Details
-
Bug
-
Status: Stalled (View Workflow)
-
 Critical
Critical
-
Resolution: Unresolved
-
10.5(EOL), 10.6, 10.7(EOL), 10.8(EOL), 10.9(EOL), 10.10(EOL), 10.11, 11.0(EOL), 11.1(EOL), 11.2(EOL), 11.3(EOL), 11.4, 11.5(EOL), 11.6(EOL)
-
ubuntu 22.04
-
Related to performance
-
Q3/2025 Maintenance, Q4/2026 Server Maintenance
Description
While I haven't seen significant performance regressions when comparing modern MariaDB (11.4, 10.11) with older MariaDB via sysbench with low concurrency workloads (see here). I have seen perf regressions once I use workloads with some concurrency.
This will take a few days to properly document.
From a server with 8 cores and sysbench run with 4 threads ...
- the numbers in the table are the throughput relative to MariaDB 10.2.44 (x.ma100244_rel.z11a_bee.pk1) where 1.0 means the same, < 1.0 means a regression and > 1.0 means an improvement
If I use 0.8 as a cutoff, meaning some version gets less than 80% of the throughput relative to MariaDB 10.2, then from column 6 (col-6) the problem microbenchmarks are:
- update-index_range=100, relative throughput is 0.25 in 11.4.1, problem arrives in 10.3
- update-one_range=100, relative throughput is 0.65 in 11.4.1, problem arrives in 10.6
- write-only_range=10000 , relative throughput is 0.77 in 11.4.1, problem arrives in 10.3.
Next step for this is to get flamegraphs and maybe PMP stacks.
The table relies on fixed width fonts to be readable but the "preformatted" option in JIRA doesn't do what I want it to do so the data is here
Next up is a server with 2 sockets and 12 cores/socket and the benchmark was run with 16 threads. The results are here. Again, using 0.8 as a cutoff and looking at col-6 (MariaDB 11.4.1) the problem microbenchmarks are:
- insert_range=100, relative throughput is 0.73 in 11.4.1, there are gradual regressions starting in 10.3, but the largest are from 10.11 and 11.4
- update-index_range=100, relative throughput is 0.18 in 11.4.1, problem starts in 10.5 and 10.11->11.4 is the biggest drop
- update-inlist_range=100, relative thoughput is 0.56 in 11.4.1, problem is gradual from 10.3 through 11.4
- update-nonindex_range=100, relative throughput is 0.69 in 11.4.1, problems arrive in 10.11 and 11.4
- update-one_range=100, relative throughput is 0.61 in 11.4.1, problem arrives in 10.6
- update-zipf_range=100, relative throughput is 0.75 in 11.4.1, problem arrives in 11.4
- write-only_range=10000, relative throughput is 0.59 in 11.4.1, problems arrive in 10.11 and 11.4
Finally a server with 32 cores (AMD Threadripper) and the benchmark was run with 24 threads. The results are here and the problem microbenchmarks are:
- points-notcovered-pk_range=100, relative throughput is 0.65 in 11.4.1, problem arrives in 10.5
- points-notcovered-si_range=100, relative throughput is 0.77 in 11.4.1, problem arrives in 10.5
- random-points_range=1000, relative throughput is 0.65 in 11.4.1, problem arrives in 10.5
- random-points_range=100, relative throughput is 0.65 in 11.4.1, problem arrives in 10.5
- range-notcovered-si_range=100, relative throughput is 0.59 in 11.4.1, problem arrives in 10.5
- read-write_range=10, relative throughput is 0.79 in 11.4.1, problem arrives in 10.11
- update-index_range=100, relative throughput is 0.64 in 11.4.1, problem arrives in 10.11 and 11.4
- update-inlist_range=100, relative throughput is 0.61 in 11.4.1, problem arrives in 10.3, 10.5, 10.11
- write-only_range=10000, relative throughput is 0.75 in 11.4.1, problem arrives in 10.11, 11.4
At this point my hypothesis is that the problem is from a few changes to InnoDB but I need more data to confirm or deny that.
On the 24-core server (2 sockets, 12 cores/socket) I repeated sysbench for 1, 4, 8, 12, 16 and 18 threads. And then on the 32-core server I repeated it for 1, 4, 8, 12, 16, 20 and 24 threads. The goal was to determine at which thread count the regressions become obvious. Alas, I only used a subset of the microbenchmarks to get results in less time. Another run with more microbenchmarks is in progress.
The results will be in comments to follow.
Attachments

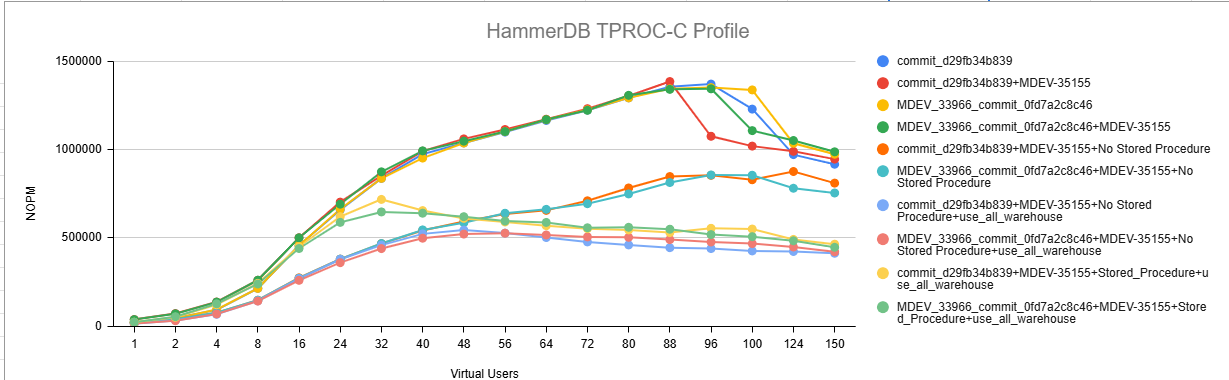

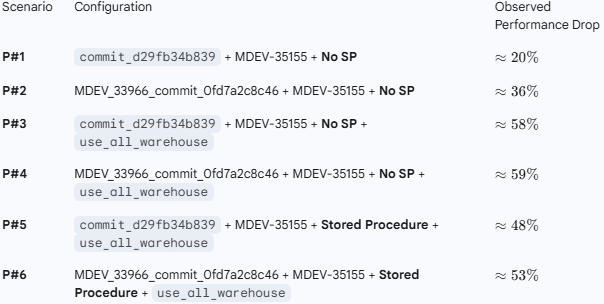
Issue Links
- blocks
-
MDEV-37924 buf_pool.mutex contention under I/O-limited OLTP workload
-
- In Progress
-
- is blocked by
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
- is caused by
-
MDEV-15058 Remove multiple InnoDB buffer pool instances
-
- Closed
-
- is part of
-
-
- In Progress
-
- relates to
-
-

- Stalled
-
-
-
- Stalled
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Open
-
-
-
- Closed
-
-
-
- Open
-
-
SAMU-332 Loading...

{kind=link}