Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Fixed
-
10.8(EOL), 10.9(EOL), 10.10(EOL), 10.11, 11.0(EOL), 11.1(EOL), 11.2(EOL), 11.3(EOL), 11.4
-
GNU/Linux, NUMA on Intel Xeon
Description
steve.shaw@intel.com is reporting that write intensive workloads on a NUMA system end up spending a lot of time in native_queued_spin_lock_slowpath.part.0 in the Linux kernel. He has provided a patch that adds a user-space spinlock around the calls to mtr_t::do_write() and is significantly improving throughput at larger numbers of concurrent connections in his test environment.
As far as I can tell, that patch would only allow one mtr_t::do_write() call to proceed at a time, and thus make waits on log_sys.latch extremely unlikely. But that would also seem to ruin part of what MDEV-27774 achieved.
If I understood it correctly, the idea would be better implemented at a slightly lower level, to allow maximum concurrency:
diff --git a/storage/innobase/mtr/mtr0mtr.cc b/storage/innobase/mtr/mtr0mtr.cc
|
index b819022fec6..884bb5af5c1 100644
|
--- a/storage/innobase/mtr/mtr0mtr.cc
|
+++ b/storage/innobase/mtr/mtr0mtr.cc
|
@@ -1052,7 +1052,7 @@ std::pair<lsn_t,mtr_t::page_flush_ahead> mtr_t::do_write()
|
}
|
|
if (!m_latch_ex)
|
- log_sys.latch.rd_lock(SRW_LOCK_CALL);
|
+ log_sys.latch.rd_spin_lock();
|
|
if (UNIV_UNLIKELY(m_user_space && !m_user_space->max_lsn &&
|
!is_predefined_tablespace(m_user_space->id))) |
The to-be-written member function rd_lock_spin() would avoid invoking futex_wait(), and instead keep invoking MY_RELAX_CPU() in the spin loop.
An exclusive log_sys.latch will be acquired rarely and held for rather short time, during DDL operations, undo tablespace truncation, as well as around log checkpoints.
Some experimentation will be needed to find something that scales well across the board (from embedded systems to high-end servers).
Attachments
{kind=link}
{kind=link}
{kind=link}
Issue Links
- causes
-
-
- Closed
-
- relates to
-
-

- Closed
-
-
-
- Closed
-
-
-
- In Progress
-
- blocks
-
 PERF-407 Failed to load
PERF-407 Failed to load
Activity
| Field | Original Value | New Value |
|---|---|---|
| Status | Open [ 1 ] | In Progress [ 3 ] |
We used to have a spinlock for this log_lsn_lock. The performance was truly horrible, as tested on our normal, non-NUMA machines.
One feasible solution would be to have multiple implementations and choose the preferred one by assigning a function pointer on startup. First we need to find a minimal tweak that improves things for NUMA.
| Link |
This issue relates to |
| Link |
This issue relates to |
| Remote Link | This issue links to "PERF-407 (Jira)" [ 36639 ] |
steve.shaw@intel.com has experimented with the addition of a redundant pure spin lock, first around mtr_t::do_write() and on my suggestion, around mtr_t::finish_write(). The redundant spin lock would prevent conflicts on log_sys.lsn_lock and therefore the costly context switches between user and kernel space. This will improve performance also on a single-socket setup (no NUMA).
Based on this, I will try to replace log_sys.lsn_lock with a pure spin lock. That is something that we never tried so far. The srw_spin_lock would still fall back to something like futex_wait() after an initial spin loop.
| Summary | log_sys.latch causes excessive context switching on NUMA systems | log_sys.lsn_lock causes excessive context switching |
We had tried lsn_lock as pure spin lock, but this gets consistently forgotten
MDEV-27866 has this comment, on Feb 20 2022
-----------------------------------------------
The critical section of lsn_lock is tiny, yet when pure spinlock was used, it slowed thing down on everything. NUMA, non-NUMA, single socket, Windows. I do not have NUMA, but on 16CPU Windows, the 256 users update_index went down from 220-230ktps to 160ktps, while IIRC on Marko Mäkelä's dual socket, it went down from 200 ktps to 30ktps in the same test.
It is not entirely obvious why this happened, I'd check memory access pattern
------------------------------------------------
wlad, thank you for reminding me. In MDEV-27866 I found a pointer to the mcspin_lock patch that I had tested back then (over 2 years ago). It is based on https://gitlab.com/numa-spinlock/numa-spinlock and includes some queue component. The spin lock that steve.shaw@intel.com tested is much simpler, just one lock word. The results with that could be quite different. There has been at least one memory layout improvements since that previous experiment: MDEV-32374.
I created two patches. On my Haswell microarchitecture dual Intel Xeon E5-2630 v4, both result in significantly worse throughput with 256-thread Sysbench oltp_update_index (actually I intended to test oltp_update_non_index) than the 10.11 baseline. With the baseline, the Linux kernel function native_queued_spin_lock_slowpath is the busiest one; with either fix, it would end up in the second place, behind the new function lsn_delay().
The first variant more closely resembles what steve.shaw@intel.com did. It uses std::atomic<bool> for the lock word; the lock acquisition would be xchg.
The second variant merges log_sys.lsn_lock to the most significant bit of log_sys.buf_free. Lock acquisition will be a loop around lock cmpxchg. It yields better throughput on my system than the first variant. One further thing that could be tried would be a combination of lock bts and a separate mov to load the log_sys.buf_free value. On ARMv8, POWER, RISC-V or other modern ISA, we could probably use simple std::atomic::fetch_or().
I think that some further testing on newer Intel microarchitectures is needed to determine whether I am on the right track with these.
| Attachment | update_index_256threads_x_10tables_x_1mio_rows.svg [ 73295 ] |
I tried the patch on AlderLake (server running on P-cores, sysbench on E-cores)
update_index_256threads_x_10tables_x_1mio_rows.svg![]()
In short, spinlocks do make performance worse, e.g TPS for 1 minute update_index x256 threads x10 tables x 1mio rows (in memory) looks like this
| baseline | spinlock | spinflag |
|---|---|---|
| 235146.7 | 151019.13 | 147738.52 |
I also added spinflag.svg![]() and baseline.svg
and baseline.svg![]() flamegraphs, so one can see what's going on.
flamegraphs, so one can see what's going on.
Apparently, the append_prepare/lsn_delay takes half of the time 48%, in "spin" variation, on Alder Lake, while in baseline, append_prepare is barely noticable, with 0.5%
It is not just Haswell, that performs badly, and this sorta matches what we had seen 2 years ago.
| Attachment | baseline.svg [ 73296 ] | |
| Attachment | spinflag.svg [ 73297 ] |
| Assignee | Marko Mäkelä [ marko ] | Vladislav Vaintroub [ wlad ] |
| Status | In Progress [ 3 ] | In Review [ 10002 ] |
https://github.com/MariaDB/server/pull/3148 introduces SET GLOBAL innodb_log_spin_wait_delay, which can be used to enable or disable the spin lock while the server is running. The value 50 should roughly correspond to what the previous spinflag patch did. The default value innodb_log_spin_wait_delay=0 means that the log_sys.lsn_lock will be used. I think that we must rely on steve.shaw@intel.com to test this on Emerald Rapids.
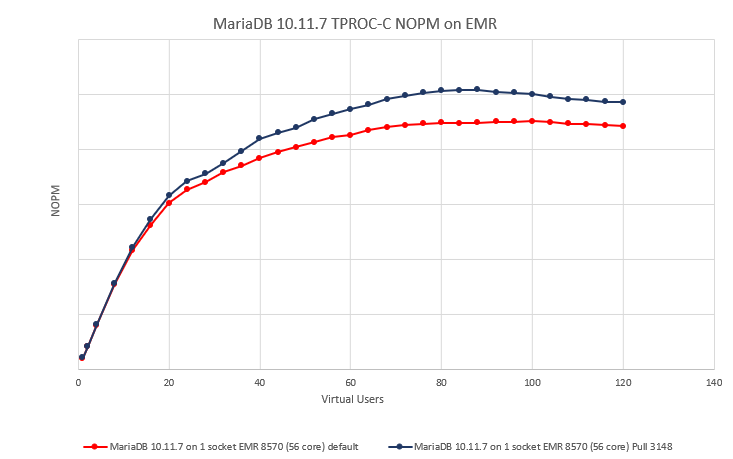
| Attachment | 1socket.png [ 73312 ] | |
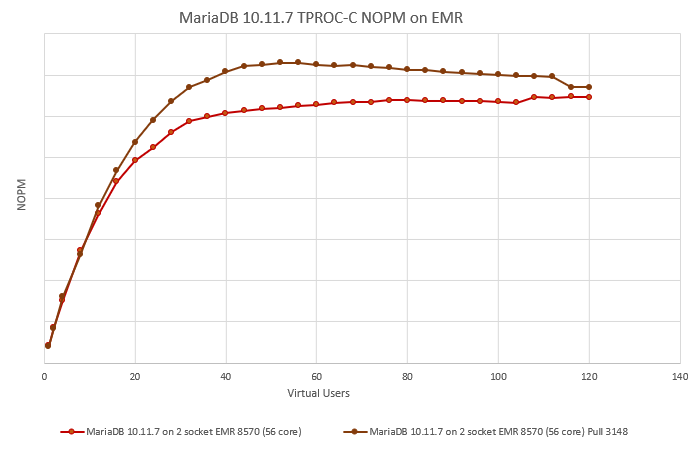
| Attachment | 2socket.png [ 73313 ] |
| Attachment | 1socket-1.png [ 73314 ] |
| Attachment | 1socket-1.png [ 73314 ] |
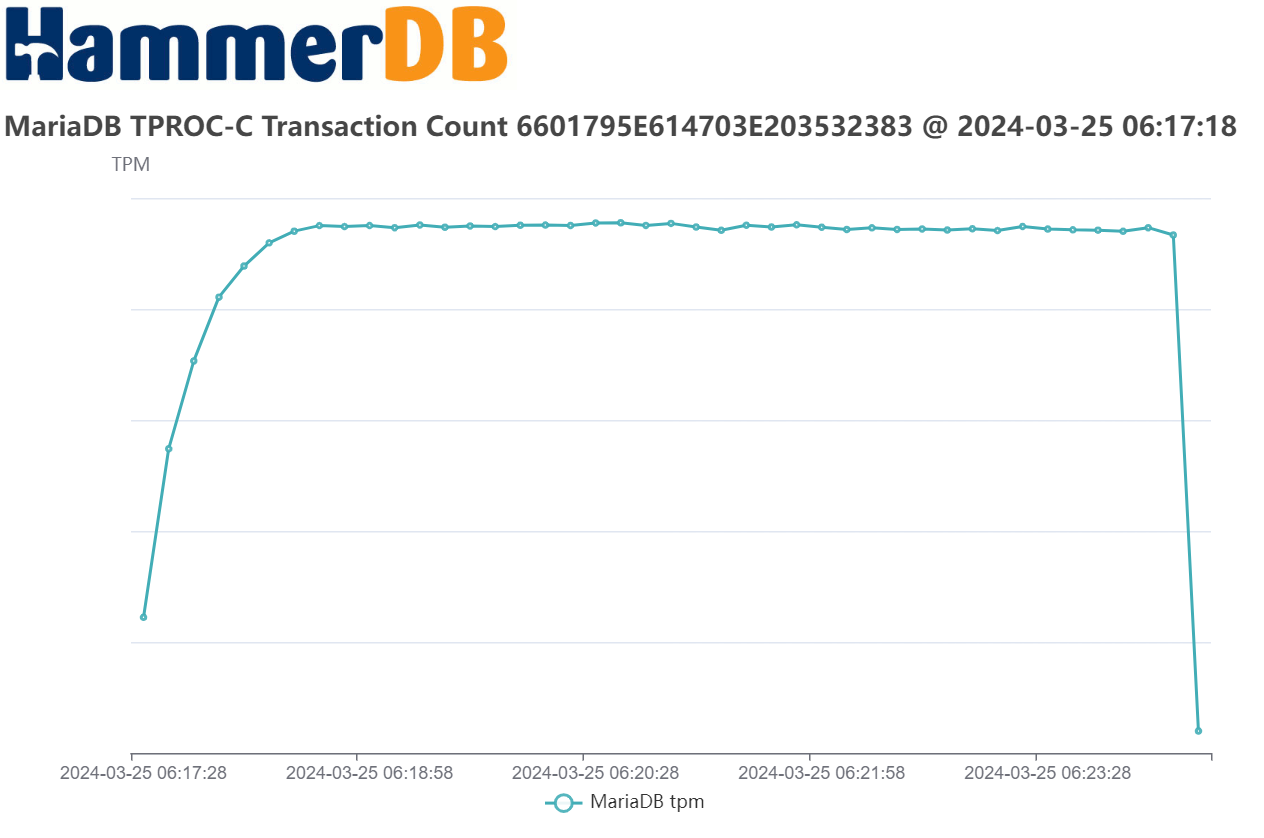
| Attachment | mariadbtpm.png [ 73315 ] |
I have attached on a test Emerald Rapids system with 56 core CPUs with both 1 and 2 socket tests, this improves performance by 9% (1 socket) and 12% (2 socket) respectively and the highest MariaDB throughput we have measured from any release so far with very stable performance measured throughout each of this tests.
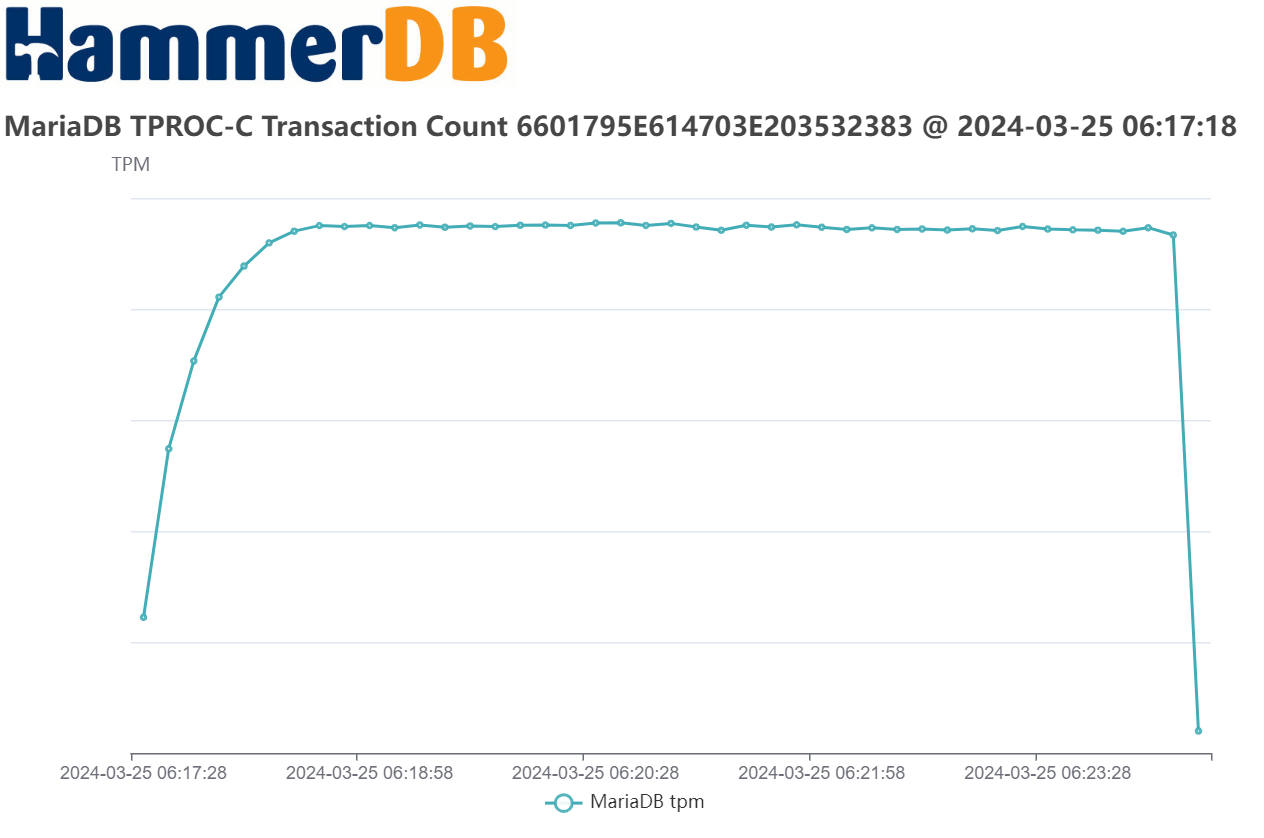
| Assignee | Vladislav Vaintroub [ wlad ] | Marko Mäkelä [ marko ] |
| Status | In Review [ 10002 ] | Stalled [ 10000 ] |
| issue.field.resolutiondate | 2024-03-26 16:06:52.0 | 2024-03-26 16:06:52.18 |
| Fix Version/s | 10.11.8 [ 29630 ] | |
| Fix Version/s | 11.0.6 [ 29628 ] | |
| Fix Version/s | 11.1.5 [ 29629 ] | |
| Fix Version/s | 11.2.4 [ 29631 ] | |
| Fix Version/s | 11.4.2 [ 29633 ] | |
| Fix Version/s | 10.11 [ 27614 ] | |
| Fix Version/s | 11.0 [ 28320 ] | |
| Fix Version/s | 11.2 [ 28603 ] | |
| Fix Version/s | 11.4 [ 29301 ] | |
| Resolution | Fixed [ 1 ] | |
| Status | Stalled [ 10000 ] | Closed [ 6 ] |
I think that it would be interesting to know the limits on the number of concurrent threads on more recent microarchitectures. Common sense would suggest that spinning would work better when the number of concurrent threads is limited to a fraction of the number of hardware threads. I did not test such low concurrency on my Haswell microarchitecture system.
In any case, it is easy to tune this if it does not work, simply by SET GLOBAL innodb_log_spin_wait_delay.
| Link | This issue relates to MDEV-21923 [ MDEV-21923 ] |
| Link |
This issue causes |
Come to think of it, the actual issue could be the lock_lsn() call in log_t::append_prepare(). Maybe we simply need a spin loop around that. Perhaps the existing implementation would work?
diff --git a/storage/innobase/include/log0log.h b/storage/innobase/include/log0log.hindex 54851ca0a65..1a6bde20cad 100644--- a/storage/innobase/include/log0log.h+++ b/storage/innobase/include/log0log.h@@ -182,7 +182,7 @@ struct log_ttypedef pthread_mutex_wrapper<true> log_lsn_lock;#elsetypedef srw_lock log_rwlock;- typedef srw_mutex log_lsn_lock;+ typedef srw_spin_mutex log_lsn_lock;#endifAnother alternative would be the pthread_mutex_wrapper<true>, which we are using on ARM. That template parameter spinloop=true refers to MY_MUTEX_INIT_FAST a.k.a. PTHREAD_MUTEX_ADAPTIVE_NP, which enables a spin loop pthread_mutex_lock() in the GNU libc.