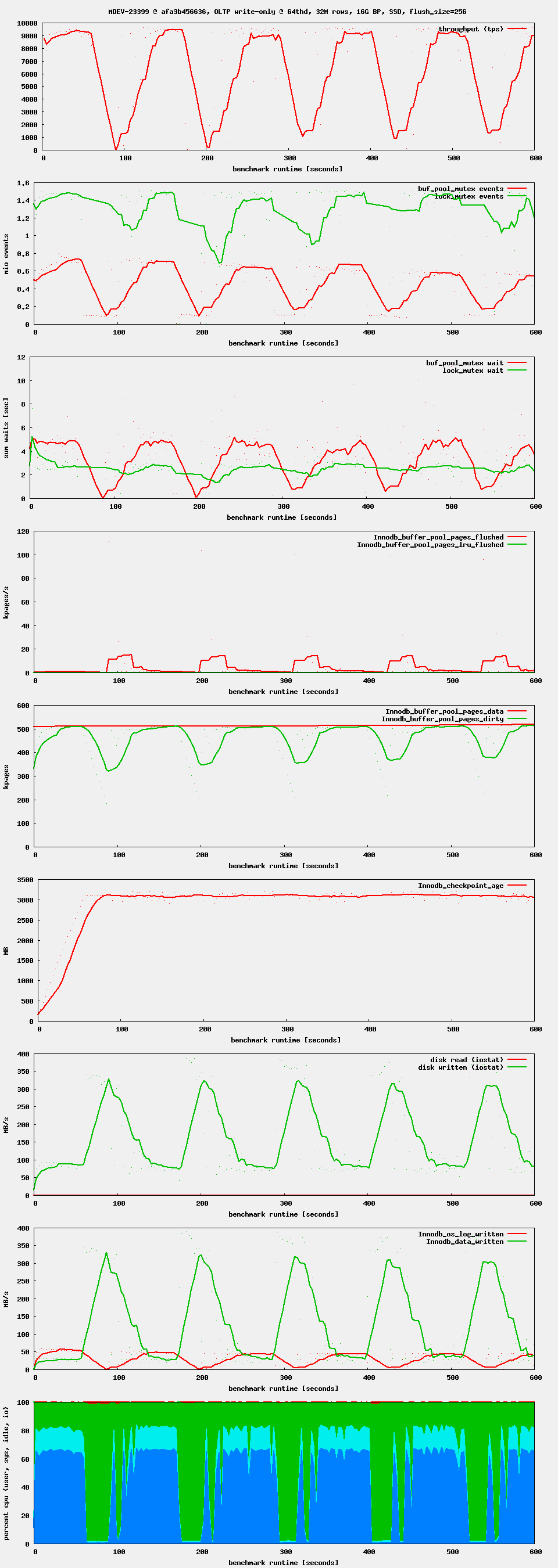
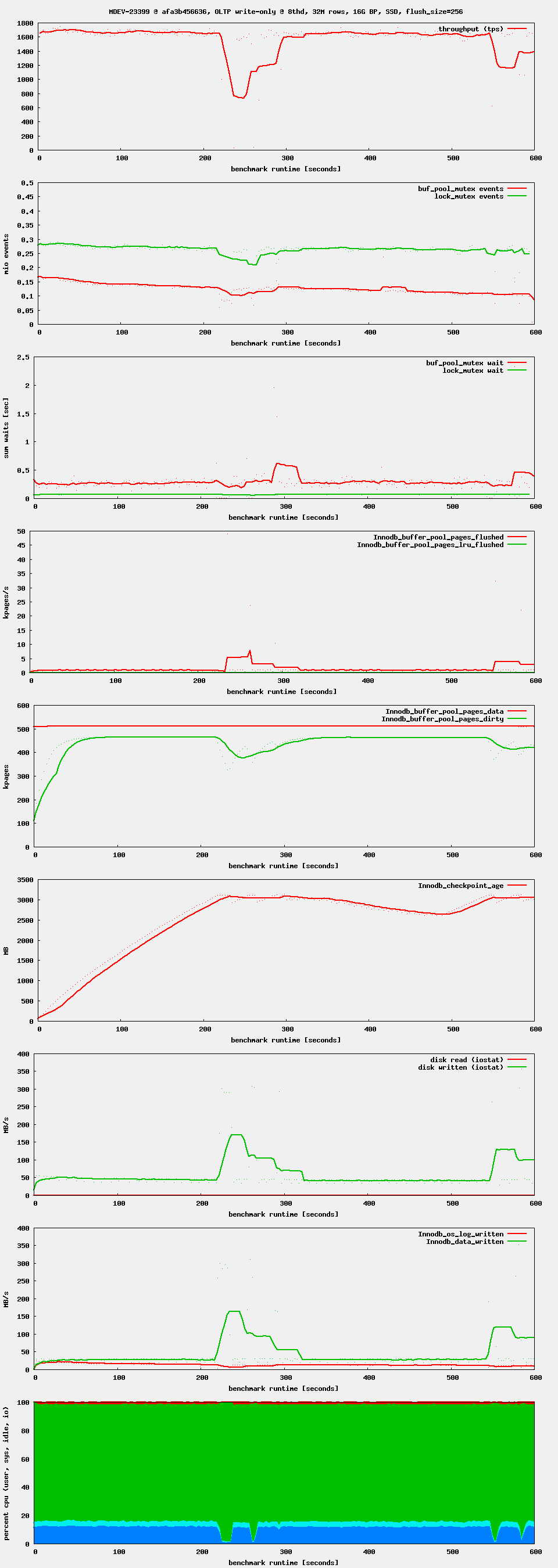
Workload: sysbench OLTP write-only, i.e. as it is used by the regression benchmark suite in t_writes_innodb_multi.
Setup: 16G buffer pool. 4G redo log. 4G or 8G data set. innodb_flush_neighbors = 0, innodb_io_capacity = 1000 (or 5000, 10000)
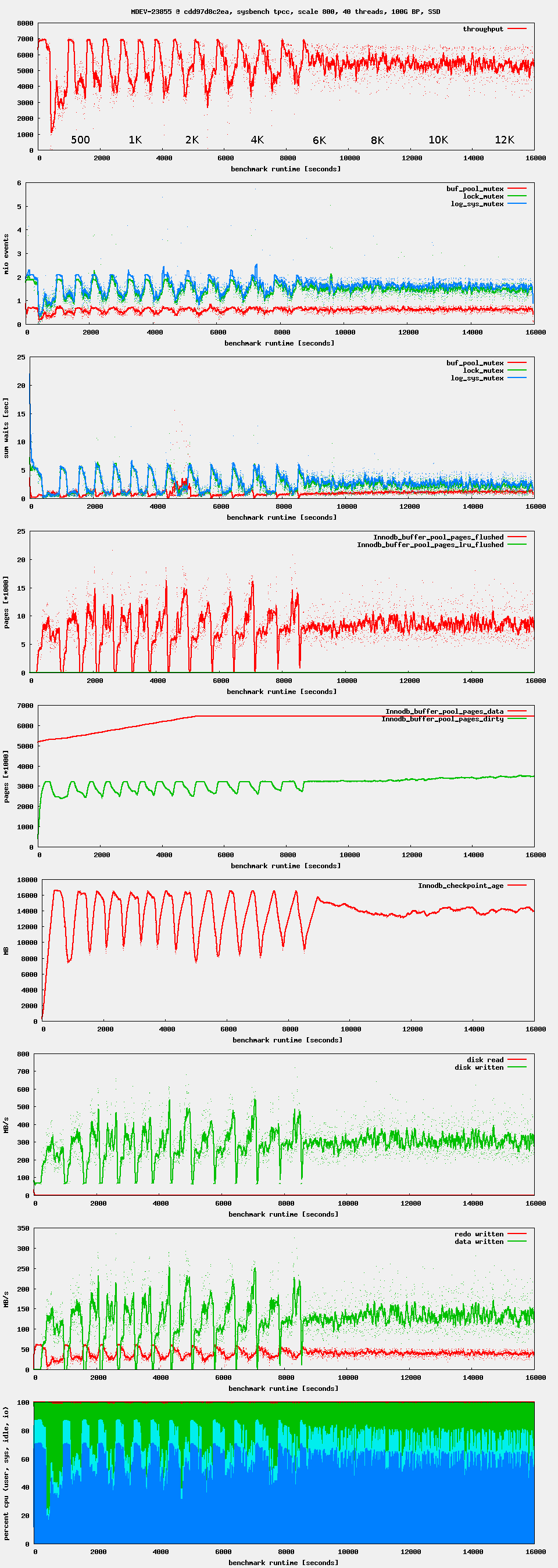
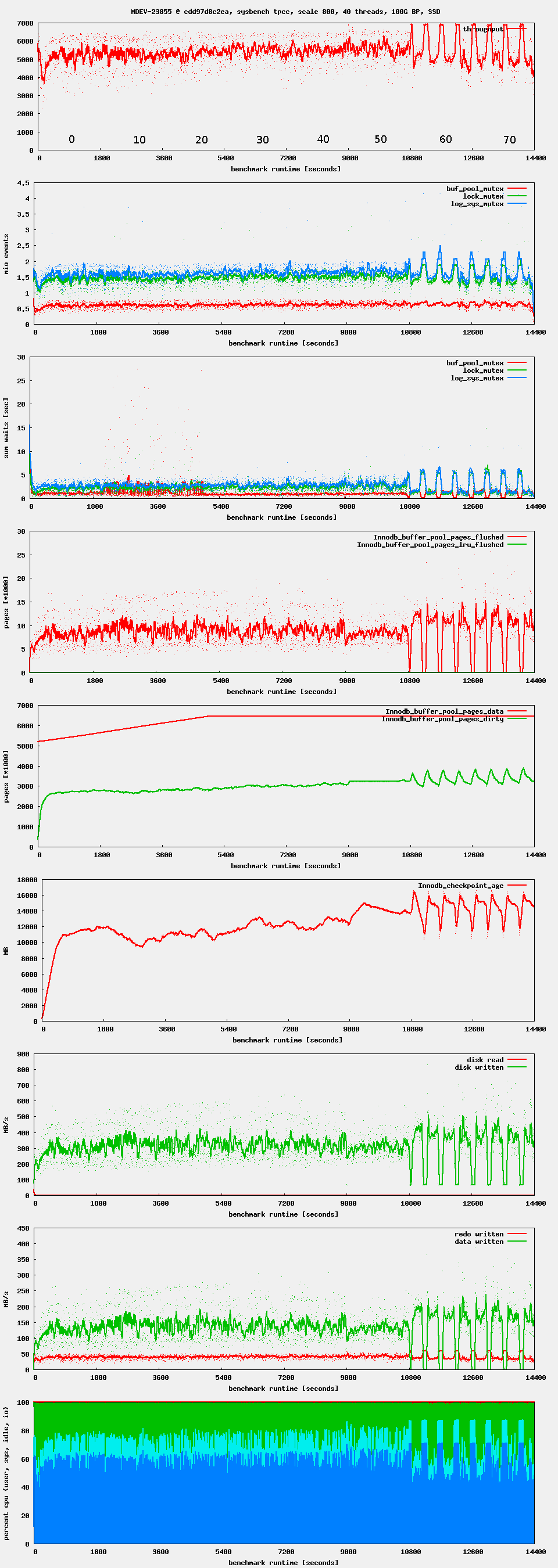
Observation: after starting high, performance drops after ~ 1 minute. If waiting long enough, one can see oscillations in throughput. This seems to be related to Innodb_checkpoint_age reaching Innodb_checkpoint_max_age. There seems to be no LRU flushing at all, only flush_list flushing.
Attachments

Issue Links
- blocks
-
MDEV-11659 Move the InnoDB doublewrite buffer to flat files
-
- Open
-
-
-
- Open
-
-
-
- Closed
-
- causes
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
- is blocked by
-
-
- Closed
-
-
-
- Closed
-
- relates to
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Confirmed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
Activity
| Field | Original Value | New Value |
|---|---|---|
| Link |
This issue is caused by |
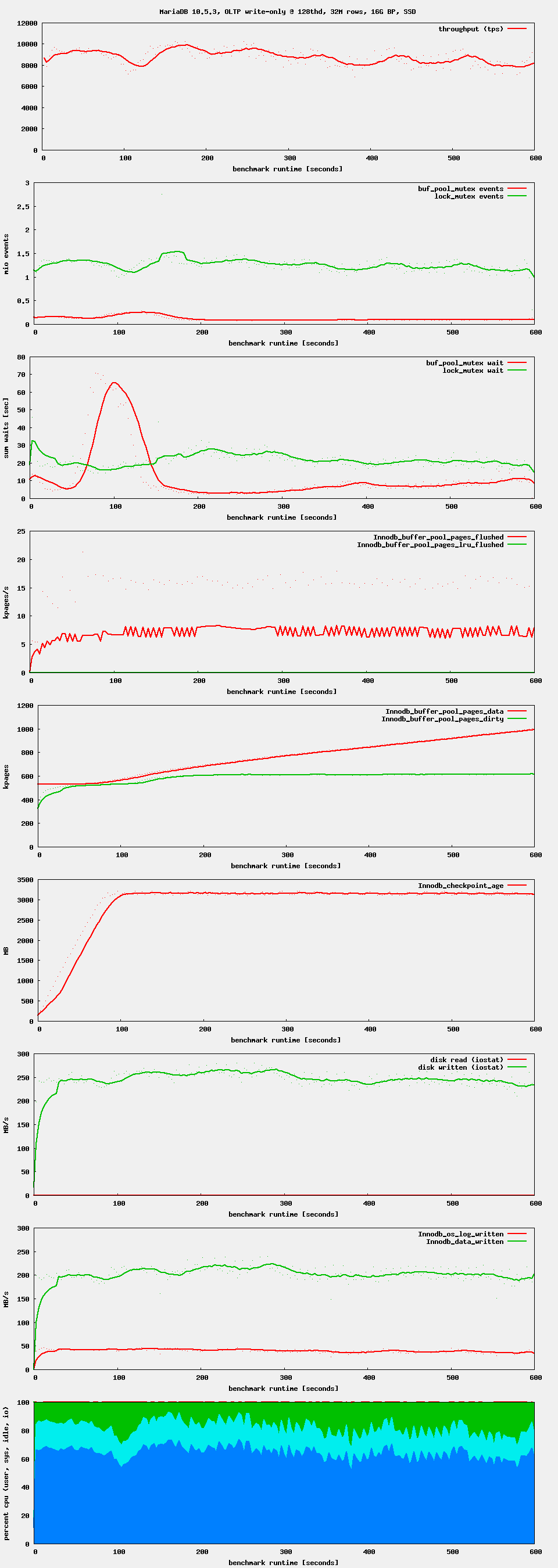
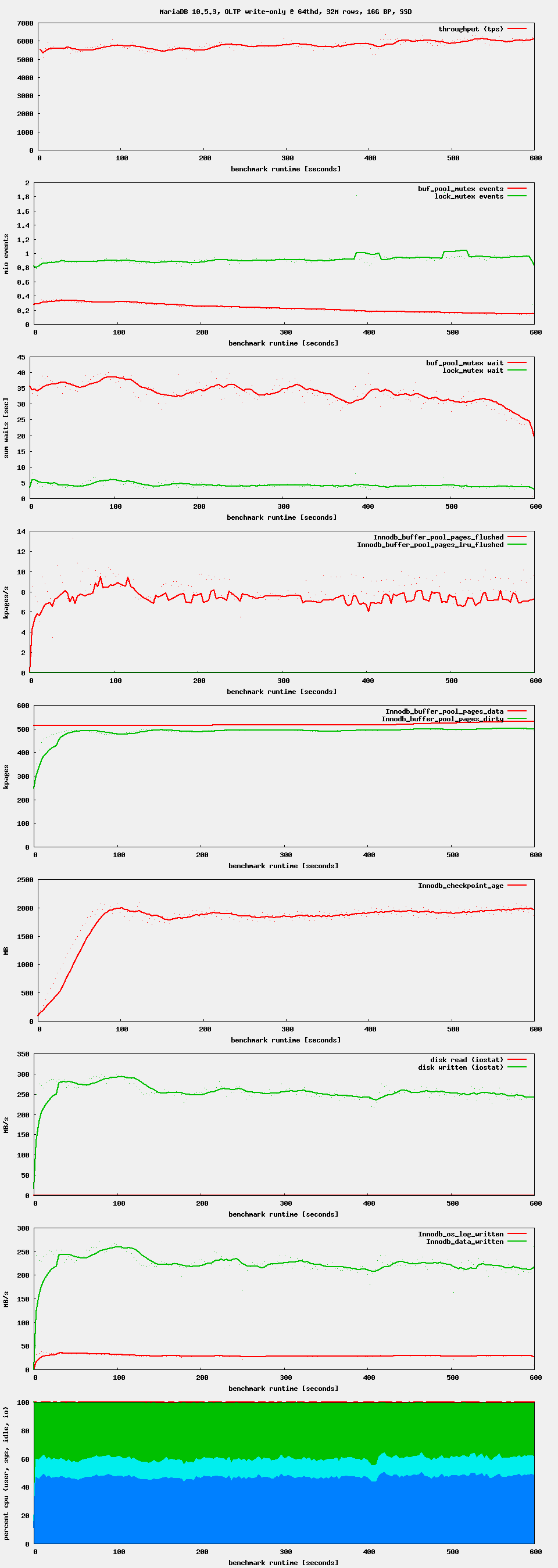
| Attachment | oltp_ts_64.png [ 54065 ] | |
| Attachment | oltp_ts_128.png [ 54066 ] | |
| Attachment | oltp_ts_256.png [ 54067 ] |
@Axel, what is t_writes_innodb_multi ? Is there a sysbench description of it (I guess my.cnf can be derived from description)
Steps to reproduce
Start MariaDB server with this my.cnf
[mysqld]
|
innodb_buffer_pool_size = 16G
|
innodb_log_file_size = 4G
|
innodb_log_buffer_size = 32M
|
innodb_flush_method = O_DIRECT
|
|
|
# datadir on SSD
|
innodb_flush_neighbors = 0
|
innodb_io_capacity = 1000
|
innodb_io_capacity_max = 80000
|
|
|
# Higher Concurrency
|
max_prepared_stmt_count = 1048576
|
max_connections = 2048
|
table_open_cache = 4096
|
|
|
# the options we want to tune
|
innodb_lru_scan_depth = 1024
|
# only in bb-MDEV-23399
|
loose-innodb_lru_flush_size = 256
|
use oltp_write_only.lua from sysbench 1.x with this cmdline
sysbench oltp_write_only.lua --tables=16 --threads=16 --table-size=2000000 <connect args> prepare
|
sysbench oltp_write_only.lua --tables=16 --threads=... --table-size=2000000 --rand-type=uniform --report-interval=5 --events=0 --time=600 <connect args> run
|
| Link | This issue blocks MDEV-23756 [ MDEV-23756 ] |
| Link |
This issue relates to |
| Link |
This issue is caused by |
Hello, we are tracking this report with great interest. Could you confirm if you think the fix for this issue will make it for 10.5.6?
Thanks in advance.
Hi Bernardo Perez, this is hard to predict. We treat this issue with high priority. But the next 10.5 release will be due some time and we cannot delay it infinitely to wait for the fix for this issue. Or the other fixes that are already done will not make it to our users.
If you are concerned that this issue might bite you, you can mitigate it's effect by increasing the redo log size and/or increase the innodb-io-capacity.
| Status | Open [ 1 ] | In Progress [ 3 ] |
I can repeat random dips in the throughput (from 120ktps to as low as 55ktps) when the throughput is reported at 5-second intervals. In a 10-minute run I see one significant dip (below 100ktps) for a 5-second interval once about every 2 minutes. For the most recent run, the performance degraded at 110, 230, 460, 575 seconds into the benchmark. This was on /dev/shm, using (among other things) the settings innodb_io_capacity=1000 and innodb_flush_neighbors=0 (because the RAM disk does not qualify as SSD for MDEV-17380).
I think that I can repeat a similar anomaly when running oltp_update_index on a 10×2-core CPU at 16 threads on /dev/shm (RAM disk) with the following configuration changes:
|
10.5-MDEV-23399 4c295735a916b4e76748025eb84c055e628385f3 |
innodb_io_capacity=1000
|
innodb_io_capacity_max=1000
|
innodb_flush_neighbors=0
|
innodb_flush_sync=0
|
The throughput would drop at 110s from 124ktps first to 74ktps, finally to as low as 2ktps, for almost 200 seconds. Some 100 seconds later, the throughput would drop again, before fully recovering to the previous maximum. For me, the innodb_flush_sync=0 was the trick; with the default setting ON, the performance would be rather good (only a couple minor 5-second stalls).
I tried additionally setting innodb_adaptive_flushing_lwm=0 (which I think could be a good idea to set by default), but it did not “rescue” the situation.
axel, can you generate the graphs for this scenario and see if they look similar to those that you reported? I was expecting that the oscillations would be caused by your rather high innodb_io_capacity_max/innodb_io_capacity ratio of 80 (by default, it is 2). I have seen performance tuning suggestions to use a ratio of 1 to minimize oscillation, but I am indeed seeing a performance drop on RAM disk when using the same (ridiculously low) value for both.
In my variation of the benchmark, I noticed that during the performance stall, 20 threads were executing inside log_checkpoint_margin(). This is expected when the log capacity is exceeded and innodb_flush_sync=OFF. But what was not expected that the threads would sleep 10ms and poll again. I changed that to a wait for a condition variable, which should be set by the page cleaner thread at least once per second.
With innodb_flush_sync=ON I was not able to repeat the original claim. But, I improved the logic so that as long as buf_flush_sync_lsn has been set, it will remain set until MIN(oldest_modification) is below that target. Furthermore, the page cleaner thread will prioritize this mode of operation.
With that change, I got rather long performance drops when running on RAM disk. I implemented another revision where the flush batch would be triggered directly by buf_flush_wait_flushed() instead of the page cleaner thread, which would reduce the throughput for less than 10 seconds at a time. Because an initial version of this variant performed very badly for axel, we might better let the page cleaner thread take care of the checkpoint-related synchronous flushing.
I think that it is best to let the dedicated page cleaner thread take care of the 'furious flushing' that is prompted by a log checkpoint. I tweaked the inter-thread communication and implemented an adaptive 'flush-ahead'. It is somewhat challenging to find a good balance between frequent flushing bursts (which will cause the throughput to drop noticeably) and permanently engaged 'furious flushing' mode (which will result in a degraded but fairly stable throughput), but I think I found something that works rather well on a RAM disk based test. Hopefully it will perform reasonably on real storage as well.
Yesterday, I implemented a new kind of flush-ahead: Once we reach a ‘soft’ limit, we will signal the page cleaner thread to flush the buffer pool up to the current LSN. This seemed to perform best on my system (tested on NVMe and RAM disk). If we set the limit too low, then the page cleaner would engage in furious flushing mode too frequently or almost constantly.
Today, I made some experiments with
sudo perf record -t $buf_flush_page_cleaner_thread_LWP_ID_FROM_GDB
|
and identified some CPU hotspots. If neighbour flushing is disabled (I filed MDEV-23929 related to that), we will avoid a buf_pool.page_hash lookup. We will also avoid fil_space_t lookups, but I was still seeing the spinning around fil_system.mutex as a significant user of CPU when the furious flushing was in effect. During normal flushing, it was much less of a bottleneck.
I eliminated fil_system.LRU and frequent use of fil_system.mutex. Only when a file needs to be opened or closed (for enforcing a configured limit innodb_open_files), the mutex will come into the play. It will also be used around fsync() operations, but it was not visible in my profiling. That could probably be replaced too. The LRU policy was replaced with a FIFO policy: (re)opened files move to the end of the queue.
The spinning in fil_system.mutex accounted for up to 5% of the sampled execution time of the page cleaner thread. It was acquired and released several times per I/O operation, not only in preparation (all done by the page cleaner thread), but also on I/O completion (executed by other threads and thus causing contention).
I also tried parallelizing buf_flush_page() so that the checksum computation would be submitted to multiple threads, but the initial attempt did not work out at all. The maximum latency in my benchmark skyrocketed from less than 5 seconds to more than 200 seconds.
One more thing to try would be to initiate persistent log writes asynchronously, so that the page cleaner thread would not be blocked waiting for log_write_up_to() at the start of each batch.
I eliminated even more use of fil_system.mutex and shrunk both fil_node_t and fil_space_t by consolidating things into a single std::atomic reference counter with a few flags.
For testing, I use extreme parameters (such as innodb_io_capacity=100 and innodb_flush_log_at_trx_commit=0) to ensure that the page cleaner will sit mostly idle between checkpoints, to ensure that checkpoints that are triggered by log_free_check() will perform the maximum amount of I/O. When the test is running on RAM disk, the majority of the CPU cycles of the page cleaner thread will be spent in the Linux kernel, copying data from user space to kernel space. If I run the test on NVMe and use innodb_flush_method=O_DIRECT, the page checksum calculation will dominate.
I did not try asynchronous log flushing yet. That might better be avoided in the 10.5 GA release.
I fine-tuned log_checkpoint_margin() and made the log_sys.max_checkpoint_age_async threshold be 7/8 of log_sys.max_checkpoint_age, instead of the original 31/32. That will give a little more "early warning". For the scenario that I tested, 7/8 worked best. 3/4 would trigger too frequent ‘furious flushing’.
I think that the log_sys.max_modified_age_async should only matter for the adaptive page flushing in the background (when using higher innodb_io_capacity to avoid the ‘furious flushing’ scenario), and log_sys.max_modified_age_sync has no reason to exist at all.
Finally, I made buf_flush_lists() trigger a log flush in a separate task, or wait for a pending task to finish before possibly scheduling a new one. This will allow the page cleaner thread to perform more actual work (writing out dirty data pages) when it is running in innodb_flush_sync=ON mode for a checkpoint flush. This improved the average throughput on my system.
The maximum latency seems to be unaffected by my changes. Any thread that invokes log_free_check() (before initiating any write mini-transactions) may block in log_checkpoint_margin() until enough data has been written.
| Link |
This issue relates to |
Hello Marko,
I can see from your comments on MDEV-23399 that you are close to finish the work for this fix.
Would you think this fix will make it for 10.5.7?
Thanks in advance.
I rebased the commits into logical pieces for ease of review. The asynchronous log write for page flushing was part of the final MDEV-23399.
I think that this work is now mostly done, but we may have to fine-tune some parameters or perhaps introduce some settable global variables.
| Assignee | Marko Mäkelä [ marko ] | Vladislav Vaintroub [ wlad ] |
| Status | In Progress [ 3 ] | In Review [ 10002 ] |
I fixed some race conditions related to my removal of fil_system.mutex contention (and while doing that, apparently introduced a file handle leak somewhere, breaking the Windows bootstrap). I also tried to make the page cleaner thread perform log checkpoints, because in benchmarks we are seeing a pattern where the log checkpoint age grows from 0 to the maximum, then everything is halted, and the cycle repeats.
If we perform checkpoints after every batch, progress will be guaranteed. Depending on the distribution of page modifications, skipping a checkpoint might be a bad idea, because during the next flush batch, one of the pages that we already cleaned could be locked or could have been changed again, forcing us to wait for the next batch to write the redo log.
Apparently the calculations in page_cleaner_flush_pages_recommendation() (number of pages to flush per second in innodb_adaptive_flushing=ON) may be inaccurate. I think that we must make innodb_adaptive_flushing=OFF (the non-default setting) simply try to write out innodb_io_capacity pages per second. The inconsistent calculations can be fixed separately.
I rewrote the page cleaner so that it aims to run page flush batches once per second, ignoring any "activity count" that is more or less counting user transaction commits. This should guarantee that in innodb_adaptive_flushing=OFF mode we will write out innodb_io_capacity dirty pages per second. In the default innodb_adaptive_flushing=ON case, the rate should vary according to what page_cleaner_flush_pages_recommendation() returns. In both modes, a log checkpoint will be attempted at the end of each batch.
The problem on Windows should now be fixed, by having fil_ibd_create() use the asynchronous I/O mode. Before my fil_system.mutex contention fixes, we used to create each .ibd file in normal mode, close it, and eventually reopen for asynchronous I/O.
| Link |
This issue is blocked by |
| Attachment | Screen Shot 2020-10-20 at 5.02.56 PM.png [ 54439 ] |
| Attachment | Screen Shot 2020-10-20 at 5.02.56 PM.png [ 54439 ] |
| Attachment | Screen Shot 2020-10-20 at 5.59.20 PM.png [ 54440 ] |
{kind=link}
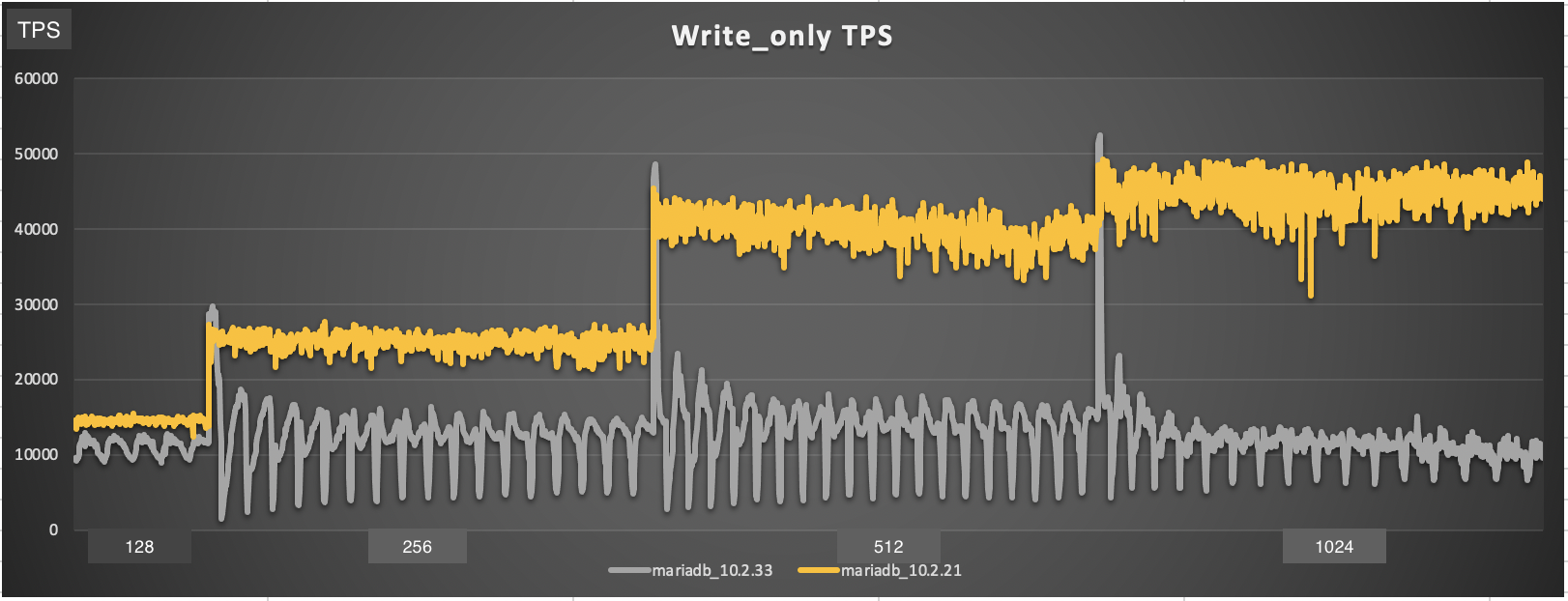
I repeated the same OLTP write_only sysbnech test on 10.2.21 and 10.2.33 using incremental threads (1,2,4,8 .. 1024). Starting from threads 128 and above, 10.2.21 become much faster than 10.2.33. The most interesting part here is that 10.2.33 started high for each thread then the performance dropped and showed same oscillations in throughput as in this bug which is apparently related to the checkpointing. Could you please confirm that this bug does not affect other versions than 10.5?
Attaching the performance graph for my test.
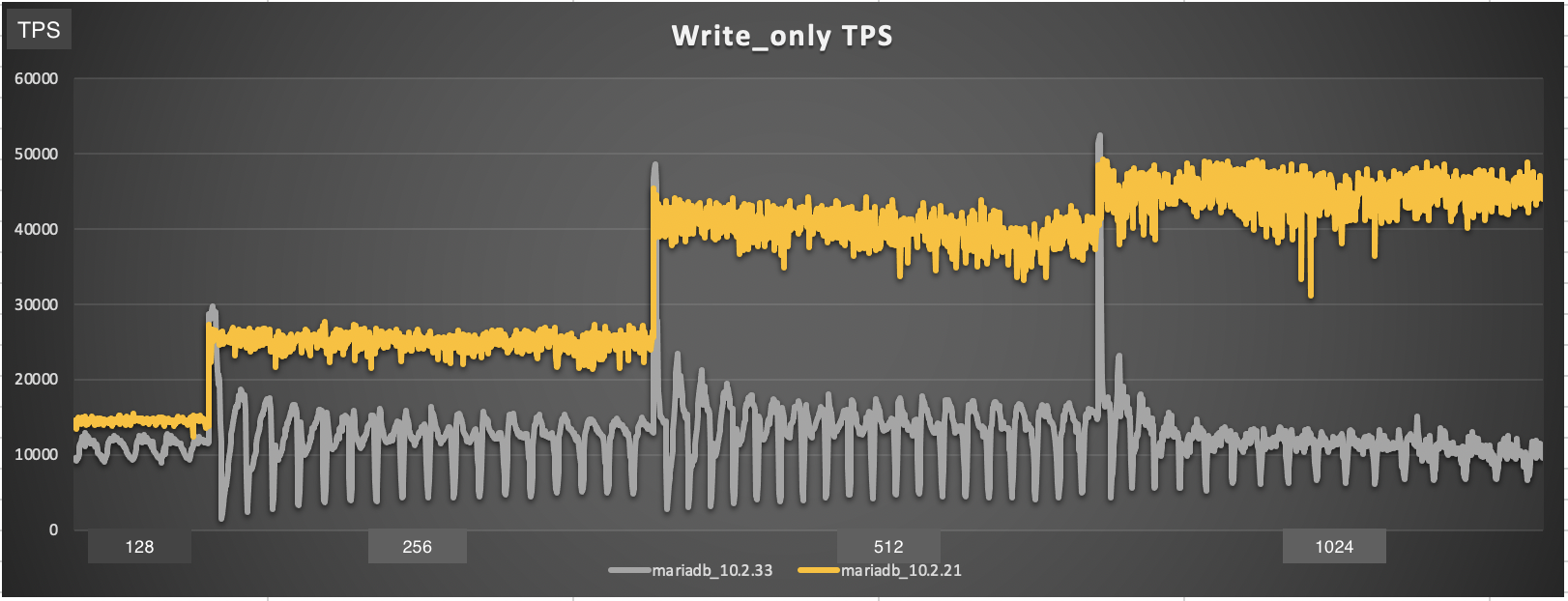
| Link |
This issue blocks |
| Link |
This issue relates to |
abdelmawla, what you observe could be MDEV-23475, which affects 10.2.33 and 10.2.34. Can you please test MariaDB 10.2.32 or the latest 10.2 development snapshot?
Smaller batches of buf_flush_lists() will improve the maximum latency (on my GNU/Linux system with 2.3GB/s NVMe, from 4.6 seconds to 74 milliseconds).
Marko, yeah I also saw https://jira.mariadb.org/browse/MDEV-23475 but I was not sure which bug I'm hitting or I could be hitting both.
I will do the same test on 10.2.32 and update this bug if I got the same regression.
| Link |
This issue is blocked by |
Today, I tested on a SATA 3.0 hard disk. Thanks to wlad’s suggestion, the page cleaner thread no longer uses synchronous I/O in the doublewrite buffer. The page cleaner thread may still wait for I/O on two occasions: at the start of each buf_flush_lists() batch, and whenever the next batch of page writes needs to be posted to the doublewrite buffer and the previous doublewrite batch is still in progress.
| Assignee | Vladislav Vaintroub [ wlad ] | Marko Mäkelä [ marko ] |
Fixing this has been a rather long journey with several dead ends. wlad’s comparison to 10.5 (containing the MDEV-23399 changes) suggests that it is better to minimize the ‘furious flushing’ duration, because it really hurts throughput when using anything else than the highest-end storage. I removed log_sys.max_checkpoint_age_async (which was log_sys.max_checkpoint_age*31/32) and related ‘furious-flush-ahead’. I also reverted a change where upon reaching the originally requested checkpoint age target the page cleaner would re-evaluate the target and keep furious-flushing if the condition prevails.
The key features of the fix are as follows:
- Make the page cleaner thread responsible for making log checkpoints. The checkpoint can advance by the maximum amount immediately after a flushing batch.
- Reduce contention on fil_system.mutex. (It is still needed around fdatasync() calls unless innodb_flush_method=O_DIRECT_NO_FSYNC, and during log checkpoints until
MDEV-14425removes that need.) - Use double-buffering and asycnhronous writes for the doublewrite buffer to reduce I/O waits during page flushing.
- Make the parameter innodb_max_dirty_pages_pct_lwm work as advertised: unless ‘furious flushing’ is needed due to the log capacity being exceeded, or LRU flushing is needed due to page eviction, no pages will be written out if the limit is not exceeded.
- During the ‘furious flushing’ (innodb_flush_sync=ON) we will attempt to write innodb_io_capacity_max pages per batch. If that parameter is set roughly equal to the maximum number of page writes per second, this means that we will attempt one checkpoint per second. Previously, these batches were unlimited and detached from checkpoint activity.
- When innodb_flush_adaptive=OFF, outside ‘furious flushing’ we will use a constant write rate of innodb_io_capacity pages per second.
- The srv_check_activity() has been removed, and therefore page flushing is completely detached from user transaction activity. (This complex dependency caused
MDEV-23475in 10.2, 10.3, 10.4.)
I believe that on a fast SSD or when the maximum latency and recovery speed are not important, one could want to tune the page cleaner so that it does not write much (or anything) normally: innodb_max_dirty_pages_pct_lwm and innodb_max_dirty_pages_pct should be close to 100%, or innodb_io_capacity set close to the minimum value. The innodb_io_capacity_max could be set close to the actual hardware capability, so that upon reaching the log capacity, we will be able to advance the log checkpoint at least once per second. Such settings should minimize write amplification while possibly increasing latency when a log checkpoint must be initiated due to reaching the capacity of the circular redo log, or when a page needs to be written out by LRU eviction (MDEV-23399).
The innodb_max_dirty_pages_pct_lwm that was changed by MDEV-23399 from 0 to 75 was reverted, because users may expect the shutdown of an idle server to be fast. We might change that in a next major release, but not in the middle of a GA release series.
The remaining observed contention around fil_system.mutex is related to fil_system.unflushed_spaces when innodb_flush_method=O_DIRECT_NO_FSYNC is not being used, and to FILE_MODIFY records that we will write out during log checkpoints until MDEV-14425 will change the log format.
In a future release, we might want to try to replace fil_system.unflushed_spaces with something lock-free, or simply change the default innodb_flush_method unless there are good reasons against it.
Log checkpoints will flush pages of InnoDB temporary tables as ‘collateral damage’ until MDEV-12227 has been addressed.
| issue.field.resolutiondate | 2020-10-26 16:06:16.0 | 2020-10-26 16:06:16.493 |
| Fix Version/s | 10.5.7 [ 25019 ] | |
| Fix Version/s | 10.5 [ 23123 ] | |
| Fix Version/s | 10.6 [ 24028 ] | |
| Resolution | Fixed [ 1 ] | |
| Status | In Review [ 10002 ] | Closed [ 6 ] |
| Link |
This issue relates to |
| Link |
This issue causes |
| Link |
This issue causes |
What the source code refers to by "flush_list flushing" and "LRU flushing" should better be called checkpoint flushing (writing out data pages for a log checkpoint) and eviction flushing (writing out modified pages so that they can be replaced).
The ultimate purpose of the checkpoint flushing is to avoid a situation where the circular log file becomes unrecoverable due to the tail of the log overwriting the head. The checkpoint would logically remove the head of the log, making the recovery start from a newer checkpoint LSN. This ticket (MDEV-23855) significantly reduced the latency related to checkpoint flushing, especially in the case when the log capacity is reached and the condition in log_free_check() would hold.
The eviction flushing is necessary when we are running out of buffer pool, and there exist unwritten changes for the least recently used pages, possibly because the buffer pool is small and the log file is large (possibly much larger than the buffer pool; our recovery can consist of multiple batches without problems, ever since MDEV-21351 was implemented). Performance problems related to that were addressed in MDEV-23399 (which also removed the special case of "single-page flushing").
The further improvement in MDEV-12227 will be that pages belonging to temporary tables may only be written as part of eviction flushing, and never for checkpoint flushing.
| Link |
This issue causes |
| Link |
This issue causes |
| Link |
This issue causes |
| Link |
This issue causes |
Unfortunately, innodb_flush_sync=OFF is broken (MDEV-24109) in MariaDB 10.5.7 as a result of these changes. With that fix, the checkpoint flushing is always performed by the page cleaner thread, in batches of innodb_io_capacity_max pages, and setting innodb_flush_sync=OFF will limit the rate to innodb_io_capacity_max pages per second.
| Attachment | Innodb-max-dirty-pages-pct-lwm.png [ 54636 ] |
| Attachment | Innodb_io_capacity.png [ 54637 ] |
In order to make the most out of the changes done in this task (MDEV-23855) you must also configure InnoDB correctly. There are two important server variables to look at. Both give the DBA a chance to balance between IO needs and SQL throughput capabilities.
There are two timeseries plots attached. Innodb-max-dirty-pages-pct-lwm.png![]() shows how the server variable innodb_max_dirty_pages_pct_lwm affects flushing. The plot begins with innodb_max_dirty_pages_pct_lwm=0 and increases it by 10 every 1800 seconds. Higher values reduce flushing activity. The number of dirty pages in the buffer pool increases, more changes to a page can be combined to a single write, reducing the IO per transaction.
shows how the server variable innodb_max_dirty_pages_pct_lwm affects flushing. The plot begins with innodb_max_dirty_pages_pct_lwm=0 and increases it by 10 every 1800 seconds. Higher values reduce flushing activity. The number of dirty pages in the buffer pool increases, more changes to a page can be combined to a single write, reducing the IO per transaction.
On the downside this also increases the InnoDB checkpoint age. When you hit the soft limit at ~80% of the redo log capacity, InnoDB will start furious flushing, resulting in oscillations. The plot shows this after 10800 seconds when innodb_max_dirty_pages_pct_lwm is changed from 50 to 60. Keep in mind that the best values depends on workload, data set size, redo log capacity and some more.
The other variable is innodb_io_capacity, covered by the Innodb_io_capacity.png![]() timeseries plot. In this plot we start with innodb_io_capacity=500 and increase it every 2000 seconds up to 12000. The variable sets the target flushing rate (pages per second). If this is set too low, InnoDB will again reach the checkpoint age limit and oscillate beween furious and relaxed flushing. Only when the flushing rate is high enough to keep pace with the rate of pages made dirty, InnoDB reaches a steady state. If you set innodb_io_capacity higher than needed, InnoDB will flush pages more often, leading to fewer writes being combined and more IO per transaction.
timeseries plot. In this plot we start with innodb_io_capacity=500 and increase it every 2000 seconds up to 12000. The variable sets the target flushing rate (pages per second). If this is set too low, InnoDB will again reach the checkpoint age limit and oscillate beween furious and relaxed flushing. Only when the flushing rate is high enough to keep pace with the rate of pages made dirty, InnoDB reaches a steady state. If you set innodb_io_capacity higher than needed, InnoDB will flush pages more often, leading to fewer writes being combined and more IO per transaction.
| Link |
This issue causes |
| Link |
This issue causes |
| Link |
This issue causes |
| Link |
This issue relates to |
| Link |
This issue causes |
| Link |
This issue relates to |
| Link |
This issue relates to |
| Link |
This issue causes |
| Link |
This issue causes |
With MDEV-24537 fixed (in 10.5.9), the default value innodb_max_dirty_pages_pct_lwm=0 will retain its previously undocumented meaning: innodb_max_dirty_pages_pct (a similarly-named parameter without the _lwm suffix) will be consulted instead. To have other versions behave like MariaDB 10.5.7 and 10.5.8 with regard to this parameter, I believe that the following should work:
SET GLOBAL innodb_max_dirty_pages_pct_lwm=0.0001; |
It is obvious that having the page cleaner thread perform eager ‘pre-flushing’ will reduce the age of the log checkpoint, and thus will reduce the likelihood that user threads will have to wait for a checkpoint flushing batch to successfully reduce the age of the checkpoint.
As part of this task, the page cleaner was almost rewritten, and many CPU contention points were removed. The contention on fil_system.mutex was reduced, and the doublewrite buffer initiates asynchronous writes, instead of synchronous ones. Thanks to these changes, the maximum latency (even in the case that the ‘pre-flushing’ is disabled) should be lower. In MDEV-24537 I posted the result of a quick test on a hard disk.
One more thing worth noting is that the parameter innodb_io_capacity is not only the target number of pages per second to write during the ‘background pre-flushing’ (when it is enabled by innodb_max_dirty_pages_pct_lwm and other parameters), but also the number of pages to write per batch during the furious checkpoint flushing (enabled by default by innodb_flush_sync=ON).
My intuition says that a DBA who wants to minimize ‘write amplification’ should try to disable the pre-flushing altogether (so that repeatedly modified pages will be rewritten to data files less frequently). In that kind of a scenario, I would expect that setting innodb_io_capacity to a small value will reduce the wait times in buf_flush_wait_flushed().
I think that we will need more benchmarking for this. One parameter that I do not think we have not measured is ‘average number of page writes per transaction’. I think that we should try to minimize that while simultaneously trying to keep the throughput and latency as stable as possible. Possibly, the function buf_flush_sync_for_checkpoint() will need a separate parameter for the number of pages written per batch, instead of reusing innodb_io_capacity. (After all, that function is executing in I/O bound mode, potentially writing many more than innodb_io_capacity pages per second.)
| Link |
This issue relates to |
| Link |
This issue relates to |
| Link |
This issue relates to |
| Link |
This issue relates to |
| Link |
This issue relates to |
| Link |
This issue causes |
| Link | This issue blocks MDEV-11659 [ MDEV-11659 ] |
| Link |
This issue relates to |
| Link |
This issue relates to |
| Link |
This issue causes |
| Link | This issue blocks TODO-400 [ TODO-400 ] |
| Link | This issue blocks TODO-398 [ TODO-398 ] |
| Link |
This issue causes |
| Link |
This issue causes |
| Link | This issue relates to MDEV-15752 [ MDEV-15752 ] |
| Epic Link | MDEV-26620 [ 102791 ] |
| Link |
This issue causes |
| Link |
This issue relates to |
| Workflow | MariaDB v3 [ 114047 ] | MariaDB v4 [ 158419 ] |
| Link |
This issue relates to |
| Link |
This issue causes |
| Link |
This issue causes |
| Link |
This issue causes |
| Link | This issue relates to MENT-1726 [ MENT-1726 ] |
| Link |
This issue causes |
| Link |
This issue causes |
| Link |
This issue causes |
| Link |
This issue causes |
| Link |
This issue relates to |
The problem can be seen with MariaDB-10.5.3 too. It happens only at higher thread counts. Up to 64 threads everything is fine. With 128 threads we can see first small oscillations. With 256 threads everything goes down the drain.