Details
-
New Feature
-
Status: Stalled (View Workflow)
-
 Minor
Minor
-
Resolution: Unresolved
-
None
-
None
Description
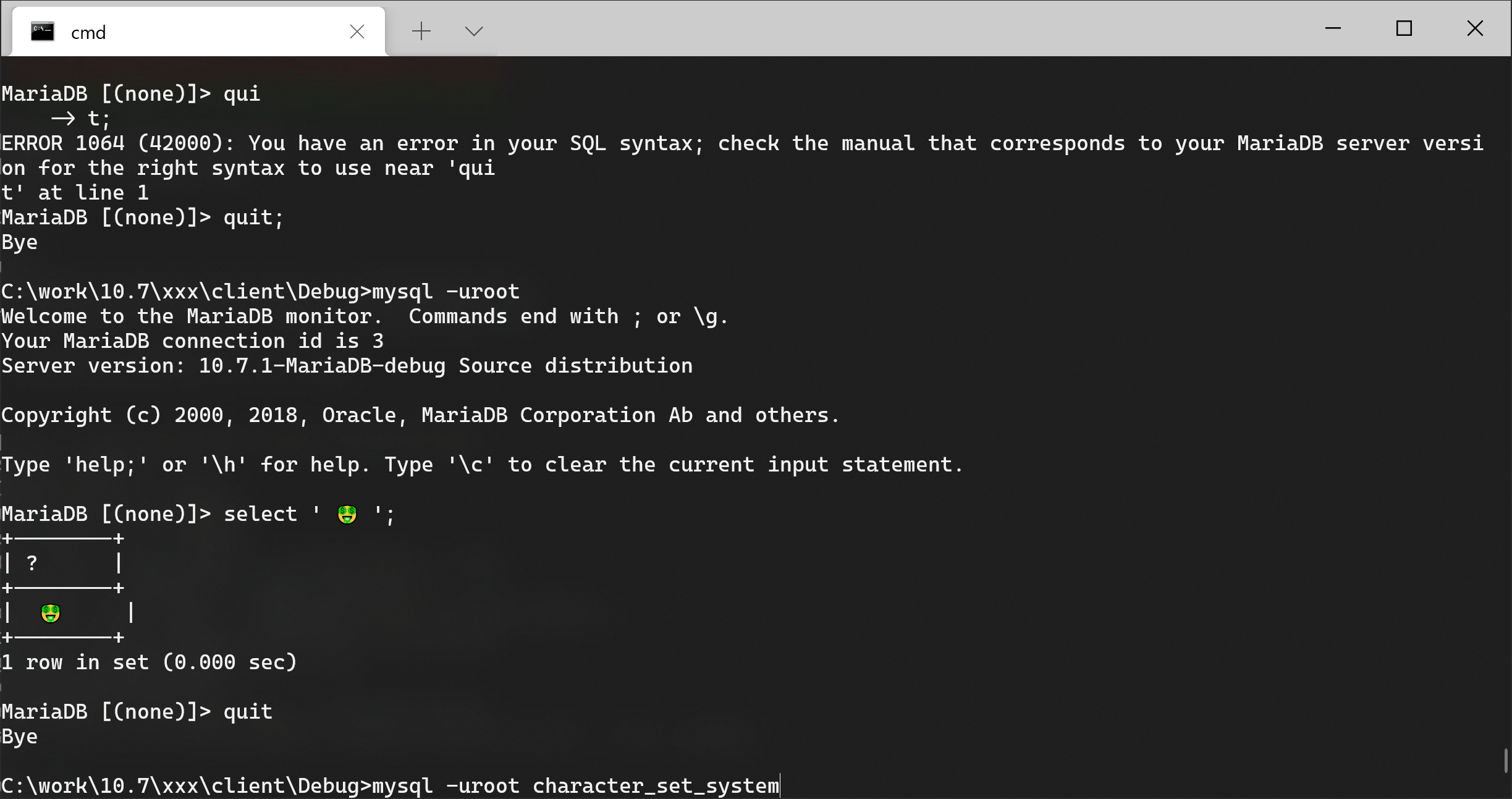
Identifier names can't contain characters outside of BMP, i.e they are restricted to utf8mb3
Here is a relevant part of Slack discussion on why it is so, and on possible fix
... discussion on character_set_system and why it is utf8mb3...
|
....
|
bar Oct 13th, 2021 at 4:23 PM
|
@wlad yes, it's hard-coded. I think the biggest problem is to implement table-name-to-file-name encoding for non-BMP characters. Should be doable but needs some time.
|
5 replies
|
|
|
wlad 3 months ago
|
so, a surrogate pair won't do? like, @d801@dc37
|
|
|
bar 3 months ago
|
for characters that do not have lower/upper variants, it will do.
|
|
|
bar 3 months ago
|
It will actually do for characters that have lower/upper variants as well.
|
|
|
bar 3 months ago
|
Thanks for the good idea.
|
Table name to file name extensions overview
We need to extend the encoding to support:
- new case folding in the BMP range appeared between Unicode-3.0.0 (used in the first version of the encoding) and Unicode-14.0.0 (the current version in MariaDB).
- non-BMP characters in the range U+010000 to U+10FFFF without case folding
- non-BMP characters in the range U+010000 to U+10FFFF with case folding
Various proposals go in separate comments below.
Unicode planes allowed in identifiers
As of version 14.0.0 (and 16.0.0) Unicode plane assignment looks as follow:
PlaneN Code Range Abbr Name
|
------ ------------ ---- --------------------------------------
|
0 0000-FFFF BMP Basic Multilingual Plane
|
1 10000-1FFFF SMP Supplementary Multilingual Plane
|
2 20000-2FFFF SIP Supplementary Ideographic Plane
|
3 30000-3FFFF TIP Tertiary Ideographic Plane
|
4-13 40000-DFFFF --- unassigned
|
14 E0000-EFFFF SSP Supplementary Special-purpose Plane
|
15-16 F0000-10FFFF SPUA-A/B Supplementary Private Use Area planes
|
It is an open question whether we should support unassigned planes in identifiers (and in table file name encoding), or should limit to assigned planes only.
Characters with unsafe casefolding
Since the version 3.0.0, Unicode added casefolding rules for a few characters which is not round trip safe: UPPER(ch)<>UPPER(LOWER(ch))
These characters can be extracted using the following script:
CREATE OR REPLACE VIEW v1 AS |
SELECT
|
seq,
|
char(seq using utf32) collate utf32_uca1400_ai_ci AS ch |
FROM seq_1_to_1114111; |
|
|
SELECT
|
ch,
|
hex(ch) AS cu, |
upper(ch) AS u, |
hex(upper(ch)) AS uc, |
upper(lower(ch)) u2, |
hex(upper(lower(ch))) AS u2c |
FROM v1 |
WHERE upper(ch) collate utf32_bin<>upper(lower(ch)) collate utf32_bin; |
+------+----------+------+----------+------+----------+
|
| ch | cu | u | uc | u2 | u2c |
|
+------+----------+------+----------+------+----------+
|
| İ | 00000130 | İ | 00000130 | I | 00000049 | LATIN CAPITAL LETTER I WITH DOT ABOVE
|
| ϴ | 000003F4 | ϴ | 000003F4 | Θ | 00000398 | GREEK CAPITAL THETA SYMBOL
|
| ẞ | 00001E9E | ẞ | 00001E9E | ß | 000000DF | LATIN CAPITAL LETTER SHARP S
|
| Ω | 00002126 | Ω | 00002126 | Ω | 000003A9 | OHM SIGN
|
| K | 0000212A | K | 0000212A | K | 0000004B | KELVIN SIGN
|
| Å | 0000212B | Å | 0000212B | Å | 000000C5 | ANGSTROM SIGN
|
+------+----------+------+----------+------+----------+
|
Let's consider this pair as an example:
- UPPER(U+2126 OHM SIGN) = U+2126 OHM SIGN
- UPPER(LOWER(U+2126 OHM SIGN)) = U+03A9 GREEK CAPITAL LETTER OMEGA
There are two options how to encode these characters
- As not having case folding. It will preserve the exact character OHM SIGN. But OHM SIGN and GREEK SMALL LETTER OMEGA will be two distinct characters even on a case insensitive file system.
- As having case folding. In this case OHM SIGN will be replaced GREEK CAPITAL LETTER OMEGA. It will equal to GREEK SMALL LETTER OMEGA on a case insensitive file system.
Attachments
Issue Links
- is blocked by
-
MDEV-30556 UPPER() returns an empty string for U+0251 in Unicode-5.2.0+ collations for utf8
-

- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
MDEV-31340 Remove MY_COLLATION_HANDLER::strcasecmp()
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Stalled
-
- relates to
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
