Details
-
Task
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Won't Do
Description
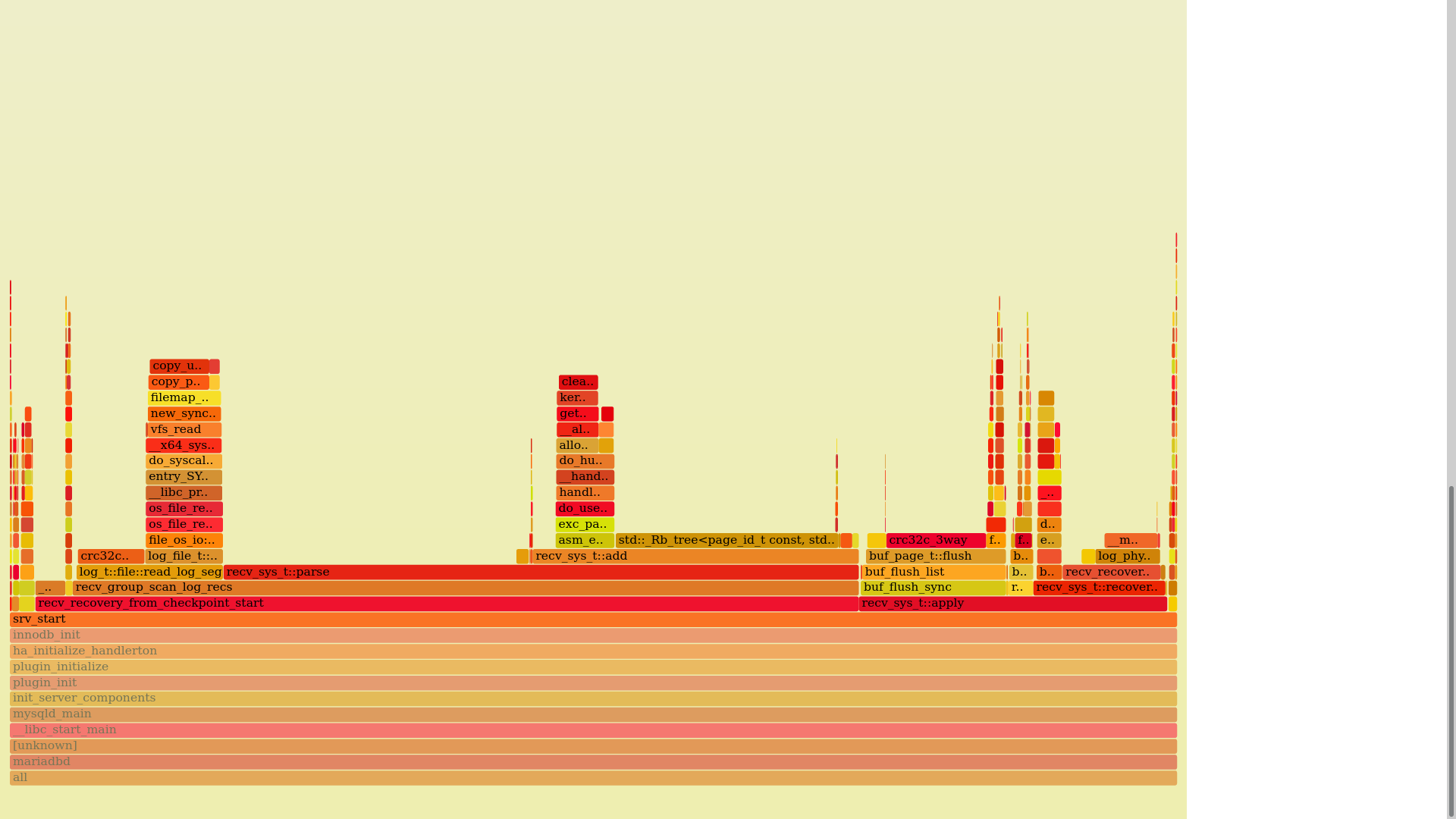
InnoDB startup unnecessarily waits for recovered redo log records to be applied to the data files.
In fact, normally while the function trx_sys_init_at_db_start() is executing, the pages that it is requesting from the buffer pool will have any recovered redo log applied to them in the background.
Basically, we only need to remove or refactor some calls in the InnoDB server startup. Some of this was performed in MDEV-19514 and MDEV-21216.
The crash recovery would ‘complete’ at the time of the next redo log checkpoint is written.
We should rewrite or remove recv_recovery_from_checkpoint_finish() recv_sys.apply(true) so that it will not wait for any page flushing to complete (already done in MDEV-27022). While doing this, we must also remove the buf_pool_t::flush_rbt (removed in MDEV-23399) and use the normal flushing mechanism that strictly obeys the ARIES protocol for write-ahead logging (implemented in MDEV-24626).
Attachments
{kind=link}
Issue Links
- blocks
-
MDEV-12700 Allow innodb_read_only startup without prior slow shutdown
-
- Closed
-
- includes
-
-
- Closed
-
- is blocked by
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
- relates to
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-