Details
-
Bug
-
Status: Closed (View Workflow)
-
 Blocker
Blocker
-
Resolution: Fixed
-
10.11, 11.4, 11.8
-
Related to performance
-
In multi-threaded write-heavy workloads, buf_pool.flush_list_mutex could become a point of contention.
Description
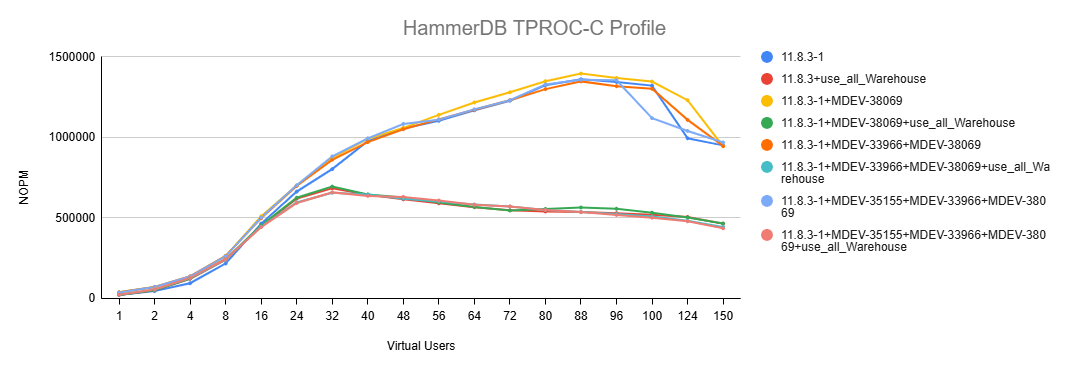
rahulraj has identified a regression that is apparently caused by MDEV-35155, which was contributed by alessandro.vetere.
I would say that the real cause is older, but MDEV-35155 contributed to finding this bottleneck. When the MDEV-35155 fix is present, we would observe that buf_flush_ahead() in mtr_t::commit() is waiting for buf_pool.flush_list_mutex, to increase the efforts of the buf_flush_page_cleaner thread.
Why would the buf_pool.flush_list_mutex be so contended? For one set of runs with performance_schema enabled, the MAX_TIMER_WAIT for wait/synch/mutex/innodb/flush_list_mutex was 69,715,544,080 for most part of a run, and 80,284,902,880 for the case with 150 concurrent virtual users. If that is in nanoseconds, 69.7 or 80.3 seconds would feel unbelievable or totally unacceptable.
I would like to note that neither buf_pool.mutex nor buf_pool.flush_list_mutex are normally being held or acquired when a page write is initiated in buf_page_t::flush() or completed in buf_page_write_complete(). The latter function would only acquire buf_pool.mutex in order to evict a page that belongs to the temporary tablespace.
Only if there are lots of blocks to "lazily evict" from buf_pool.flush_list (MDEV-26010), we’d hold buf_pool.flush_list_mutex for a long time. We implemented some logic elsewhere to avoid hogging buf_pool.mutex (MDEV-26827):
|
buf_flush_LRU_list_batch() |
if (!bpage->oldest_modification()) |
{
|
evict:
|
if (state != buf_page_t::FREED && |
(state >= buf_page_t::READ_FIX || (~buf_page_t::LRU_MASK & state)))
|
continue; |
if (UNIV_UNLIKELY(to_withdraw != 0)) |
to_withdraw= buf_flush_LRU_to_withdraw(to_withdraw, *bpage);
|
buf_LRU_free_page(bpage, true); |
++n->evicted;
|
if (UNIV_LIKELY(scanned & 31)) |
continue; |
mysql_mutex_unlock(&buf_pool.mutex);
|
reacquire_mutex:
|
mysql_mutex_lock(&buf_pool.mutex);
|
continue; |
}
|
On every 32th iteration where this function is freeing a least-recently-used block, it will release and reacquire buf_pool.mutex. We are missing such logic for buf_pool.flush_list_mutex near the continue below:
|
buf_do_flush_list_batch() |
for (buf_page_t *bpage= UT_LIST_GET_LAST(buf_pool.flush_list); |
bpage && len && count < max_n; ++scanned, len--)
|
{
|
const lsn_t oldest_modification= bpage->oldest_modification(); |
if (oldest_modification >= lsn) |
break; |
ut_ad(bpage->in_file());
|
|
|
{
|
buf_page_t *prev= UT_LIST_GET_PREV(list, bpage);
|
|
|
if (oldest_modification == 1) |
{
|
clear:
|
buf_pool.delete_from_flush_list(bpage);
|
skip:
|
bpage= prev;
|
continue; |
}
|
If there is a lot of “garbage” (clean blocks that are here being lazily removed from buf_pool.flush_list), the buf_pool.flush_list_mutex could be monopolized for a long time. This should be fairly simple to fix.
Attachments
Issue Links
- blocks
-
-

- Stalled
-
- is caused by
-
MDEV-25113 Reduce effect of parallel background flush on select workload
-

- Closed
-
-
-
- Closed
-
- relates to
-
-
- Closed
-
-
-
- Closed
-
