Details
-
Task
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Won't Do
Description
InnoDB startup unnecessarily waits for recovered redo log records to be applied to the data files.
In fact, normally while the function trx_sys_init_at_db_start() is executing, the pages that it is requesting from the buffer pool will have any recovered redo log applied to them in the background.
Basically, we only need to remove or refactor some calls in the InnoDB server startup. Some of this was performed in MDEV-19514 and MDEV-21216.
The crash recovery would ‘complete’ at the time of the next redo log checkpoint is written.
We should rewrite or remove recv_recovery_from_checkpoint_finish() recv_sys.apply(true) so that it will not wait for any page flushing to complete (already done in MDEV-27022). While doing this, we must also remove the buf_pool_t::flush_rbt (removed in MDEV-23399) and use the normal flushing mechanism that strictly obeys the ARIES protocol for write-ahead logging (implemented in MDEV-24626).
Attachments
Issue Links
- blocks
-
MDEV-12700 Allow innodb_read_only startup without prior slow shutdown
-
- Closed
-
- includes
-
-
- Closed
-
- is blocked by
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
- relates to
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
Activity
| Field | Original Value | New Value |
|---|---|---|
| Link |
This issue relates to |
| Link |
This issue relates to |
MDEV-13869 removes the .ibd file scans when no redo log apply is needed.
| Link |
This issue is blocked by |
| Assignee | Marko Mäkelä [ marko ] | Thirunarayanan B [ thiru ] |
In MariaDB Server 10.4, as part of removing the crash-upgrade support for the pre-MDEV-13564 TRUNCATE, it looks like we can safely remove the buf_pool_invalidate() call.
| Link |
This issue is blocked by |
The buf_pool_invalidate() call was already removed as part of MDEV-13564 (removing the old crash-upgrade logic in 10.4).
I tried the following patch:
diff --git a/storage/innobase/fil/fil0fil.cc b/storage/innobase/fil/fil0fil.cc
|
index 9abbc4a540a..3844c6ccbb7 100644
|
--- a/storage/innobase/fil/fil0fil.cc
|
+++ b/storage/innobase/fil/fil0fil.cc
|
@@ -3199,12 +3199,6 @@ fil_ibd_open(
|
} else if (err) *err = DB_SUCCESS;
|
|
mutex_exit(&fil_system.mutex);
|
-
|
- if (space && validate && !srv_read_only_mode) {
|
- fsp_flags_try_adjust(space,
|
- flags & ~FSP_FLAGS_MEM_MASK);
|
- }
|
-
|
return space;
|
}
|
mutex_exit(&fil_system.mutex); |
This would address the above comment regarding MDEV-9843.
With this change, I got an anomaly that did not look familiar to me:
|
10.4 5b996782be6b752ce50a0ecaa222b0688aa9e75d |
rpl.rpl_semi_sync_skip_repl 'innodb,row' w32 [ pass ] 2184
|
|
|
MTR's internal check of the test case 'rpl.rpl_semi_sync_skip_repl' failed.
|
This means that the test case does not preserve the state that existed
|
before the test case was executed. Most likely the test case did not
|
do a proper clean-up. It could also be caused by the previous test run
|
by this thread, if the server wasn't restarted.
|
This is the diff of the states of the servers before and after the
|
test case was executed:
|
mysqltest: Logging to '/dev/shm/10.4/mysql-test/var/32/tmp/check-mysqld_2.log'.
|
mysqltest: Results saved in '/dev/shm/10.4/mysql-test/var/32/tmp/check-mysqld_2.result'.
|
mysqltest: Connecting to server localhost:16641 (socket /dev/shm/10.4/mysql-test/var/tmp/32/mysqld.2.sock) as 'root', connection 'default', attempt 0 ...
|
mysqltest: ... Connected.
|
mysqltest: Start processing test commands from './include/check-testcase.test' ...
|
mysqltest: ... Done processing test commands.
|
--- /dev/shm/10.4/mysql-test/var/32/tmp/check-mysqld_2.result 2019-02-04 09:37:53.989594035 +0200
|
+++ /dev/shm/10.4/mysql-test/var/32/tmp/check-mysqld_2.reject 2019-02-04 09:37:56.357627721 +0200
|
@@ -665,6 +665,7 @@
|
def performance_schema utf8 utf8_general_ci NULL
|
def test latin1 latin1_swedish_ci NULL
|
tables_in_test
|
+t1
|
tables_in_mysql
|
mysql.columns_priv
|
mysql.column_stats
|
|
|
mysqltest: Result length mismatch
|
|
|
not ok
|
The problem is occasionally repeatable by running the test alone:
./mtr --big-test --repeat=100 --parallel=auto rpl.rpl_semi_sync_skip_repl{,,,}
|
Without the patch, this problem does not occur.
Note: I did not test whether the crash recovery now actually executes in the background. That could already be the case. The above patch is only trying to remove a read of every .ibd file when any crash recovery was needed.
It seems that in order to properly fix this, we must get rid of the separate buf_pool->flush_rbt and this code:
/** Complete recovery from a checkpoint. */
|
void
|
recv_recovery_from_checkpoint_finish(void) |
{
|
/* Make sure that the recv_writer thread is done. This is |
required because it grabs various mutexes and we want to
|
ensure that when we enable sync_order_checks there is no
|
mutex currently held by any thread. */
|
mutex_enter(&recv_sys->writer_mutex);
|
|
|
/* Free the resources of the recovery system */ |
recv_recovery_on = false; |
|
|
/* By acquring the mutex we ensure that the recv_writer thread |
won't trigger any more LRU batches. Now wait for currently
|
in progress batches to finish. */
|
buf_flush_wait_LRU_batch_end();
|
|
|
mutex_exit(&recv_sys->writer_mutex);
|
|
|
ulint count = 0;
|
while (recv_writer_thread_active) { |
++count;
|
os_thread_sleep(100000);
|
if (srv_print_verbose_log && count > 600) { |
ib::info() << "Waiting for recv_writer to" |
" finish flushing of buffer pool"; |
count = 0;
|
}
|
}
|
|
|
recv_sys_debug_free();
|
|
|
/* Free up the flush_rbt. */ |
buf_flush_free_flush_rbt();
|
}
|
This buffer pool flush is unnecessarily forcing crash recovery to wait for all changes to be written back to the files. This flush would necessarily happen on the next redo log checkpoint. We must be careful to ensure that buf_page_t::oldest_modification is correctly set during crash recovery. The unnecessary flush happens before this point:
2019-02-04 13:34:57 0 [Note] InnoDB: 128 out of 128 rollback segments are active.
|
2019-02-04 13:34:57 0 [Note] InnoDB: Starting in background the rollback of recovered transactions
|
There is no call to log_checkpoint() before the server has started accepting connections.
So, the main thing that needs to be done seems to be the merging of buf_pool->flush_list and buf_pool->flush_rbt, which should be a good idea on its own merit, to improve the InnoDB page flushing performance.
| Link |
This issue relates to |
| NRE Projects | RM_105_CANDIDATE |
As part of this, we should probably prevent anything from being added to the adaptive hash index before crash recovery has been completed. Alternatively, we should not omit calls to btr_search_drop_page_hash_index(block) while redo log is being applied.
| Link |
This issue relates to |
MDEV-19514 defers change buffer merge to the moment when a user thread is requesting access to the page. There is no need to incur extra I/O during crash recovery or when pages are being subjected to read-ahead.
| Link |
This issue relates to |
In MDEV-18733, we removed the calls to open and read each table if crash recovery was needed. This was safe given that MDEV-14717 made RENAME operations inside InnoDB crash-safe.
| Link |
This issue relates to |
| Link |
This issue relates to |
| Link |
This issue relates to |
I removed the call to buf_page_invalidate() in MDEV-13564 without remembering that I had noticed it being seemingly necessary in this ticket.
While thiru was working on MDEV-19229, he noticed that we are actually performing a dirty read of the TRX_SYS page before reading or applying any redo log. The dirty reads must be removed in MDEV-19229 and deferred to after recv_recovery_from_checkpoint_start() has returned. Until then, we must call buf_pool_invalidate() to work around the bug.
| Link |
This issue is blocked by |
| Link |
This issue relates to |
| Fix Version/s | 10.5 [ 23123 ] | |
| Fix Version/s | 10.4 [ 22408 ] |
| Link |
This issue blocks |
As part of this work, we must remove the variable recv_lsn_checks_on and improve buf_page_check_lsn() so that any pending log records in recv_sys will be considered.
| Link |
This issue is blocked by |
| Status | Open [ 1 ] | In Progress [ 3 ] |
| Link |
This issue is blocked by |
| Description |
InnoDB startup unnecessarily waits for recovered redo log records to be applied to the data files.
In fact, normally while the function trx_sys_init_at_db_start() is executing, the pages that it is requesting from the buffer pool will have any recovered redo log applied to them in the background. Basically, we only need to remove or refactor some calls in the InnoDB server startup. The crash recovery would ‘complete’ at the time of the next redo log checkpoint is written. One of the code pieces that must be removed is this one: {code:diff} commit 5103b38fc3cbc73d4a66a1b21740c4d7498f4a67 Author: Marko Mäkelä <marko.makela@mariadb.com> Date: Wed Nov 15 06:51:19 2017 +0200 Remove one more trace of innodb_file_format innobase_start_or_create_for_mysql(): Remove an unnecessary call that should have been removed as part of commit 0c92794db3026cda03218caf4918b996baab6ba6 when the dirty read of the innodb_file_format tag was removed. diff --git a/storage/innobase/srv/srv0start.cc b/storage/innobase/srv/srv0start.cc index 988ddf1a759..4f8823ef36c 100644 --- a/storage/innobase/srv/srv0start.cc +++ b/storage/innobase/srv/srv0start.cc @@ -2194,13 +2194,6 @@ innobase_start_or_create_for_mysql() return(srv_init_abort(err)); } } else { - /* Invalidate the buffer pool to ensure that we reread - the page that we read above, during recovery. - Note that this is not as heavy weight as it seems. At - this point there will be only ONE page in the buf_LRU - and there must be no page in the buf_flush list. */ - buf_pool_invalidate(); - /* Scan and locate truncate log files. Parsed located files and add table to truncate information to central vector for truncate fix-up action post recovery. */ {code} However, if we apply this patch, crash recovery will start failing. The reason could be that we are accessing the InnoDB system and undo tablespace files before opening the redo logs: {code:c} fil_open_log_and_system_tablespace_files(); ut_d(fil_space_get(0)->recv_size = srv_sys_space_size_debug); err = srv_undo_tablespaces_init(create_new_db); … err = recv_recovery_from_checkpoint_start(flushed_lsn); {code} If we first open the redo log files and then the persistent data files, then there should be no need to invalidate the buffer pool contents. Similarly, later in the startup, we should rewrite or remove recv_recovery_from_checkpoint_finish() so that it will not wait for any page flushing to complete. While doing this, we must also remove the buf_pool_t::flush_rbt and use the normal flushing mechanism that strictly obeys the ARIES protocol for write-ahead logging. |
InnoDB startup unnecessarily waits for recovered redo log records to be applied to the data files.
In fact, normally while the function {{trx_sys_init_at_db_start()}} is executing, the pages that it is requesting from the buffer pool will have any recovered redo log applied to them in the background. Basically, we only need to remove or refactor some calls in the InnoDB server startup. Some of this was performed in The crash recovery would ‘complete’ at the time of the next redo log checkpoint is written. We should rewrite or remove {{recv_recovery_from_checkpoint_finish()}} so that it will not wait for any page flushing to complete. While doing this, we must also remove the {{buf_pool_t::flush_rbt}} and use the normal flushing mechanism that strictly obeys the ARIES protocol for write-ahead logging. |
| Status | In Progress [ 3 ] | Stalled [ 10000 ] |
Here is a simple test case:
--source include/have_innodb.inc
|
--source include/have_sequence.inc
|
|
|
CREATE TABLE t1(a SERIAL, b CHAR(255) NOT NULL, c CHAR(255) NOT NULL) |
ENGINE=InnoDB DEFAULT CHARSET utf8mb4; |
|
|
INSERT INTO t1 SELECT (seq % 256) * 1048576 + (seq / 256),'','' |
FROM seq_1_to_100000; |
--let $shutdown_timeout=0
|
--source include/restart_mysqld.inc
|
SELECT now(); |
SELECT COUNT(*) FROM t1; |
SELECT now(); |
DROP TABLE t1; |
And here is some instrumentation that attempts to artificially delay the last recovery batch by 10 seconds, so that it could finish some time after we have started executing SQL:
diff --git a/storage/innobase/log/log0recv.cc b/storage/innobase/log/log0recv.cc
|
index 5d41ff1fb03..585654028c7 100644
|
--- a/storage/innobase/log/log0recv.cc
|
+++ b/storage/innobase/log/log0recv.cc
|
@@ -2318,6 +2318,11 @@ void recv_apply_hashed_log_recs(bool last_batch)
|
mlog_init.mark_ibuf_exist(mtr);
|
}
|
|
+ if (last_batch) {
|
+ ib::info() << "sleep at the end of recovery batch";
|
+ os_thread_sleep(10000000);
|
+ ib::info() << "end of sleep and recovery batch";
|
+ }
|
recv_sys.apply_log_recs = false;
|
recv_sys.apply_batch_on = false;
|
|
|
The output currently looks like this, for an invocation like this. I thought that it would be a good idea to disable log checkpoints, to slow down recovery further:
./mtr --mysqld=--debug=d,ib_log_checkpoint_avoid innodb.mdev-14481
|
|
10.5 6b5cdd4ff745e3254cb05935bd1efa4b48a29549 |
CREATE TABLE t1(a SERIAL, b CHAR(255) NOT NULL, c CHAR(255) NOT NULL)
|
ENGINE=InnoDB DEFAULT CHARSET utf8mb4;
|
INSERT INTO t1 SELECT (seq % 256) * 1048576 + (seq / 256),'',''
|
FROM seq_1_to_100000;
|
# restart
|
SELECT now();
|
now()
|
2019-12-04 15:41:05
|
SELECT COUNT(*) FROM t1;
|
COUNT(*)
|
100000
|
SELECT now();
|
now()
|
2019-12-04 15:41:06
|
DROP TABLE t1;
|
We would hope the now() time stamps to prove that the SQL was running concurrently with the last crash recovery batch. Currently, that is not the case, but instead the 10-second sleep that our instrumentation introduced is delaying the InnoDB startup:
2019-12-04 15:40:53 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=58294800
|
2019-12-04 15:40:53 0 [Note] InnoDB: Starting a batch to recover 580 pages from redo log.
|
2019-12-04 15:40:53 0 [Note] InnoDB: Starting a batch to recover 311 pages from redo log.
|
2019-12-04 15:40:54 0 [Note] InnoDB: Starting a batch to recover 712 pages from redo log.
|
2019-12-04 15:40:54 0 [Note] InnoDB: Starting final batch to recover 307 pages from redo log.
|
2019-12-04 15:40:54 0 [Note] InnoDB: sleep at the end of recovery batch
|
2019-12-04 15:41:04 0 [Note] InnoDB: end of sleep and recovery batch
|
2019-12-04 15:41:05 0 [Note] InnoDB: 128 rollback segments are active.
|
2019-12-04 15:41:05 0 [Note] InnoDB: Removed temporary tablespace data file: "ibtmp1"
|
2019-12-04 15:41:05 0 [Note] InnoDB: Creating shared tablespace for temporary tables
|
2019-12-04 15:41:05 0 [Note] InnoDB: Setting file './ibtmp1' size to 12 MB. Physically writing the file full; Please wait ...
|
2019-12-04 15:41:05 0 [Note] InnoDB: File './ibtmp1' size is now 12 MB.
|
2019-12-04 15:41:05 0 [Note] InnoDB: 10.5.1 started; log sequence number 63689195; transaction id 35
|
I used to implement a similar feature. just write a note of bug i hitted: during runtime , it may create a new page without reading from disk, so the pending redo log is not applied. If foreground thread modified the page in memory, and after that the background thread may apply redo to it and take it back to older version....
zhaiwx1987, your comment reminds me of MDEV-12699, which avoids unnecessary page reads during crash recovery. If a page is not read into the buffer pool, a change buffer merge (or the deletion of stale buffered changes) may be necessary. We refined that logic further in MDEV-19514.
I think that the scenario that you mention should be prevented if a call to buf_page_create() from other than the recovery code will discard any buffered redo log for the page. Actually, in the scenario, there should have been a MLOG_INIT_FREE_PAGE record (MDEV-15528) for marking the page as free. As soon as it is durably written to the redo log, we can safely remove any buffered redo log for the page. Similarly, if recovery finds a MLOG_INIT_FREE_PAGE record, it can immediately discard any preceding log records for the page.
When we enable recovery in the background, we will also allow buffer pool resizing during recovery. It could be simplest to disallow the buffer pool from shrinking before recovery has been completed. The parsed redo log records are currently stored in the buffer pool, in BUF_BLOCK_STATE_MEMORY blocks.
If we allow recovery with innodb_read_only (MDEV-12700), the recovered redo log records would have to be buffered indefinitely, because the dirty pages would never be written back to the data files. If we allow dirty pages to be evicted from the buffer pool, we must be able to re-apply the records every time the affected page is reloaded to the buffer pool.
| Link |
This issue relates to |
| Due Date | 2020-03-31 |
As part of this task, we must remove or rewrite most conditions on recv_recovery_is_on().
| Fix Version/s | 10.6 [ 24028 ] | |
| Fix Version/s | 10.5 [ 23123 ] |
| Link |
This issue relates to |
As part of this task, we should think what to do about innodb_force_recovery. If recovery is executed on the background, we would no longer be able to abort startup because of a corrupted page. We could still abort because of a corrupted log record.
If innodb_force_recovery is not set, the expectation should be that no data will be lost, and something could be done to fix the corruption (say, mount a file system where a data file was stored) and to restart the recovery. This could imply that innodb_force_recovery=0 (the default setting) must prevent log checkpoints from being executed until everything has been fully recovered. Users could explicitly SET GLOBAL innodb_force_recovery=1 to ‘unblock’ the database.
Executing recovery in the background might raise further the importance of page corruption handling (MDEV-13542).
| Due Date | 2020-03-31 |
The use of the predicate srv_startup_is_before_trx_rollback_phase to disable read-ahead in buf0rea.cc will likely have to be replaced in this task, because we could reset that predicate before the redo log apply completes. In fact, if we are running with innodb_read_only=ON, we could complete the rollback of recovered transactions in the buffer pool while redo log for some other pages might still not have been applied. (In that mode, we would not write anything to the redo log or to the data files; we could recovered pages in the buffer pool.)
| Rank | Ranked higher |
| Link |
This issue is blocked by |
| Link |
This issue is blocked by |
| Fix Version/s | N/A [ 14700 ] | |
| Fix Version/s | 10.6 [ 24028 ] |
| Fix Version/s | 10.7 [ 24805 ] | |
| Fix Version/s | N/A [ 14700 ] |
| Fix Version/s | 10.8 [ 26121 ] | |
| Fix Version/s | 10.7 [ 24805 ] |
Many preparations for this task were already done in MDEV-23855 and some related work.
In the last batch in recv_sys_t::apply(bool last_batch), we would want to sort the buf_pool.flush_list instead of emptying it (buf_flush_sync()). That could possibly be done as a separate bug fix (to speed up startup in 10.5+ when crash recovery is needed).
| Assignee | Thirunarayanan Balathandayuthapani [ thiru ] | Eugene Kosov [ kevg ] |
| Priority | Major [ 3 ] | Critical [ 2 ] |
| Link |
This issue includes |
| Link |
This issue relates to |
| Attachment | Screenshot from 2021-11-26 10-08-41.png [ 60930 ] |
| Attachment | 1.svg [ 60931 ] |
{kind=link}
{kind=link}
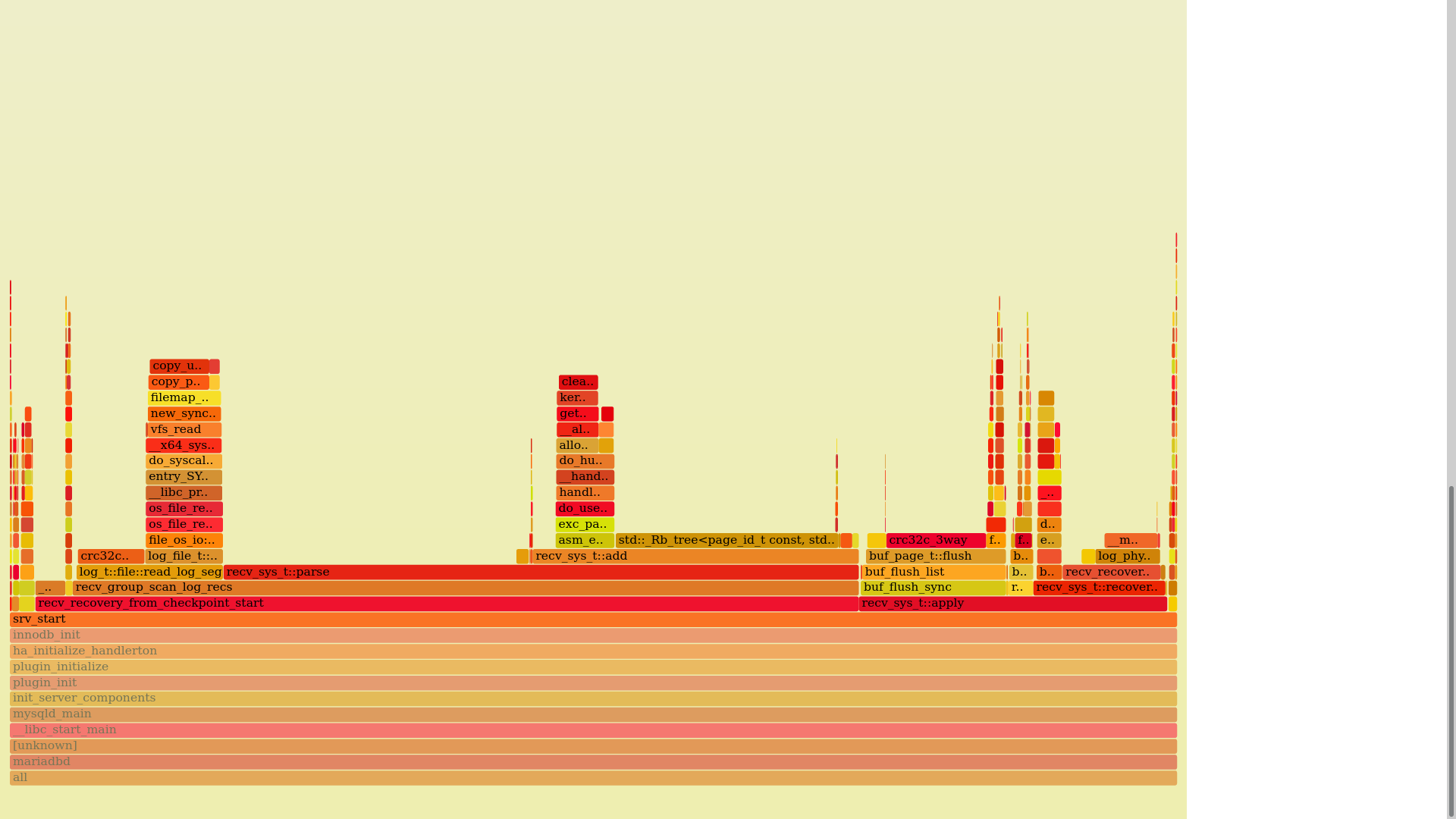
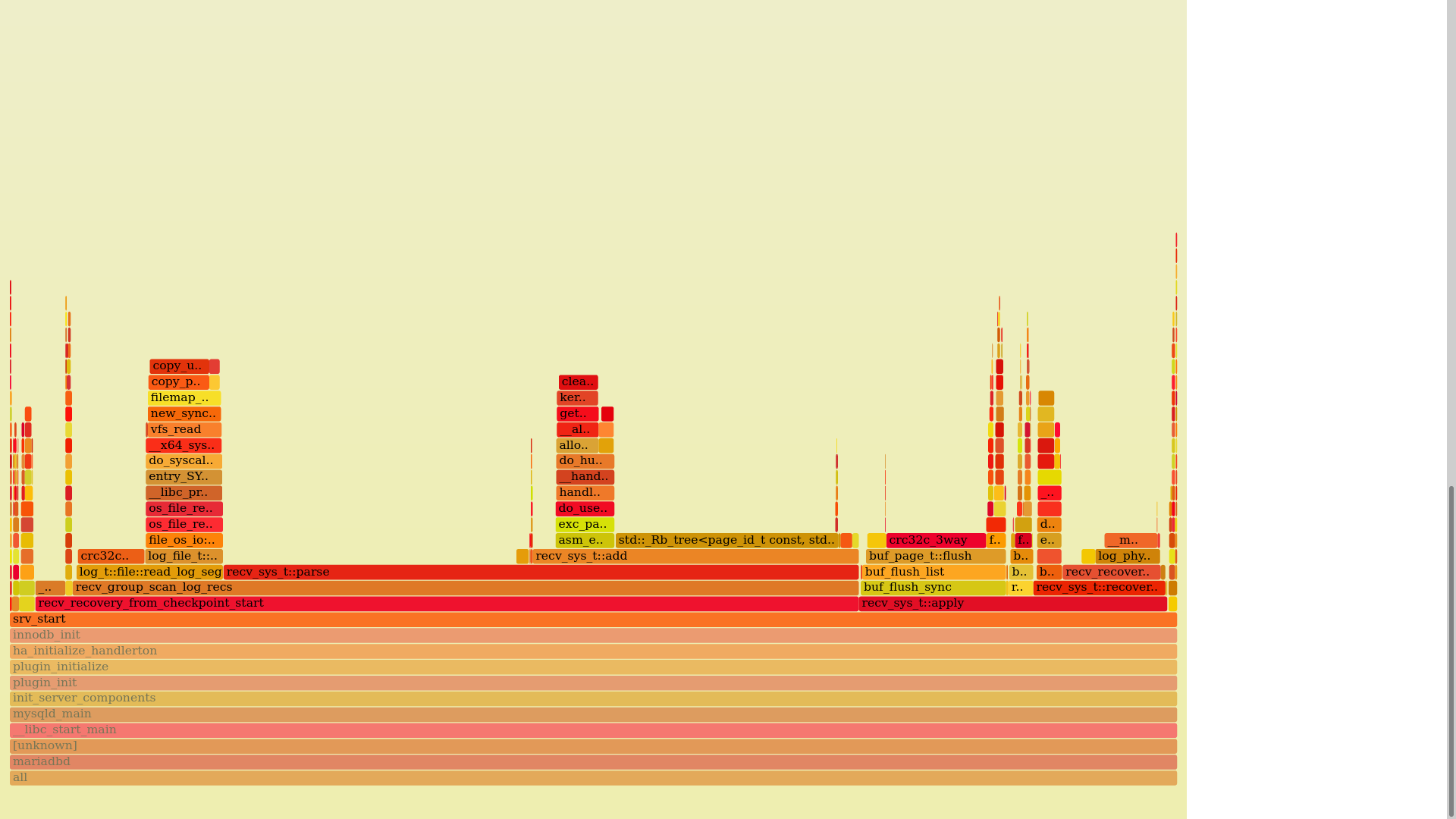
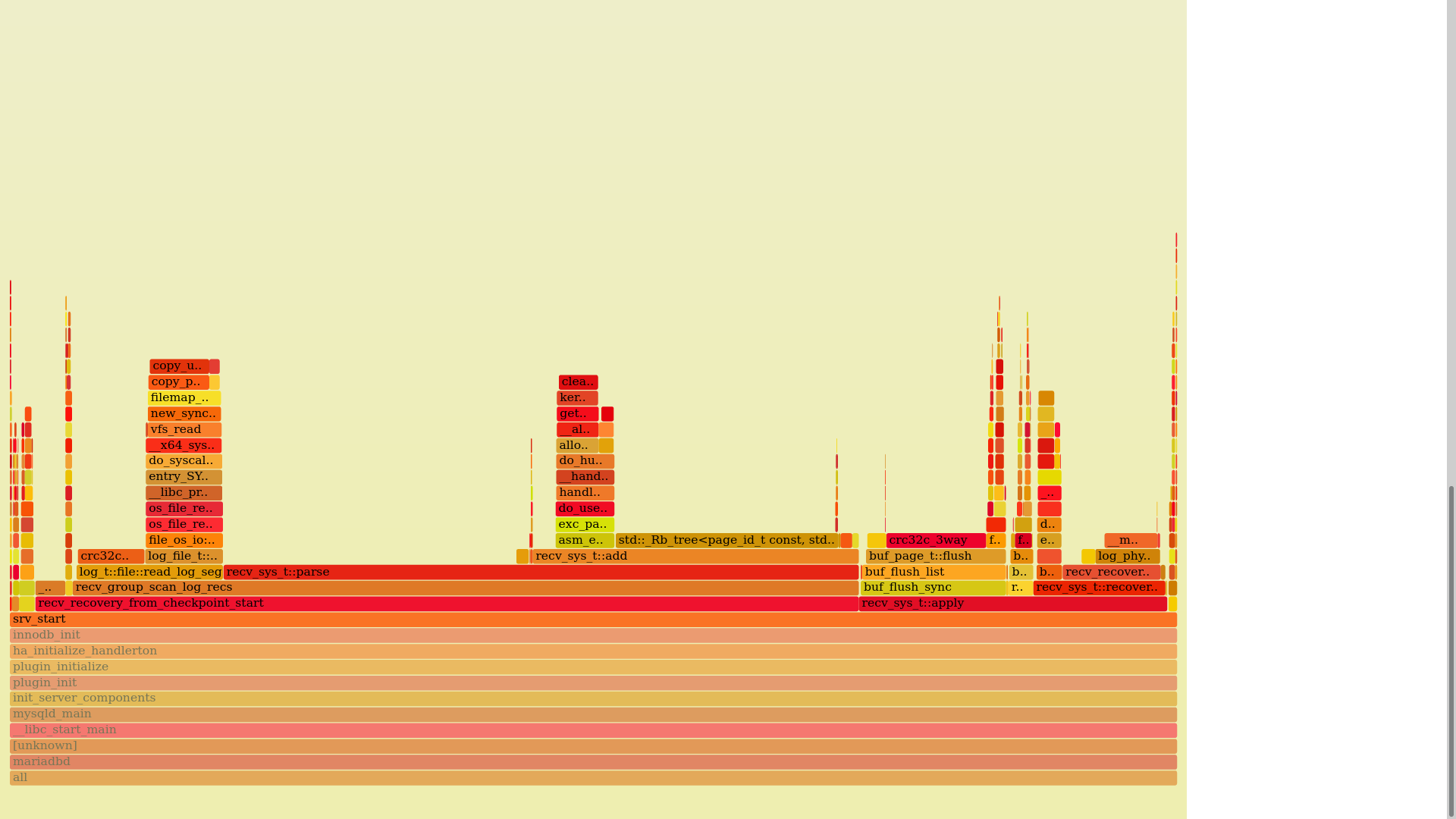
Here is a profiling info for some data. What can be improved?
1) log_file_t::read() copies data from kernel into userspace which takes time. It can be optimized completely by mmap() the whole file.
2) std::map::emplace() inside recv_sys_t::add(). Not surprisingly, searches in a binary tree are slow. I have two ideas on what to do here: use a btree and/or use a small (up to 8 elements) cache. Both approaches require testing because I'm not sure it'll work at all.
3) recv_sys_t::apply() This one I'll try to put in a separate thread.
4) buf_flush_sync() inside recv_sys_t::apply() is MDEV-27022
I think 1) is not a huge issue. Whether you mmap, or not, the biggest problem is bringing data from disk to memory, not the copies between memory and memory. a huge mmap , with tens of GB, of a full file, potentially larger than RAM, might behave hostile to other application running on the same machine. Doing "direct reads", instead of populating filesystem cache, is as good as mmap is. provided you can do direct reads, or use some posix_fadvise, or what not.
The biggest potential is recv_sys_t::parse, including this Rbtree , as I see it.
parallelizing as in 3) , could be good, too
For what it is worth, in MDEV-14425 I am planning to get rid of the recv_sys.buf and simply use the log_sys.buf for parsing the redo log during recovery.
When we have the log in persistent memory, we would mmap the ib_logfile0 for log writes anyway. So, we might simply mmap the whole log_sys.buf to the file at all times. Note: I am not advocating the use of mmap when we are using a normal log file. That would not fly in 32-bit architectures where virtual address space is already scarce.
In more distant future, we might want to experiment with asynchronous reads of the log during recovery (when the log is not stored in persistent memory). The challenge here would be that memory needs to be reserved for the read buffers for a longer period of time. We might want to reserve that memory from the buffer pool, like we currently do for the parsed redo log snippets in recv_sys_t::alloc(). We might allocate all that memory ahead of the asynchronous read. Copying data from the log read buffer to recv_sys.pages seems to be unavoidable, because recv_sys_t::add() would both ‘compact’ and ‘expand’ the data (remove checksums and other ‘framing’, and add log_phys_t framing that imposes alignment constraints).
wlad, I believe that parallelizing recv_sys_t::apply() could bring the most benefit if a large portion of the pages can be recovered without reading them into the buffer pool. A scenario could be that the server was killed during a massive INSERT that was allocating many new pages. (This optimization was first introduced in MDEV-12699.)
It could turn out that most of the time, most recovered pages will have to be read into the buffer pool. In that case, the redo log would be applied in the page read completion callback. I do not expect that parallelizing the recv_read_in_area() calls (submitting the asynchronous read requests) in recv_sys_t::apply() would help much.
During recovery, the buffer pool will be occupied by recv_sys.pages as well as data pages needing recovery. Starting heavy workload concurrently with recovery could cause heavy thrashing due to the small portion of usable buffer pool.
kevg, we would need an interface that allows users to wait for recovery to finish before starting heavy workload.
We will also have to think what to do about loading the ib_buffer_pool. If recovery is needed, maybe we should only process ib_buffer_pool if the user is explicitly waiting for recovery to finish.
| Workflow | MariaDB v3 [ 83949 ] | MariaDB v4 [ 131680 ] |
I put and assertion here and it looks that the code is a dead code. This is not a proof yet, however.
This means that already all CPU-intensive work is done in tpool. And the only thing to optimize is a wait at the end of recv_sys_t::apply(). This wait mostly need to know when to call a cleanup for recovery. The wait + cleanup could be put in a separate thread or the wait could be removed completely and cleanup moved to a log checkpoint. Simply making recv_sys_t::apply() asynchronous results in a races of a buffer pool pages. Also, wait condition should be changed from waiting for zero pending reads to something else.
Yes, that code path could indeed be unreachable. In case a background read-ahead is concurrently completing for this same page, that read should be protected by a page X-latch and IO-fix, which will not be released before buf_page_read_complete() will have invoked recv_recover_page(). So, there cannot possibly be any changes to apply. If this analysis is correct, we could remove quite a bit of code without any ill effect:
diff --git a/storage/innobase/log/log0recv.cc b/storage/innobase/log/log0recv.cc
|
index 8e79a9b7e87..28010af4f7a 100644
|
--- a/storage/innobase/log/log0recv.cc
|
+++ b/storage/innobase/log/log0recv.cc
|
@@ -2713,27 +2713,7 @@ void recv_sys_t::apply(bool last_batch)
|
}
|
continue;
|
case page_recv_t::RECV_NOT_PROCESSED:
|
- mtr.start();
|
- mtr.set_log_mode(MTR_LOG_NO_REDO);
|
- if (buf_block_t *block= buf_page_get_low(page_id, 0, RW_X_LATCH,
|
- nullptr, BUF_GET_IF_IN_POOL,
|
- __FILE__, __LINE__,
|
- &mtr, nullptr, false))
|
- {
|
- buf_block_dbg_add_level(block, SYNC_NO_ORDER_CHECK);
|
- recv_recover_page(block, mtr, p);
|
- ut_ad(mtr.has_committed());
|
- }
|
- else
|
- {
|
- mtr.commit();
|
- recv_read_in_area(page_id);
|
- break;
|
- }
|
- map::iterator r= p++;
|
- r->second.log.clear();
|
- pages.erase(r);
|
- continue;
|
+ recv_read_in_area(page_id);
|
}
|
|
goto next_page; |
I filed MDEV-27610 for the removing the unnecessary wait and the dead code.
I thought that my patch might need to be revised further, to replace the goto next_page with p++, but that would cause widespread test failures. It turns out that recv_read_in_area(page_id) will transition the current block as well as possibly some following blocks from RECV_NOT_PROCESSED to RECV_BEING_READ. So, the goto next_page was doing the right thing.
| Link |
This issue relates to |
| Fix Version/s | 10.9 [ 26905 ] | |
| Fix Version/s | 10.8 [ 26121 ] |
| Assignee | Eugene Kosov [ kevg ] | Vladislav Lesin [ vlad.lesin ] |
| Fix Version/s | 10.10 [ 27530 ] | |
| Fix Version/s | 10.9 [ 26905 ] |
| Priority | Critical [ 2 ] | Major [ 3 ] |
| Fix Version/s | 10.11 [ 27614 ] | |
| Fix Version/s | 10.10 [ 27530 ] |
| Fix Version/s | 10.12 [ 28320 ] | |
| Fix Version/s | 10.11 [ 27614 ] |
| Description |
InnoDB startup unnecessarily waits for recovered redo log records to be applied to the data files.
In fact, normally while the function {{trx_sys_init_at_db_start()}} is executing, the pages that it is requesting from the buffer pool will have any recovered redo log applied to them in the background. Basically, we only need to remove or refactor some calls in the InnoDB server startup. Some of this was performed in The crash recovery would ‘complete’ at the time of the next redo log checkpoint is written. We should rewrite or remove {{recv_recovery_from_checkpoint_finish()}} so that it will not wait for any page flushing to complete. While doing this, we must also remove the {{buf_pool_t::flush_rbt}} and use the normal flushing mechanism that strictly obeys the ARIES protocol for write-ahead logging. |
InnoDB startup unnecessarily waits for recovered redo log records to be applied to the data files. In fact, normally while the function {{trx_sys_init_at_db_start()}} is executing, the pages that it is requesting from the buffer pool will have any recovered redo log applied to them in the background. Basically, we only need to remove or refactor some calls in the InnoDB server startup. Some of this was performed in The crash recovery would ‘complete’ at the time of the next redo log checkpoint is written. We should rewrite or remove {{recv_recovery_from_checkpoint_finish()}} so that it will not wait for any page flushing to complete. While doing this, we must also remove the {{buf_pool_t::flush_rbt}} and use the normal flushing mechanism that strictly obeys the ARIES protocol for write\-ahead logging. |
| Link |
This issue relates to |
| Status | Stalled [ 10000 ] | In Progress [ 3 ] |
It could make sense to make this an opt-in feature, by introducing a Boolean global parameter:
- If the server is started up with innodb_recover_in_background=ON (disabled by default), the last recovery batch would occur while SQL commands are accepted.
- An explicit statement SET GLOBAL innodb_recover_in_background=OFF could be executed to ensure that the recovery has been completed, before starting "serious" workload. This would free up the buffer pool space that was allocated for redo log records during recovery.
| Fix Version/s | 11.1 [ 28549 ] | |
| Fix Version/s | 11.0 [ 28320 ] |
| Link |
This issue is blocked by |
| Link |
This issue is blocked by |
| Description |
InnoDB startup unnecessarily waits for recovered redo log records to be applied to the data files. In fact, normally while the function {{trx_sys_init_at_db_start()}} is executing, the pages that it is requesting from the buffer pool will have any recovered redo log applied to them in the background. Basically, we only need to remove or refactor some calls in the InnoDB server startup. Some of this was performed in The crash recovery would ‘complete’ at the time of the next redo log checkpoint is written. We should rewrite or remove {{recv_recovery_from_checkpoint_finish()}} so that it will not wait for any page flushing to complete. While doing this, we must also remove the {{buf_pool_t::flush_rbt}} and use the normal flushing mechanism that strictly obeys the ARIES protocol for write\-ahead logging. |
InnoDB startup unnecessarily waits for recovered redo log records to be applied to the data files.
In fact, normally while the function {{trx_sys_init_at_db_start()}} is executing, the pages that it is requesting from the buffer pool will have any recovered redo log applied to them in the background. Basically, we only need to remove or refactor some calls in the InnoDB server startup. Some of this was performed in The crash recovery would ‘complete’ at the time of the next redo log checkpoint is written. We should rewrite or remove -{{recv_recovery_from_checkpoint_finish()}}- {{recv_sys.apply(true)}} so that -it will not wait for any page flushing to complete- (already done in |
This is fundamentally conflicting with the recovery performance improvements that I implemented in MDEV-29911. Basically, MDEV-29911 is allocating most of the available buffer pool for log records, to reduce I/O traffic for data pages. This means that while the final recovery batch is running, only a tiny buffer pool might be available to users. Because recovery is multi-threaded, the most part of recovery time should actually be related to parsing and storing log records (in a single thread), and actually applying the log to buffer pool pages is fast (especially when innodb_read_io_threads is set to a high value).
I do not think that implementing recovery in background would add that much value, compared to the complexity of implementing and testing this.
| issue.field.resolutiondate | 2023-04-12 14:02:22.0 | 2023-04-12 14:02:22.471 |
| Fix Version/s | N/A [ 14700 ] | |
| Fix Version/s | 11.1 [ 28549 ] | |
| Assignee | Vladislav Lesin [ vlad.lesin ] | Marko Mäkelä [ marko ] |
| Resolution | Won't Do [ 10201 ] | |
| Status | In Progress [ 3 ] | Closed [ 6 ] |
| Link |
This issue relates to |
If the aim of this task is to shorten the downtime after a crash, then as noted in
MDEV-9843, we should also remove the consistency checks of all .ibd files when crash recovery is needed.