Details
-
Bug
-
Status: Closed (View Workflow)
-
 Blocker
Blocker
-
Resolution: Fixed
-
10.5(EOL), 10.6, 10.11, 11.0(EOL), 11.1(EOL), 11.2(EOL), 11.3(EOL)
-
Ubuntu 18.04 on AMD64
Ubuntu 20.04 on AMD64
Description
After implementing MDEV-32757, we are seeing a performance anomaly with innodb_undo_log_truncate=ON. The server is not actually hung or deadlocked (it will eventually recover), but buf_pool.mutex is being occupied for an extremely long time (several minutes).
- trx_purge_truncate_history() writes the message InnoDB: Truncating and is about to truncate an undo log tablespace.
- trx_purge_truncate_history() is busy-looping in a scan of buf_pool.flush_list because one of the pages belonging to the undo tablespace is write-fixed.
- During the time trx_purge_truncate_history() releases and re-acquires buf_pool.flush_list_mutex, buf_flush_page_cleaner (which is holding buf_pool.mutex in buf_do_flush_list_batch()) cannot grab it, in this Ubuntu 18.04 version of GNU libc and Linux kernel (4.15.0-112-generic). This could be similar to
MDEV-31343andMDEV-30180, which could only be reproduced in the same particular environment. - Most threads are blocked because the buf_flush_page_cleaner thread is holding buf_pool.mutex.
There is some indication that buf_flush_list_batch() may be making some progress (writing out some pages), but it would be extremely slow.
Attachments
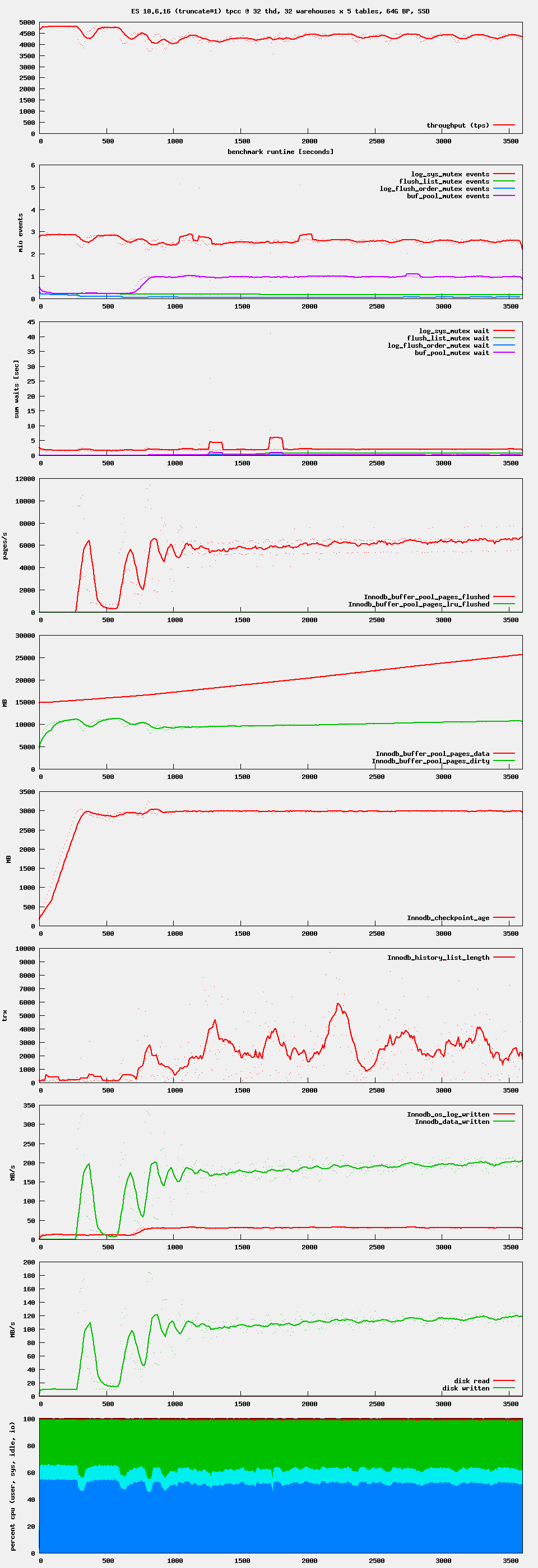
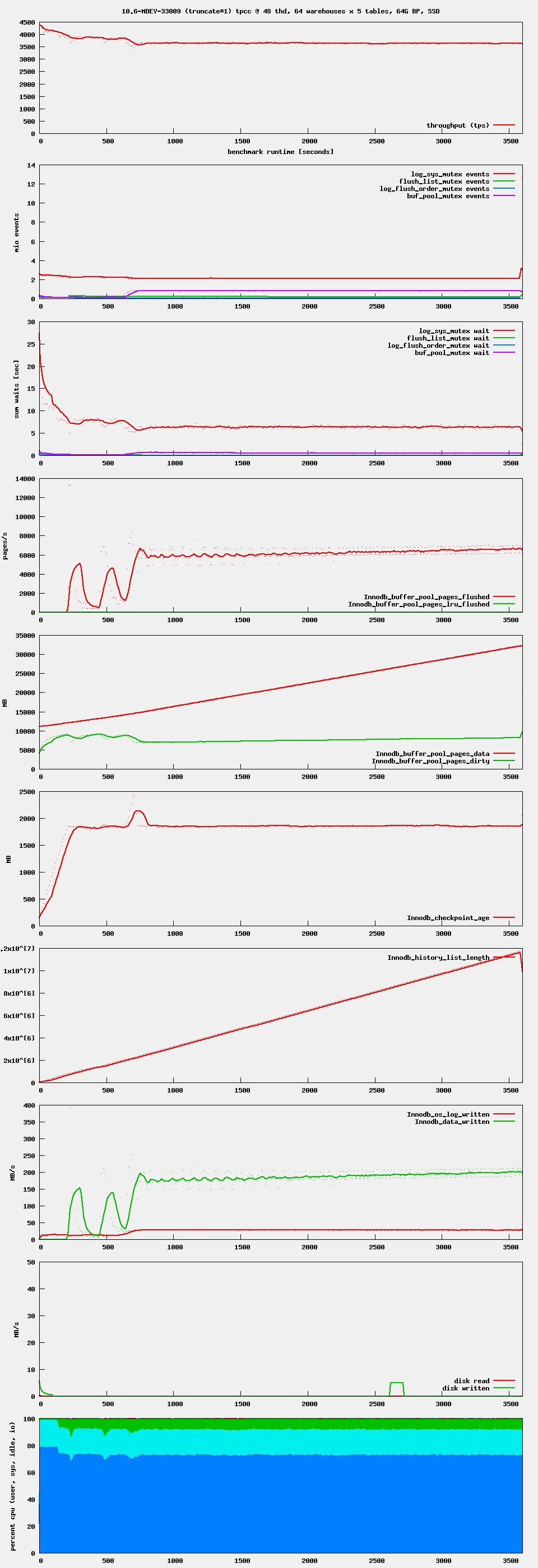

Issue Links
- relates to
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
