Details
-
New Feature
-
Status: Open (View Workflow)
-
 Major
Major
-
Resolution: Unresolved
-
None
-
None
-
None
Description
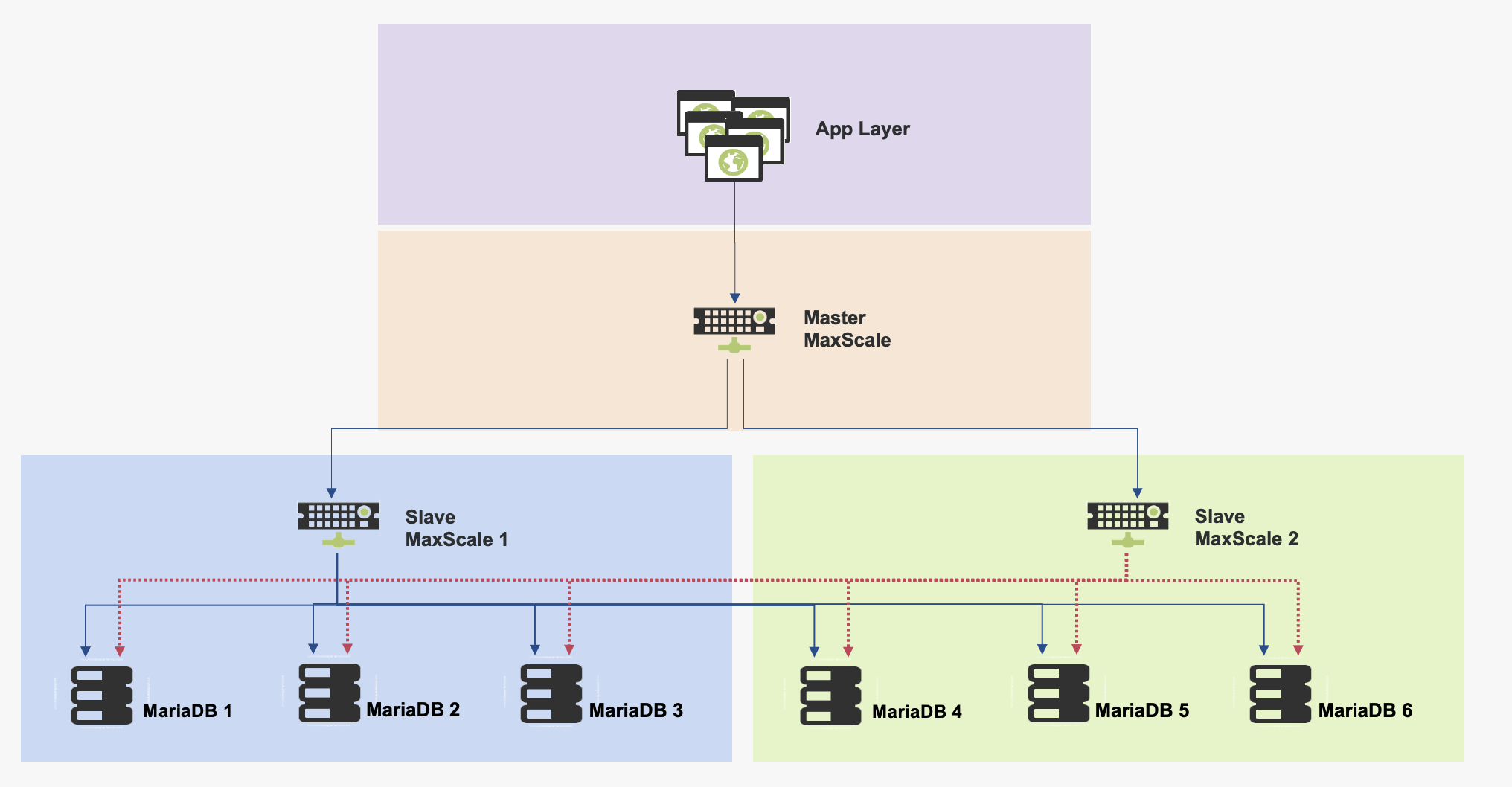
Implement a mechanism that implements region awareness in Maxscale and fulfills the following needs:
- A primary cluster should be able to fail over to a secondary DR cluster in a manner that does not cause split-brain scenarios to occur.
- The failover should have the option of being sticky: if you failed over to the DR cluster, do not fall back automatically.
- The traffic from all MaxScales must flow into the correct cluster at all times.
- All of this must be done in a way that prevents diverging histories from occurring.
Original title: Support Cascading MaxScale Nodes
Original description:
Create new MaxScaleMonitor similar to MariaDBMonitor that allows for monitoring and failover of Cascading maxscale nodes. Top level MaxScale node(s) should monitor downstream MaxScale node health and control traffic to MaxScale nodes. Downstream MaxScale nodes should handle fail over and traffic to database nodes.
Requirements:
- MaxScale should be able to monitor the health of downstream MaxScale nodes and failover accordingly.
- Failover should have the option of being sticky - meaning if you failed over to a DR, do not fall back automatically
- Would be nice to have "region awareness" or be conscious of routing to MaxScale in same region as current primary/master database node
- This should all be viewable and configurable in the GUI
Attachments
{kind=link}
Issue Links
- relates to
-
-

- Closed
-