Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Fixed
-
10.8(EOL), 10.9(EOL), 10.10(EOL), 10.11, 11.0(EOL), 11.1(EOL), 11.2(EOL), 11.3(EOL), 11.4
-
GNU/Linux, NUMA on Intel Xeon
Description
steve.shaw@intel.com is reporting that write intensive workloads on a NUMA system end up spending a lot of time in native_queued_spin_lock_slowpath.part.0 in the Linux kernel. He has provided a patch that adds a user-space spinlock around the calls to mtr_t::do_write() and is significantly improving throughput at larger numbers of concurrent connections in his test environment.
As far as I can tell, that patch would only allow one mtr_t::do_write() call to proceed at a time, and thus make waits on log_sys.latch extremely unlikely. But that would also seem to ruin part of what MDEV-27774 achieved.
If I understood it correctly, the idea would be better implemented at a slightly lower level, to allow maximum concurrency:
diff --git a/storage/innobase/mtr/mtr0mtr.cc b/storage/innobase/mtr/mtr0mtr.cc
|
index b819022fec6..884bb5af5c1 100644
|
--- a/storage/innobase/mtr/mtr0mtr.cc
|
+++ b/storage/innobase/mtr/mtr0mtr.cc
|
@@ -1052,7 +1052,7 @@ std::pair<lsn_t,mtr_t::page_flush_ahead> mtr_t::do_write()
|
}
|
|
if (!m_latch_ex)
|
- log_sys.latch.rd_lock(SRW_LOCK_CALL);
|
+ log_sys.latch.rd_spin_lock();
|
|
if (UNIV_UNLIKELY(m_user_space && !m_user_space->max_lsn &&
|
!is_predefined_tablespace(m_user_space->id))) |
The to-be-written member function rd_lock_spin() would avoid invoking futex_wait(), and instead keep invoking MY_RELAX_CPU() in the spin loop.
An exclusive log_sys.latch will be acquired rarely and held for rather short time, during DDL operations, undo tablespace truncation, as well as around log checkpoints.
Some experimentation will be needed to find something that scales well across the board (from embedded systems to high-end servers).
Attachments
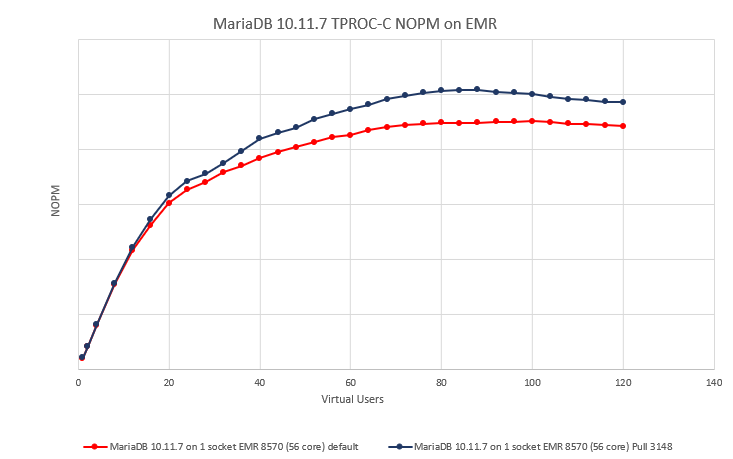
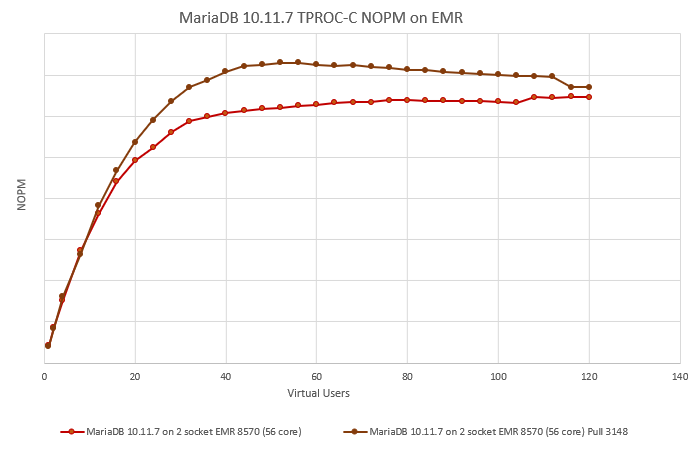
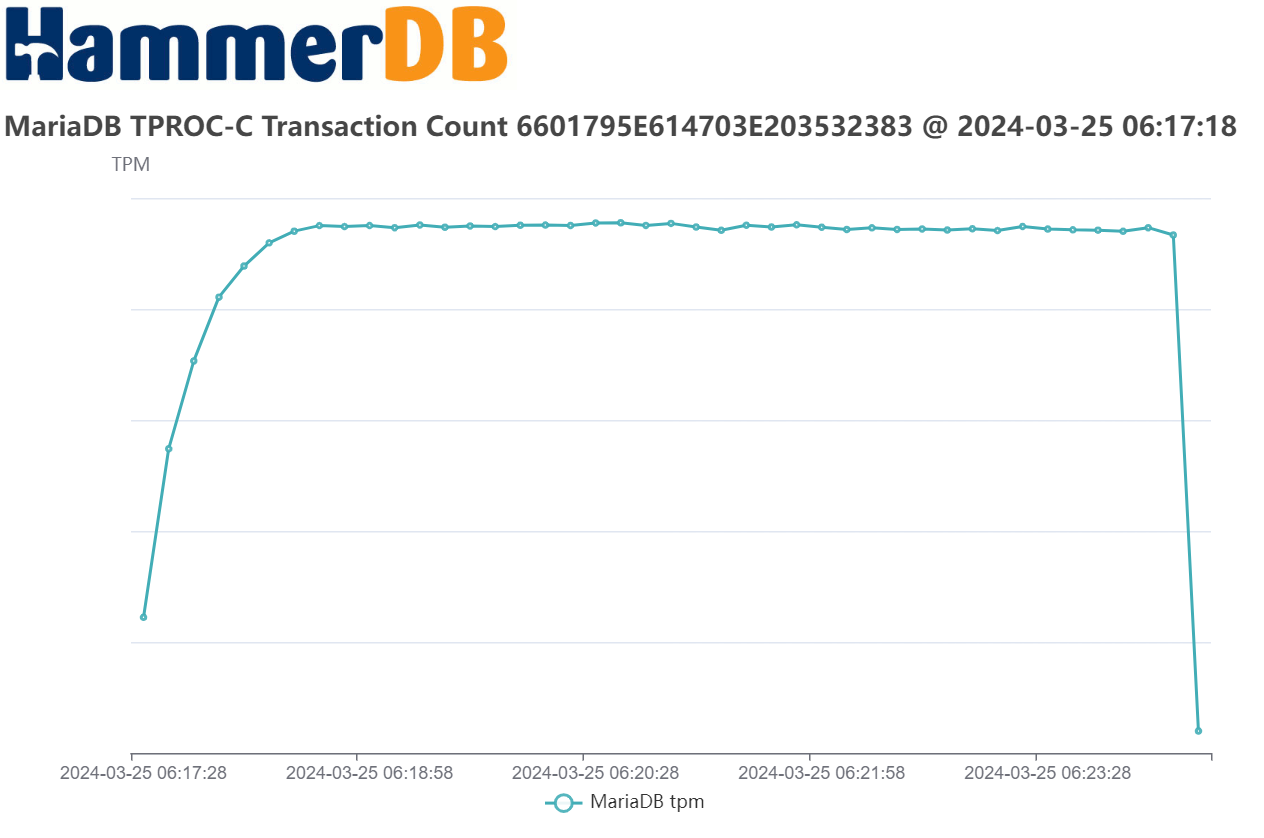
Issue Links
- causes
-
-
- Closed
-
- relates to
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
- blocks
-
PERF-407 Loading...

{kind=link}
{kind=link}
{kind=link}