Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
10.8(EOL), 10.9(EOL), 10.10(EOL), 10.11, 11.0(EOL), 11.1(EOL), 11.2(EOL), 11.3(EOL)
Description
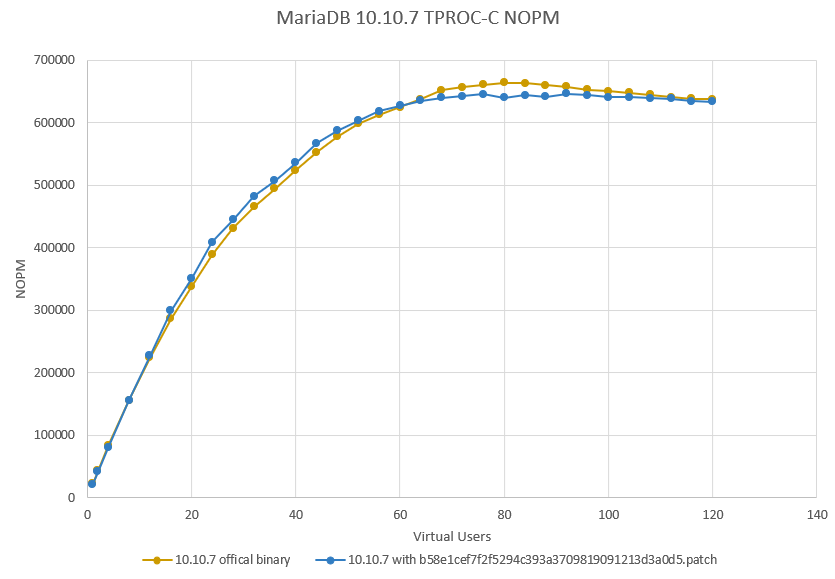
MDEV-27774 made it possible to for multiple mtr_t::commit() to write to log_sys.buf concurrently, by replacing the InnoDB log_sys.mutex with log_sys.latch and log_sys.lsn_lock. The latter appears to be a performance bottleneck.
Because we need to keep multiple log_sys data members consistent with each other, we cannot simply invoke std::atomic::fetch_add and std::atomic::compare_exchange_weak on log_sys.buf_free to achieve a similar result. But, we could try to fit more data members in the same single cache line with log_sys.latch.
Attachments
Issue Links
- is caused by
-
-
- Closed
-
- relates to
-
-
- Closed
-
-
-

- Closed
-
