Details
-
Bug
-
Status: Closed (View Workflow)
-
 Blocker
Blocker
-
Resolution: Fixed
-
10.5, 10.6, 10.11, 11.0(EOL), 11.1(EOL), 11.2(EOL), 11.3(EOL)
-
Ubuntu 18.04 on AMD64
Ubuntu 20.04 on AMD64
Description
After implementing MDEV-32757, we are seeing a performance anomaly with innodb_undo_log_truncate=ON. The server is not actually hung or deadlocked (it will eventually recover), but buf_pool.mutex is being occupied for an extremely long time (several minutes).
- trx_purge_truncate_history() writes the message InnoDB: Truncating and is about to truncate an undo log tablespace.
- trx_purge_truncate_history() is busy-looping in a scan of buf_pool.flush_list because one of the pages belonging to the undo tablespace is write-fixed.
- During the time trx_purge_truncate_history() releases and re-acquires buf_pool.flush_list_mutex, buf_flush_page_cleaner (which is holding buf_pool.mutex in buf_do_flush_list_batch()) cannot grab it, in this Ubuntu 18.04 version of GNU libc and Linux kernel (4.15.0-112-generic). This could be similar to
MDEV-31343andMDEV-30180, which could only be reproduced in the same particular environment. - Most threads are blocked because the buf_flush_page_cleaner thread is holding buf_pool.mutex.
There is some indication that buf_flush_list_batch() may be making some progress (writing out some pages), but it would be extremely slow.
Attachments

Issue Links
- relates to
-
-

- Open
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
Activity
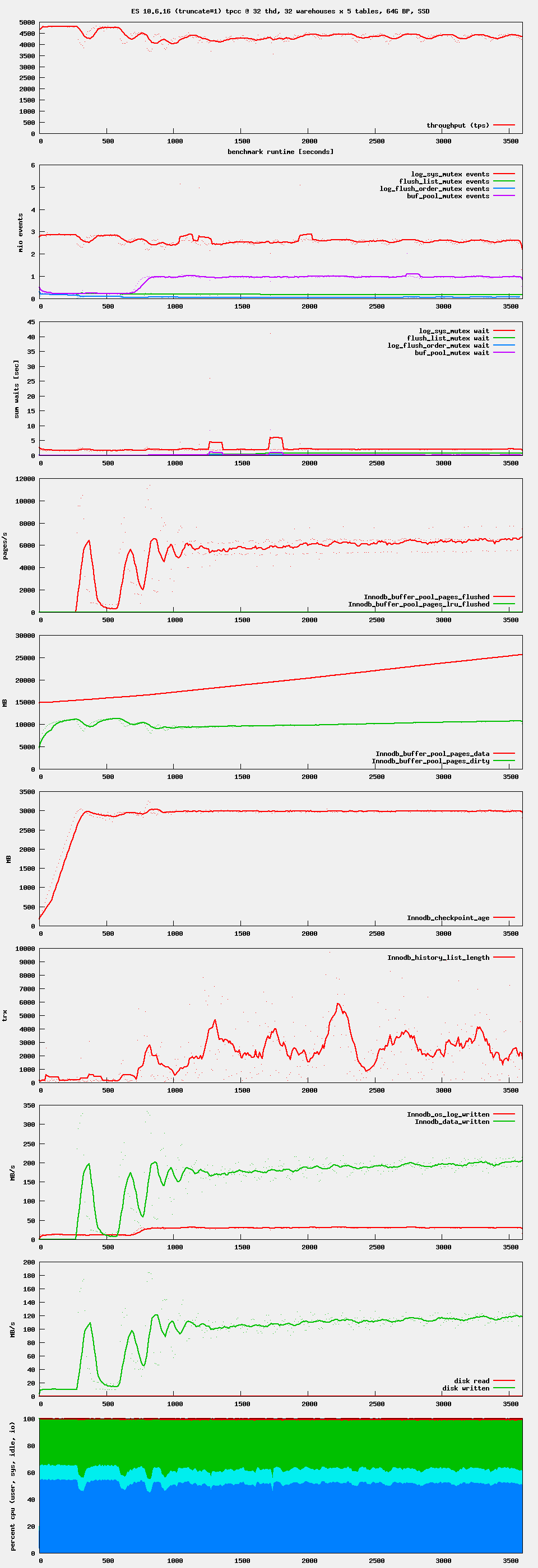
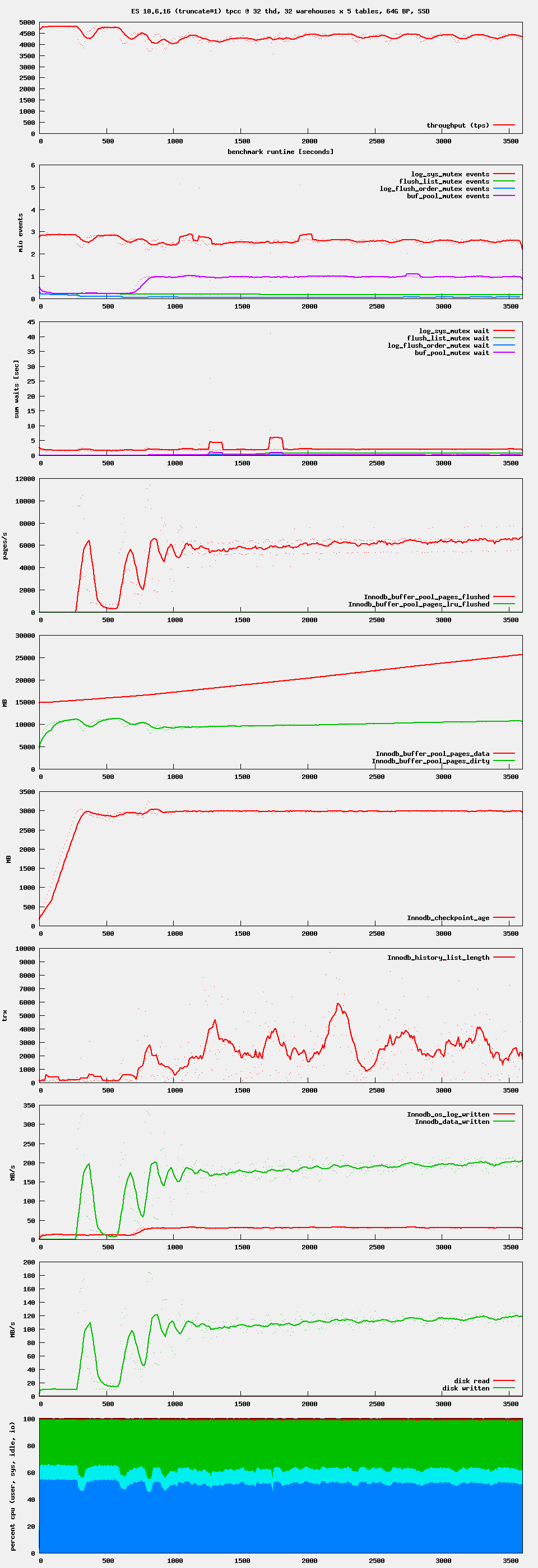
For 10.5 we apparently need a more intrusive version of trx_purge_truncate_history() that will acquire and release buf_pool.mutex on every block that it finds in the to-be-truncated tablespace. The successfully tested fix for 10.6 will only acquire and release buf_pool.mutex when a page latch had to be waited for.
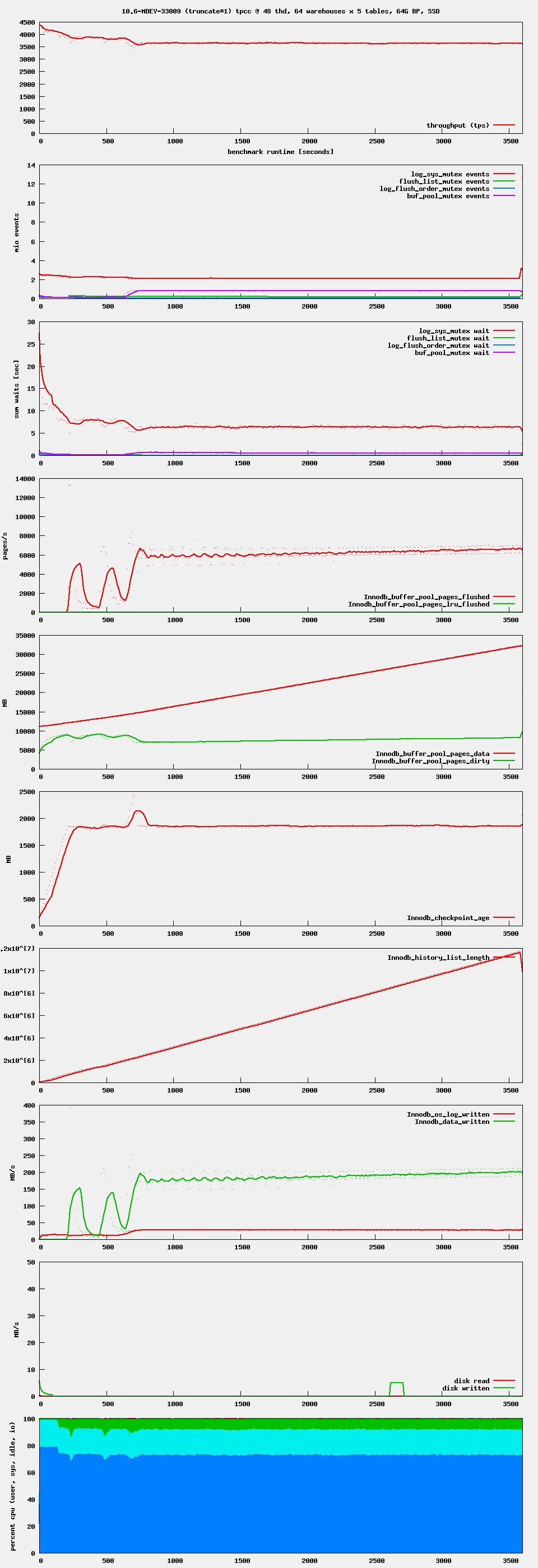
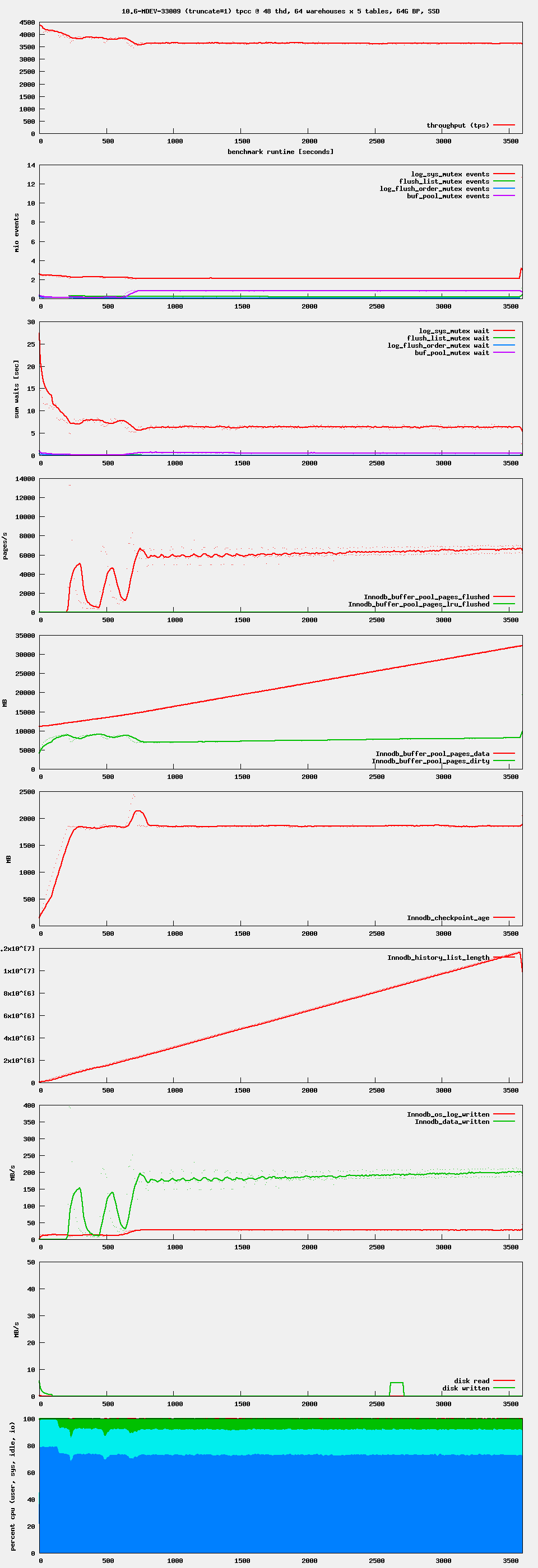
10.6-MDEV-33009 has completed the run with the bigger data set. For 10.6 we have a solution.
10.5-enterprise-MDEV-33009, commit fb800bd29ab hangs immediately. InnoDB reports a long semaphore wait.
origin/10.5-enterprise-MDEV-33009 0252987cde576a50a693e9af88fbef7057a010f9 2023-12-13T11:44:17+02:00
|
performed well in RQG testing. No new problems
|
On 10.5-enterprise, axel reproduced other hangs that involve buffer pool page access during undo tablespace truncation. Yesterday I checked one case where the undo tablespace truncation is in progress and both buf_pool.mutex and buf_pool.flush_list_mutex (which these patches affect) are vacant. There was a deadlock on page latches, and trx_rsegf_get() was one of the blocked functions. This reminds me of MDEV-32820.
The stack trace samples in mariadb-ES-10.5-MDEV-33009-fb800bd29ab.zip![]() are for such a hang. In the file pmp_raw_360.txt we can see that Thread 5 (buf_flush_page_cleaner()) is not holding either mutex. Thread 52 (trx_purge_truncate_history() is not truncating any undo tablespace, but waiting for an latch on the rollback segment header page 3 of tablespace 2 (0x5555eaace9f8) in trx_rsegf_get(), on rollback segment 2. Because the stack traces do not include local variables, I can’t easily see which other threads would be holding a conflicting page latch. We also see several DML threads blocked in trx_undo_seg_create() on 3 distinct undo tablespaces. One of them is 0x5555eaace9f8, which Thread 52 is operating on. But none of them are on the same rollback segment 2 (0x5555eaaee2c8). The 127 rollback segments should be distributed evenly on the innodb_undo_tablespaces=3.
are for such a hang. In the file pmp_raw_360.txt we can see that Thread 5 (buf_flush_page_cleaner()) is not holding either mutex. Thread 52 (trx_purge_truncate_history() is not truncating any undo tablespace, but waiting for an latch on the rollback segment header page 3 of tablespace 2 (0x5555eaace9f8) in trx_rsegf_get(), on rollback segment 2. Because the stack traces do not include local variables, I can’t easily see which other threads would be holding a conflicting page latch. We also see several DML threads blocked in trx_undo_seg_create() on 3 distinct undo tablespaces. One of them is 0x5555eaace9f8, which Thread 52 is operating on. But none of them are on the same rollback segment 2 (0x5555eaaee2c8). The 127 rollback segments should be distributed evenly on the innodb_undo_tablespaces=3.
At the point of the wait for the page latch, Thread 52 should only hold a rollback segment mutex and wait for the undo page 3 in tablespace 2. I do not think that any other thread should be holding that rollback segment header page latch. It could be that we are facing a bug in the original InnoDB rw-lock implementation, which was fixed in MDEV-24142 (MariaDB Server 10.6). I suspect that it could lose wakeup signals from time to time. In fact, we can see that the test innodb.undo_truncate is hanging every now and then on various different platforms on 10.5, but not on 10.6. (Please disregard 10.6 failures due to MDEV-30728 and MDEV-29610.) Also, note that this is different from the similarly named test innodb.undo_truncate_recover whose 10.5 failures were addressed in MDEV-32681.
I am afraid that the fix of those page latch related hangs would be to apply MDEV-24142 to 10.5, which I think is infeasible. What would be more feasible is to test if the hang only occurs in that Ubuntu 18.04 environment. Statistical data from our CI systems (which includes other systems than Ubuntu 18.04) suggests that it could be the case.
axel, after some digging, I found MDEV-26733 that has been filed for the page latch related hang on 10.5.
Short of acquiring also buf_pool.mutex around the buf_pool.flush_list traversal loop of the 10.5 trx_purge_truncate_history(), there does not seem to be any way to avoid those hangs on Ubuntu 18.04. (And the MDEV-26733 page latch leaks would come on top of that.)
I would like to know if these hangs are repeatable in any other environment. I would not want to acquire and release the already busy buf_pool.mutex for no apparent reason, only to ‘please’ the Linux kernel or GNU libc version that is running in one performance testing environment. Ubuntu 18.04 reached its end-of-life already in April 2023, and this system is not even running the latest kernel.
The 10.6 fix for this issue (branch 10.6-MDEV-33009, commit 2c344d13188) seems to be good. It passed all tests on cheetah01 (Ubuntu 18.04)
The extreme waits are reproducible also on Ubuntu 20.04, on both 10.5 and 10.6.
I got another idea: We’d better release and reacquire buf_pool.flush_list_mutex when trx_purge_truncate_history() needs to rescan the buf_pool.flush_list. If this is not sufficient to prevent the performance drops, then we’d also have to ‘dummily’ acquire and release the buf_pool.mutex.
Both 10.5 (branch 10.5-MDEV-33009, up to commit e1c545486ad) and 10.6 (branch MDEV-33009 up to commit 76b99fccb44) show the waits on Ubuntu 20.04. Some more heavy than the others, but still present.
I don't think we can leave the server in this state. It may be better to have a slow server than to have corruption though. IMHO we need a big fat warning in the KB besides innodb_undo_log_truncate=ON.
results for 10.6: mariadb-10.6-MDEV-33009-76b99fccb44.zip![]()
and for 10.5 with the #if 0 turned to #if 1: mariadb-10.5-MDEV-33009-e1c545486ad+1.zip![]()
I pushed the 10.5 version. Yes, it is somewhat slower than before the fix of MDEV-32757, but based on the detailed graphs this is due to page writing activity. Shortly before the performance dips, there is a log checkpoint taking place. Then, some 100 or 200 seconds after it ends, we got another batch of page writing activity. Before MDEV-32757, some of these page writes were ‘optimized away’, that is, modified undo pages were being discarded prematurely. With an unlucky timing of a log checkpoint, that would break crash recovery and backups in a very crude way, basically making innodb_force_recovery=3 the only option to recover some data in case of unlucky timing of a log checkpoint.
The 10.6 version needs more work. I will add the trick of ‘unnecessarily’ acquiring buf_pool.mutex in order to ensure progress of the buf_flush_page_cleaner() thread.
marko is the performance dip only when innodb_undo_log_truncate=ON?
Here is a summary plot of the performance/behavior of various 10.5 and 10.6 commits for community server. 4 commits are shown:
- red line: last release (broken, corruption!)
- green line: HEAD of development
- blue line: HEAD of
MDEV-33009branch (less aggressive version) - pink line: HEAD of
MDEV-33009branch (aggressive version)
Attachment: 24x5_high_threads.pdf![]()
the tests with data set size 12x5 (12 thd) and data set size 24x5 (24 thd) did not make the undo logs grow and thus caused no truncate operation.
It seems the pink line gives the best (but not good) result.
Yes, this bug occurs during a scan of dirty pages that is enabled by setting innodb_undo_log_truncate=ON.
commit 9682add5cdf "solves" the problem with performance, but effectively prevents undo log truncates during the benchmark. This can be clearly seen in the history list length here:
When we stop sysbench for 20 seconds every 6 minutes, the purge thread and with it the undo log trucate can run:
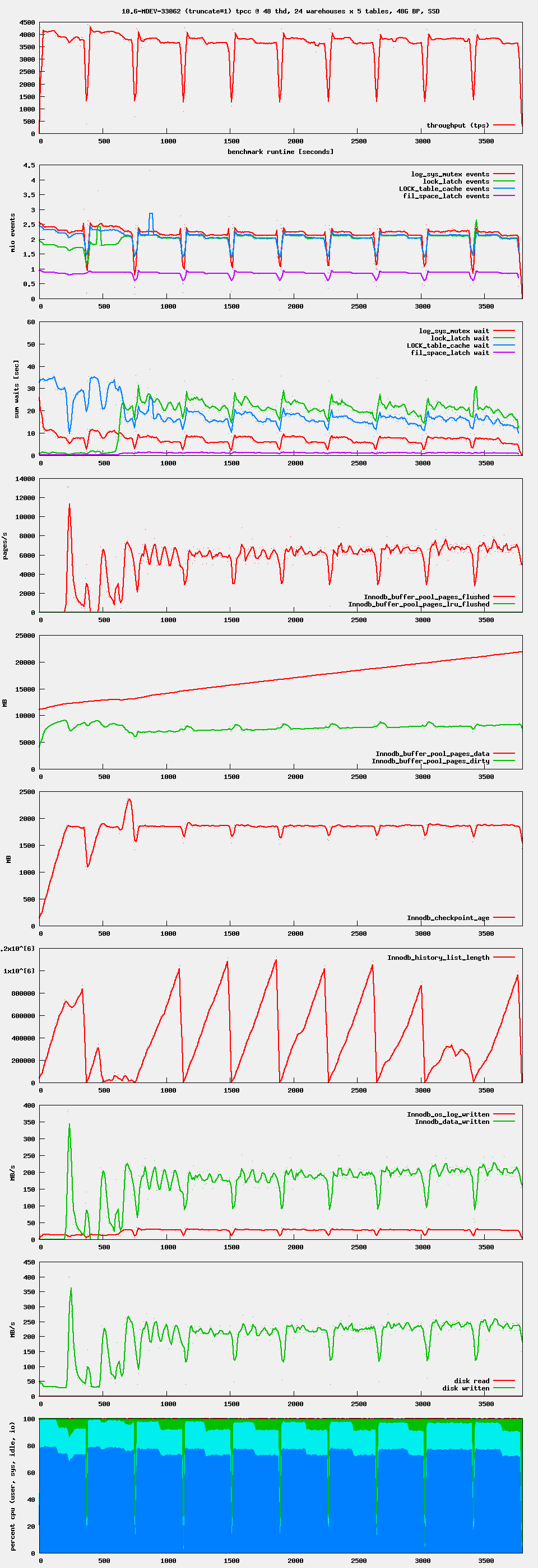
When we include 9682add5cdf we should add a KB comment that innodb_undo_log_truncate=ON will only have an effect when there are times when the server is not under stress.
axel, the commit that you mentioned only modifies some code that would be run after the InnoDB: Truncating message has been written to the server error log, to truncate an undo log tablespace. By design, the purge of history during a heavy workload is hard to predict. You might see some undo log truncation events during a workload if you let the workload run for a significantly longer time. In the bottom graph of 24x5_high_threads.pdf![]() we have some results where a similar change (purple line) caused some stalls during the workload. Compared to that change, the revised commit would make trx_purge_truncate_history() acquire and release buf_pool.mutex also when a buffer page latch cannot be acquired without waiting. Some other testing suggested that this could significantly increase the probability of goto rescan and transform the loop from a linear scan into a quadratic scan. When there are millions or more pages in buf_pool.flush_list, this could be significant.
we have some results where a similar change (purple line) caused some stalls during the workload. Compared to that change, the revised commit would make trx_purge_truncate_history() acquire and release buf_pool.mutex also when a buffer page latch cannot be acquired without waiting. Some other testing suggested that this could significantly increase the probability of goto rescan and transform the loop from a linear scan into a quadratic scan. When there are millions or more pages in buf_pool.flush_list, this could be significant.
Based on these results, I think that the setting innodb_undo_log_truncate=ON may only be useful when the concurrent write workload is light or moderate.
I filed MDEV-33112 for an idea that we can employ a lazy approach and avoid the intrusive buffer pool scan altogether.
The fix works for Enterprise 10.6, but not for 10.5.
Attached: mariadb-ES-10.5-MDEV-33009.zip