Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Fixed
-
10.11, 11.4, 11.8
Description
MySQL #WL10310 optimizes the redo log(unlock and write concurrently). Does MariaDB plan to optimize redo log?
Reference material - https://dev.mysql.com/blog-archive/mysql-8-0-new-lock-free-scalable-wal-design/
Attachments
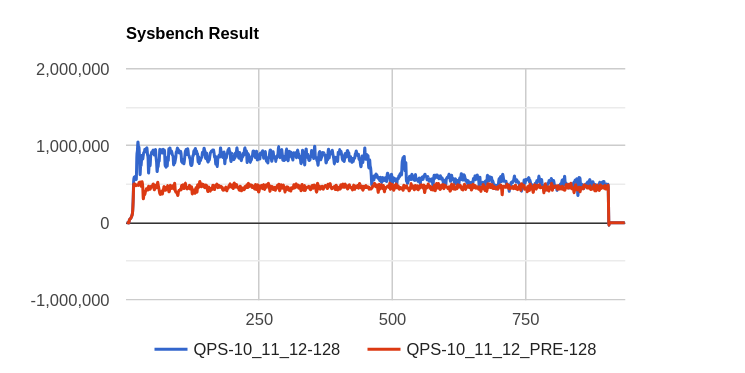
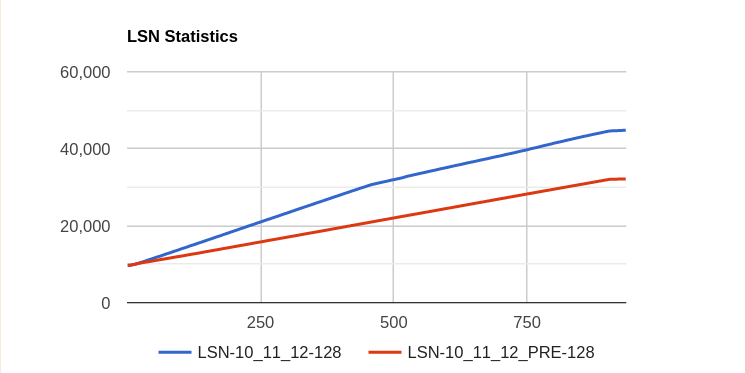
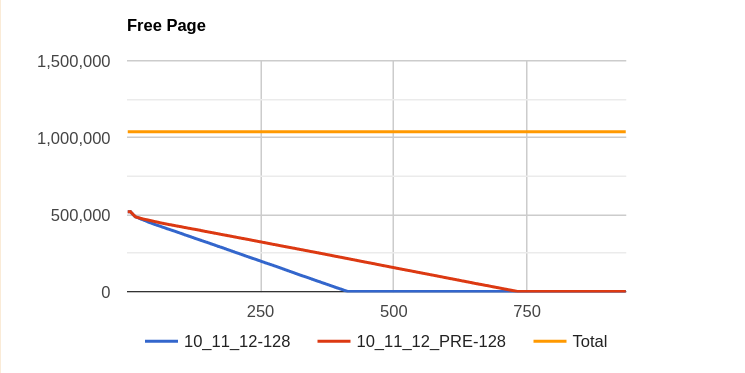
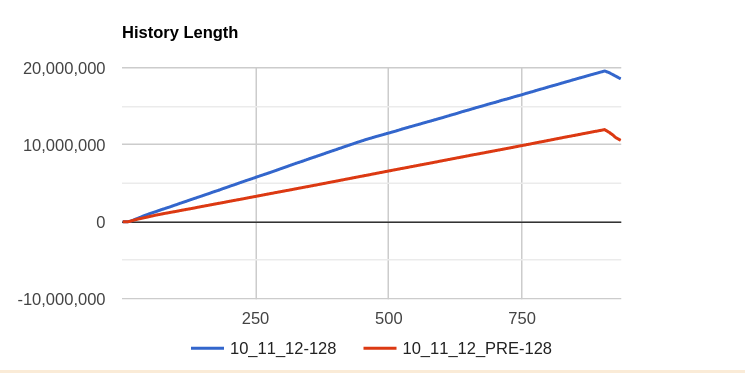
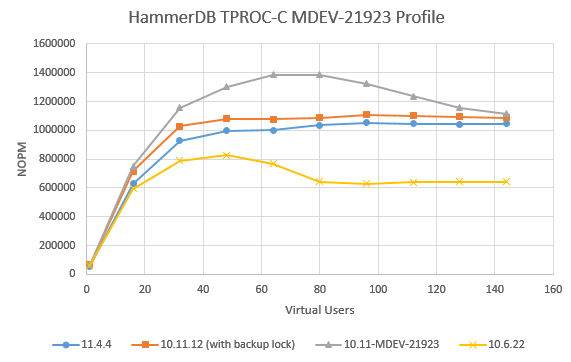
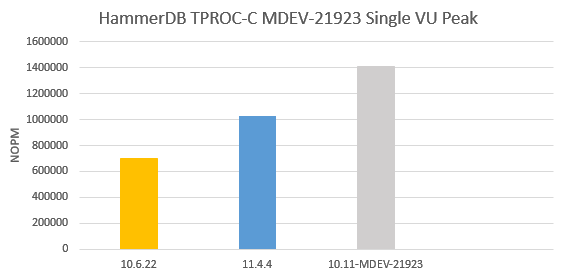
Issue Links
- causes
-
-

- Closed
-
-
-
- Closed
-
- relates to
-
MDEV-14425 Change the InnoDB redo log format to reduce write amplification
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Open
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
- links to
