Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
10.8(EOL)
Description
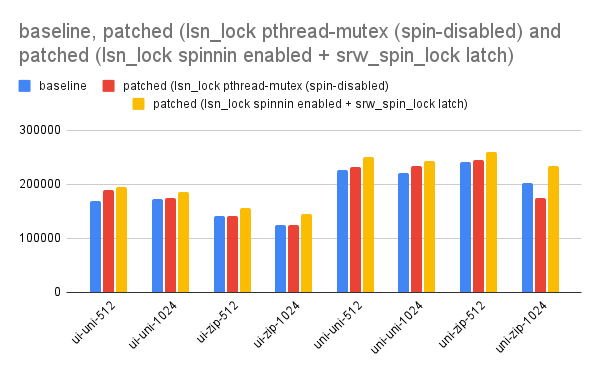
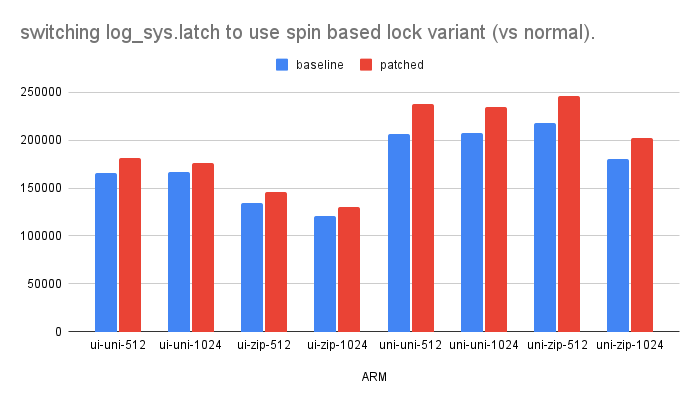
- log_sys.mutex was replaced with log_sys.latch as part of redo log revamp efforts.
- during the experiment it was observed that log_sys.latch spin-based variant
continue to perform better on ARM in the range of 8-15%.
(x86 didn't show any major performance difference).
Attachments
Issue Links
- relates to
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
