Details
-
Bug
-
Status: Closed (View Workflow)
-
 Blocker
Blocker
-
Resolution: Fixed
-
11.0.3
-
OpenSUSE 15.4
Description
After hitting this issue https://jira.mariadb.org/browse/MDEV-31579 and waiting for a fix in 11.0.3, I thought we were in the clear.
However, a couple of minutes into running 11.0.3, the server crashed, and now keeps crashing every few minutes.
2023-08-30 14:09:49 0x7fadf061e700 InnoDB: Assertion failure in file /home/abuild/rpmbuild/BUILD/mariadb-11.0.3/storage/innobase/btr/btr0cur.cc line 6702 |
InnoDB: Failing assertion: local_len >= BTR_EXTERN_FIELD_REF_SIZE
|
InnoDB: We intentionally generate a memory trap.
|
InnoDB: Submit a detailed bug report to https://jira.mariadb.org/ |
InnoDB: If you get repeated assertion failures or crashes, even
|
InnoDB: immediately after the mariadbd startup, there may be
|
InnoDB: corruption in the InnoDB tablespace. Please refer to
|
InnoDB: https://mariadb.com/kb/en/library/innodb-recovery-modes/ |
InnoDB: about forcing recovery.
|
230830 14:09:49 [ERROR] mysqld got signal 6 ; |
This could be because you hit a bug. It is also possible that this binary |
or one of the libraries it was linked against is corrupt, improperly built,
|
or misconfigured. This error can also be caused by malfunctioning hardware.
|
|
|
To report this bug, see https://mariadb.com/kb/en/reporting-bugs |
|
|
We will try our best to scrape up some info that will hopefully help |
diagnose the problem, but since we have already crashed,
|
something is definitely wrong and this may fail. |
|
|
Server version: 11.0.3-MariaDB-log source revision: 70905bcb9059dcc40db3b73bc46a36c7d40f1e10 |
key_buffer_size=536870912 |
read_buffer_size=262144 |
max_used_connections=24 |
max_threads=2050 |
thread_count=22 |
It is possible that mysqld could use up to
|
key_buffer_size + (read_buffer_size + sort_buffer_size)*max_threads = 5301930 K bytes of memory |
Hope that's ok; if not, decrease some variables in the equation. |
|
|
Thread pointer: 0x7fad3c000c58 |
Attempting backtrace. You can use the following information to find out
|
where mysqld died. If you see no messages after this, something went |
terribly wrong...
|
stack_bottom = 0x7fadf061dd08 thread_stack 0x49000 |
/usr/sbin/mysqld(my_print_stacktrace+0x3d)[0x55ea4835712d] |
/usr/sbin/mysqld(handle_fatal_signal+0x575)[0x55ea47e60215] |
corrupted size vs. prev_size
|
Any idea what this crash is about?
Attachments

Issue Links
- blocks
-
-

- Closed
-
-
-
- Closed
-
- relates to
-
-
- Closed
-
-
-
- Closed
-
-
MDEV-29694 Remove the InnoDB change buffer
-
- Closed
-
Activity
I downgraded back down to 10.11.3, which worked in the past, but this time the error keeps coming back. It looks to be in table wp_posts, just running
CHECK TABLE `wp_posts`
|
makes the server crash.
|
|
230830 17:08:10 [ERROR] mysqld got signal 11 ; |
This could be because you hit a bug. It is also possible that this binary |
or one of the libraries it was linked against is corrupt, improperly built,
|
or misconfigured. This error can also be caused by malfunctioning hardware.
|
|
|
To report this bug, see https://mariadb.com/kb/en/reporting-bugs |
|
|
We will try our best to scrape up some info that will hopefully help |
diagnose the problem, but since we have already crashed,
|
something is definitely wrong and this may fail. |
|
|
Server version: 10.11.3-MariaDB-log source revision: 0bb31039f54bd6a0dc8f0fc7d40e6b58a51998b0 |
key_buffer_size=536870912 |
read_buffer_size=262144 |
max_used_connections=5 |
max_threads=2050 |
thread_count=7 |
It is possible that mysqld could use up to
|
key_buffer_size + (read_buffer_size + sort_buffer_size)*max_threads = 5301706 K bytes of memory |
Hope that's ok; if not, decrease some variables in the equation. |
|
|
Thread pointer: 0x7f4be8000c58 |
Attempting backtrace. You can use the following information to find out
|
where mysqld died. If you see no messages after this, something went |
terribly wrong...
|
stack_bottom = 0x7f52aca87d48 thread_stack 0x49000 |
/usr/sbin/mysqld(my_print_stacktrace+0x3d)[0x56258173ca5d] |
/usr/sbin/mysqld(handle_fatal_signal+0x575)[0x5625812328f5] |
/lib64/libpthread.so.0(+0x16910)[0x7f52ae24e910] |
/usr/sbin/mysqld(+0xdcf264)[0x562581604264] |
/usr/sbin/mysqld(+0xe17b41)[0x56258164cb41] |
/usr/sbin/mysqld(+0xe17ca8)[0x56258164cca8] |
/usr/sbin/mysqld(+0x69483f)[0x562580ec983f] |
/usr/sbin/mysqld(+0xd86bb8)[0x5625815bbbb8] |
/usr/sbin/mysqld(+0xcb9f60)[0x5625814eef60] |
/usr/sbin/mysqld(_ZN7handler8ha_checkEP3THDP15st_ha_check_opt+0x61)[0x56258123cad1] |
/usr/sbin/mysqld(+0x8dbc50)[0x562581110c50] |
/usr/sbin/mysqld(_ZN19Sql_cmd_check_table7executeEP3THD+0x88)[0x562581111a88] |
/usr/sbin/mysqld(_Z21mysql_execute_commandP3THDb+0x1151)[0x562580ff5191] |
/usr/sbin/mysqld(_Z11mysql_parseP3THDPcjP12Parser_state+0x1fe)[0x562580ffc4be] |
/usr/sbin/mysqld(_Z16dispatch_command19enum_server_commandP3THDPcjb+0x1635)[0x562580ff1bc5] |
/usr/sbin/mysqld(_Z10do_commandP3THDb+0x127)[0x562580feffd7] |
/usr/sbin/mysqld(_Z24do_handle_one_connectionP7CONNECTb+0x3ff)[0x562581102bdf] |
/usr/sbin/mysqld(handle_one_connection+0x34)[0x562581102f74] |
/usr/sbin/mysqld(+0xc0912d)[0x56258143e12d] |
/lib64/libpthread.so.0(+0xa6ea)[0x7f52ae2426ea] |
/lib64/libc.so.6(clone+0x41)[0x7f52ad12149f] |
|
|
Trying to get some variables.
|
Some pointers may be invalid and cause the dump to abort.
|
Query (0x7f4be800c970): CHECK TABLE `wp_posts` |
|
|
Connection ID (thread ID): 2901 |
Status: NOT_KILLED
|
|
|
Optimizer switch: index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,index_merge_sort_intersection=off,engine_condition_pushdown=off,index_condition_pushdown=on,derived_merge=on,derived_with_keys=on,firstmatch=on,loosescan=on,materialization=on,in_to_exists=on,semijoin=on,partial_match_rowid_merge=on,partial_match_table_scan=on,subquery_cache=on,mrr=off,mrr_cost_based=off,mrr_sort_keys=off,outer_join_with_cache=on,semijoin_with_cache=on,join_cache_incremental=on,join_cache_hashed=on,join_cache_bka=on,optimize_join_buffer_size=on,table_elimination=on,extended_keys=on,exists_to_in=on,orderby_uses_equalities=on,condition_pushdown_for_derived=on,split_materialized=on,condition_pushdown_for_subquery=on,rowid_filter=on,condition_pushdown_from_having=on,not_null_range_scan=off,hash_join_cardinality=off |
|
|
The manual page at https://mariadb.com/kb/en/how-to-produce-a-full-stack-trace-for-mysqld/ contains |
information that should help you find out what is causing the crash.
|
Writing a core file...
|
Working directory at /var/lib/mysql
|
Resource Limits:
|
Limit Soft Limit Hard Limit Units
|
Max cpu time unlimited unlimited seconds
|
Max file size unlimited unlimited bytes
|
Max data size unlimited unlimited bytes
|
Max stack size 8388608 unlimited bytes |
Max core file size unlimited unlimited bytes
|
Max resident set unlimited unlimited bytes
|
Max processes 128319 128319 processes |
Max open files 1048576 1048576 files |
Max locked memory 8388608 8388608 bytes |
Max address space unlimited unlimited bytes
|
Max file locks unlimited unlimited locks
|
Max pending signals 128319 128319 signals |
Max msgqueue size 819200 819200 bytes |
Max nice priority 0 0 |
Max realtime priority 0 0 |
Max realtime timeout unlimited unlimited us
|
Core pattern: /tmp/cores/core.%e.%p.%h.%t
|
Also, when the server starts, I'm seeing this message:
2023-08-30 16:04:29 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=25033372266327 |
2023-08-30 16:04:29 0 [ERROR] InnoDB: The change buffer is corrupted or has been removed on upgrade to MariaDB 11.0 or later |
Thank you for the report. InnoDB traditionally handled corruption in a crude fashion: by killing itself. In MDEV-13542 this was corrected in many code paths, but not for this particular case.
Here, InnoDB crashes because BLOB access is being attempted even though the field in the clustered index is shorter than 20 bytes, which is the length of the BLOB pointer. The length should be exactly 20 or 788 bytes, depending on the ROW_FORMAT.
I think that in order to diagnose this, I would have to know the complete SQL statement as well the SHOW CREATE TABLE for the problematic table. Furthermore, I would like to see some things in the stack frame of row_sel_store_mysql_field():
print *index.fields@index.n_fields
|
print/x offsets[1]@offsets[1]+16
|
info locals
|
dump binary memory /tmp/page.bin rec-0x232 rec-0x232+srv_page_size
|
Please provide the contents of the file /tmp/page.bin. I need to understand in which way this record is corrupted, or what leads the code to interpret it incorrectly.
This crash should have nothing to do with the removal of the InnoDB change buffer (MDEV-29694), because only columns of the clustered index (primary key) can be stored externally, and the change buffer was applicable to secondary index pages.
Two InnoDB file format changes were made in MariaDB Server 11.0 that make downgrades problematic: MDEV-29694 and MDEV-19506.
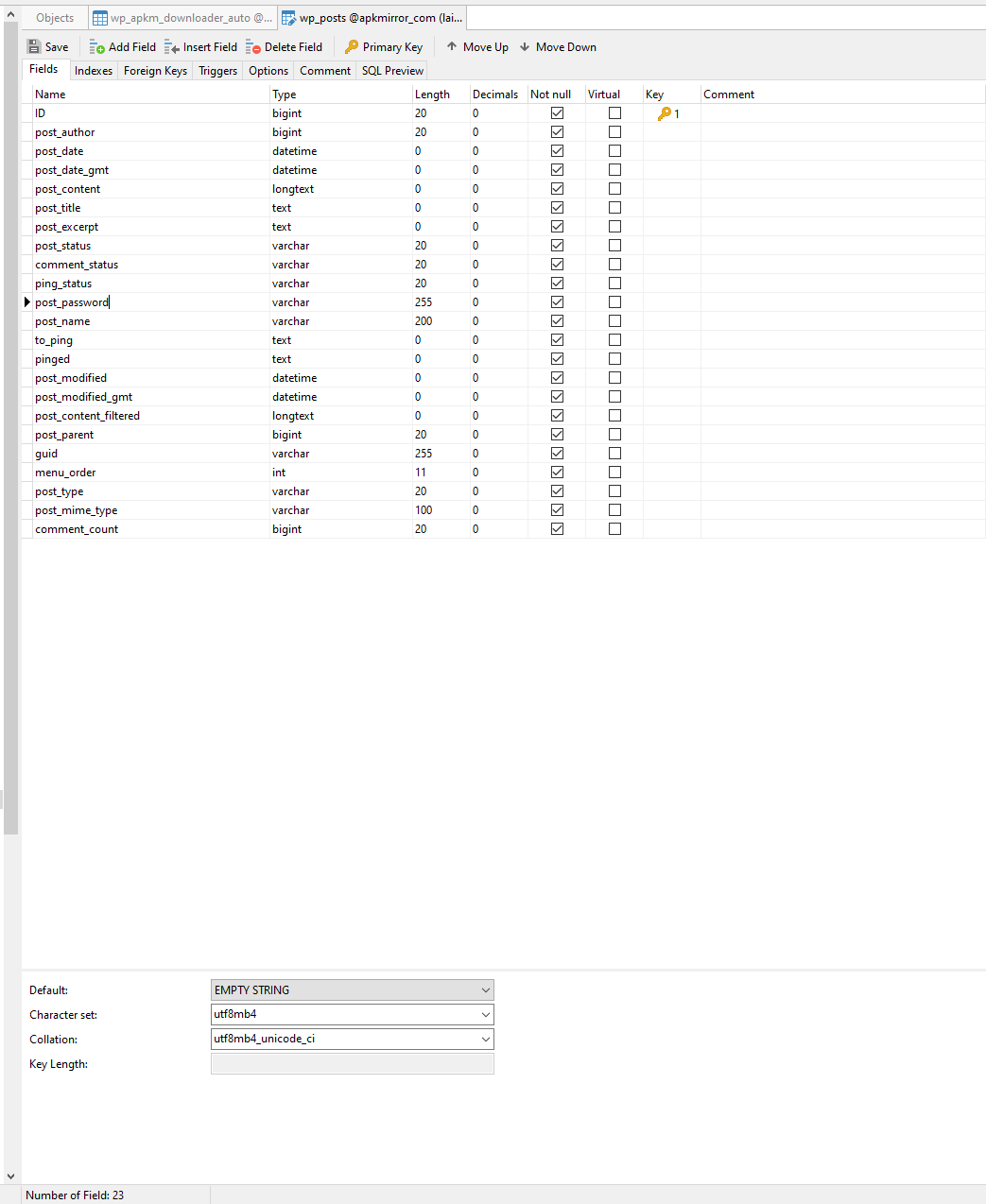
SHOW CREATE TABLE wp_posts:
CREATE TABLE `wp_posts` (
|
`ID` bigint(20) unsigned NOT NULL AUTO_INCREMENT, |
`post_author` bigint(20) unsigned NOT NULL DEFAULT 0, |
`post_date` datetime NOT NULL DEFAULT '0000-00-00 00:00:00', |
`post_date_gmt` datetime NOT NULL DEFAULT '0000-00-00 00:00:00', |
`post_content` longtext NOT NULL,
|
`post_title` text NOT NULL,
|
`post_excerpt` text NOT NULL,
|
`post_status` varchar(20) NOT NULL DEFAULT 'publish', |
`comment_status` varchar(20) NOT NULL DEFAULT 'open', |
`ping_status` varchar(20) NOT NULL DEFAULT 'open', |
`post_password` varchar(255) NOT NULL DEFAULT '', |
`post_name` varchar(200) NOT NULL DEFAULT '', |
`to_ping` text NOT NULL,
|
`pinged` text NOT NULL,
|
`post_modified` datetime NOT NULL DEFAULT '0000-00-00 00:00:00', |
`post_modified_gmt` datetime NOT NULL DEFAULT '0000-00-00 00:00:00', |
`post_content_filtered` longtext NOT NULL,
|
`post_parent` bigint(20) unsigned NOT NULL DEFAULT 0, |
`guid` varchar(255) NOT NULL DEFAULT '', |
`menu_order` int(11) NOT NULL DEFAULT 0, |
`post_type` varchar(20) NOT NULL DEFAULT 'post', |
`post_mime_type` varchar(100) NOT NULL DEFAULT '', |
`comment_count` bigint(20) NOT NULL DEFAULT 0, |
PRIMARY KEY (`ID`),
|
KEY `post_parent` (`post_parent`),
|
KEY `post_author` (`post_author`) USING BTREE,
|
KEY `post_name` (`post_name`) USING BTREE,
|
KEY `type_status_date` (`post_type`,`post_status`,`post_date`,`ID`),
|
KEY `post_modified_gmt_type_status` (`post_modified_gmt`,`post_type`,`post_status`) USING BTREE COMMENT 'Added by Illogical Robot LLC', |
KEY `post_status_type_password_date_modified` (`post_status`,`post_type`,`post_password`,`post_date`,`post_modified`) USING BTREE COMMENT 'Added by Illogical Robot LLC', |
KEY `date_gmt_status_type` (`post_date_gmt`,`post_status`,`post_type`) USING BTREE COMMENT 'Added by Illogical Robot LLC', |
KEY `author_status_type` (`post_author`,`post_status`,`post_type`) USING BTREE COMMENT 'Added by Illogical Robot LLC', |
KEY `type_status_author` (`post_type`,`post_status`,`post_author`) USING BTREE COMMENT 'Added by Illogical Robot LLC' |
) ENGINE=InnoDB AUTO_INCREMENT=5211808 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci ROW_FORMAT=DYNAMIC |
As for the rest, I'm debugging cores, and I'm getting the following for the commands you listed:
(gdb) print *index.fields@index.n_fields |
You can't do that without a process to debug. |
(gdb) print/x offsets[1]@offsets[1]+16 |
No symbol "offsets" in current context. |
(gdb) info locals
|
No symbol table info available.
|
I think it needs to be a live process for this to work, but have a core dump (and instructions from https://mariadb.com/kb/en/how-to-produce-a-full-stack-trace-for-mysqld/#analyzing-a-core-file-with-gdb-on-linux). Do you have further instructions to do it on a live process if it's not possible from a core? Will page.bin contain potentially sensitive data? If so, should it be shared privately?
Also, now that I updated back again to 11.0.3 so that gdb runs properly, I'm seeing a warning in the logs that only showed up with v11
2023-08-30 22:43:07 0 [Warning] InnoDB: Cannot change innodb_undo_tablespaces=3 because previous shutdown was not with innodb_fast_shutdown=0 |
Is this a concern? What is the recommended course of action here?
The warning message regarding innodb_undo_tablespaces is related to MDEV-19229 and MDEV-29986. It should be nothing to worry about, and it should be unrelated to this crash.
The GDB commands whose output I need in order to debug this further should work when invoked on the correct stack frame when debugging a core dump and a matching executable. Did you use the commands frame or up or down to switch to the stack frame of row_sel_store_mysql_field()? When executed in a stack frame where no local variable index is available, the first command might complain about needing a live process because it is interpreting index as a reference to a library function.
Ah, thanks for those hints.
Does this help?
(gdb) frame
|
#0 0x00007f08a7e53d2b in raise () from /lib64/libc.so.6 |
(gdb) up
|
#1 0x00007f08a7e553e5 in abort () from /lib64/libc.so.6 |
(gdb) up
|
#2 0x000055e23530480a in ut_dbg_assertion_failed (expr=expr@entry=0x55e235e2f0c0 "local_len >= BTR_EXTERN_FIELD_REF_SIZE", file=file@entry=0x55e235e2f050 "/home/abuild/rpmbuild/BUILD/mariadb-11.0.3/storage/innobase/btr/btr0cur.cc", line=line@entry=6702) |
at /usr/src/debug/mariadb-11.0.3-lp154.1.1.x86_64/storage/innobase/ut/ut0dbg.cc:60 |
60 abort(); |
(gdb) up
|
#3 0x000055e235a49898 in btr_rec_copy_externally_stored_field (rec=rec@entry=0x7f065ea84232 "", offsets=offsets@entry=0x7f024ece44e0, zip_size=<optimized out>, no=no@entry=16, len=len@entry=0x7f024ece4150, heap=heap@entry=0x7f022c0b52b8) |
at /usr/src/debug/mariadb-11.0.3-lp154.1.1.x86_64/storage/innobase/btr/btr0cur.cc:6702 |
6702 ut_a(local_len >= BTR_EXTERN_FIELD_REF_SIZE); |
(gdb) up
|
#4 0x000055e235303111 in row_sel_store_mysql_field (mysql_rec=mysql_rec@entry=0x7f01d8042920 "\037&@", prebuilt=prebuilt@entry=0x7f01d8047030, rec=rec@entry=0x7f065ea84232 "", index=index@entry=0x7f02440068f0, offsets=offsets@entry=0x7f024ece44e0, field_no=16, templ=0x7f01d80684f8) |
at /usr/src/debug/mariadb-11.0.3-lp154.1.1.x86_64/storage/innobase/row/row0sel.cc:3018 |
3018 data = btr_rec_copy_externally_stored_field( |
(gdb) print *index.fields@index.n_fields |
$1 = {{col = 0x7f0244005c40, name = {m_name = 0x7f0244005fd8 "ID"}, prefix_len = 0, fixed_len = 8, descending = 0}, {col = 0x7f0244005f40, name = {m_name = 0x7f02440060f5 "DB_TRX_ID"}, prefix_len = 0, fixed_len = 6, descending = 0}, {col = 0x7f0244005f60, name = {m_name = 0x7f02440060ff "DB_ROLL_PTR"}, |
prefix_len = 0, fixed_len = 7, descending = 0}, {col = 0x7f0244005c60, name = {m_name = 0x7f0244005fdb "post_author"}, prefix_len = 0, fixed_len = 8, descending = 0}, {col = 0x7f0244005c80, name = {m_name = 0x7f0244005fe7 "post_date"}, prefix_len = 0, fixed_len = 5, descending = 0}, {col = 0x7f0244005ca0, |
name = {m_name = 0x7f0244005ff1 "post_date_gmt"}, prefix_len = 0, fixed_len = 5, descending = 0}, {col = 0x7f0244005cc0, name = {m_name = 0x7f0244005fff "post_content"}, prefix_len = 0, fixed_len = 0, descending = 0}, {col = 0x7f0244005ce0, name = {m_name = 0x7f024400600c "post_title"}, prefix_len = 0, |
fixed_len = 0, descending = 0}, {col = 0x7f0244005d00, name = {m_name = 0x7f0244006017 "post_excerpt"}, prefix_len = 0, fixed_len = 0, descending = 0}, {col = 0x7f0244005d20, name = {m_name = 0x7f0244006024 "post_status"}, prefix_len = 0, fixed_len = 0, descending = 0}, {col = 0x7f0244005d40, name = { |
m_name = 0x7f0244006030 "comment_status"}, prefix_len = 0, fixed_len = 0, descending = 0}, {col = 0x7f0244005d60, name = {m_name = 0x7f024400603f "ping_status"}, prefix_len = 0, fixed_len = 0, descending = 0}, {col = 0x7f0244005d80, name = {m_name = 0x7f024400604b "post_password"}, prefix_len = 0, |
fixed_len = 0, descending = 0}, {col = 0x7f0244005da0, name = {m_name = 0x7f0244006059 "post_name"}, prefix_len = 0, fixed_len = 0, descending = 0}, {col = 0x7f0244005dc0, name = {m_name = 0x7f0244006063 "to_ping"}, prefix_len = 0, fixed_len = 0, descending = 0}, {col = 0x7f0244005de0, name = { |
m_name = 0x7f024400606b "pinged"}, prefix_len = 0, fixed_len = 0, descending = 0}, {col = 0x7f0244005e00, name = {m_name = 0x7f0244006072 "post_modified"}, prefix_len = 0, fixed_len = 5, descending = 0}, {col = 0x7f0244005e20, name = {m_name = 0x7f0244006080 "post_modified_gmt"}, prefix_len = 0, |
fixed_len = 5, descending = 0}, {col = 0x7f0244005e40, name = {m_name = 0x7f0244006092 "post_content_filtered"}, prefix_len = 0, fixed_len = 0, descending = 0}, {col = 0x7f0244005e60, name = {m_name = 0x7f02440060a8 "post_parent"}, prefix_len = 0, fixed_len = 8, descending = 0}, {col = 0x7f0244005e80, |
name = {m_name = 0x7f02440060b4 "guid"}, prefix_len = 0, fixed_len = 0, descending = 0}, {col = 0x7f0244005ea0, name = {m_name = 0x7f02440060b9 "menu_order"}, prefix_len = 0, fixed_len = 4, descending = 0}, {col = 0x7f0244005ec0, name = {m_name = 0x7f02440060c4 "post_type"}, prefix_len = 0, fixed_len = 0, |
descending = 0}, {col = 0x7f0244005ee0, name = {m_name = 0x7f02440060ce "post_mime_type"}, prefix_len = 0, fixed_len = 0, descending = 0}, {col = 0x7f0244005f00, name = {m_name = 0x7f02440060dd "comment_count"}, prefix_len = 0, fixed_len = 8, descending = 0}} |
(gdb) print/x offsets[1]@offsets[1]+16 |
$2 = {0x19, 0x8017, 0x8, 0xe, 0x15, 0x1d, 0x22, 0x27, 0x27, 0x42, 0x89, 0x11f, 0x194, 0x21d, 0x30b6, 0x472b, 0x50d9, 0x69d9, 0x69de, 0x69e3, 0x69e3, 0x69eb, 0x69eb, 0x69ef, 0x69ef, 0x69ef, 0x69f7, 0x0 <repeats 14 times>} |
(gdb) info locals
|
heap = 0x7f022c0b52b8 |
data = <optimized out>
|
len = 11929 |
(gdb) dump binary memory /tmp/page.bin rec-0x232 rec-0x232+srv_page_size |
Thank you, this is a step forward. But I had forgotten about MDEV-10814. The page.bin contains 16384 NUL bytes, because by default, the buffer pool page descriptors or frames are not included in core dumps of non-debug builds.
I decode the offsets as follows:
- offsets to 25=0x19 fields (all index.n_fields) computed
- the record header length is 0x17 bytes, and the record is not in ROW_FORMAT=REDUNDANT format
- the first field (ID) ends at byte 8
- the second field (DB_TRX_ID) ends at byte 14=8+6
- the 12th field (ping_status) ends at byte 0x21d
- the 13th field (post_password) belongs to the first instantly added column (
MDEV-11369), and it ends at 0x10b6. Can that field really be so long, or did I miscount something? - and so on, until the last field (0x69f7) referring to the 8-byte field post_mime_type
The 3 most significant bits in the elements are flags. Actually, the 0x69f7 is REC_OFFS_EXTERNAL|REC_OFFS_DEFAULT|0x19f7. This looks really suspicious to me. Any field where the REC_OFFS_EXTERNAL flag is set should end exactly 20 (0x14) bytes after the previous field. We can see that several consecutive fields end at the same offset as the previous one (that is, their length is 0).
Using the core dump, can you please also paste the output of print *index in that stack frame?
Could you attach GDB to the running server before invoking the crashing query? In that way, we should get a valid copy of the page. I may need an interactive debugging session in order to fully understand this. Ideally, you would start the server under rr record (https://rr-project.org) and immediately run the crashing query, in order to produce a full execution trace that leads to the crash.
Here you go:
(gdb) print *index
|
$3 = {static MAX_N_FIELDS = 1023, id = 29334, heap = 0x7f0244006798, name = {m_name = 0x7f0244006a88 "PRIMARY"}, table = 0x7f0244005950, page = 3, merge_threshold = 50, type = 3, trx_id_offset = 8, n_user_defined_cols = 1, nulls_equal = 0, n_uniq = 1, n_def = 25, n_fields = 25, n_nullable = 0, |
n_core_fields = 25, n_core_null_bytes = 0, static NO_CORE_NULL_BYTES = 255, static DICT_INDEXES_ID = 3, cached = 1, to_be_dropped = 0, online_status = 0, uncommitted = 0, fields = 0x7f0244006b20, parser = 0x0, new_vcol_info = 0x0, change_col_info = 0x0, indexes = {prev = 0x0, next = 0x7f02440070b0}, |
search_info = 0x7f0244006dc8, online_log = 0x0, stat_n_diff_key_vals = 0x7f0244006db0, stat_n_sample_sizes = 0x7f0244006db8, stat_n_non_null_key_vals = 0x7f0244006dc0, stat_index_size = 85182, stat_n_leaf_pages = 74390, stats_error_printed = false, stat_defrag_modified_counter = 0, |
stat_defrag_n_pages_freed = 0, stat_defrag_n_page_split = 0, stat_defrag_data_size_sample = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0}, stat_defrag_sample_next_slot = 0, rtr_ssn = {m = std::atomic<unsigned int> = { 0 }}, rtr_track = 0x0, trx_id = 0, zip_pad = {mutex = {<std::__mutex_base> = {_M_mutex = {__data = { |
__lock = 0, __count = 0, __owner = 0, __nusers = 0, __kind = 0, __spins = 0, __elision = 0, __list = {__prev = 0x0, __next = 0x0}}, __size = '\000' <repeats 39 times>, __align = 0}}, <No data fields>}, pad = {m = std::atomic<unsigned long> = { 0 }}, success = 0, failure = 0, n_rounds = 0}, lock = { |
lock = {pfs_psi = 0x0, lock = {writer = {lock = std::atomic<unsigned int> = { 0 }, static HOLDER = 2147483648}, readers = std::atomic<unsigned int> = { 0 }, static WRITER = 2147483648}}, recursive = 0, writer = std::atomic<unsigned long> = { 0 }, static FOR_IO = <optimized out>, static RECURSIVE_X = 1, |
static RECURSIVE_U = 65536, static RECURSIVE_MAX = 65535}} |
Regarding post_password, if you're talking about its declared size, it's in the CREATE TABLE paste above and is varchar(255). Here's the output from Navicat for this table:
Are you available on Telegram? We could do a live debug and screen share, things could go much faster this way. I'm archon810 there.
archon810, sorry, I had missed your update. Recently, I used https://mariadb.zulipchat.com/ and a SSH connection to a community user’s system to debug MDEV-31443. That would be the most convenient way.
The main takeaway from the output is that both n_fields and n_core_fields are 25, that is, no instant ADD COLUMN has been executed on this table. Like I replied to your comment in MDEV-31443, if there is a connection to that bug, it could be that the change buffer contained stale entries that on upgrade were applied to pages that had since then been reused for something else. We had reproduced and fixed one case of that kind of corruption while testing MDEV-30009.
If I got a copy of the corrupted page, I should easily be able to see if the MDEV-30009 explanation might be valid. I have encountered that type of corruption in one to three support customer cases this year.
While I'd like to fix this condition in core properly, can you think of a way to fix it in the current system? This crashing server is one of the slaves, I had to take it offline as it was crashing on queries every few minutes, and this way at least replication continues and doesn't fall behind. If I perform some sort of update to the table structure on the master, do you think it could propagate to this slave and "fix" it (as opposed to either not changing the situation or worse - breaking replication and fully crashing)?
I just messaged on you on Zulip.
We debugged a live process, observed the crash, and I was able to share the memory dump with Marko, who's now looking into it further.
Here is some analysis of the page dump that I got from the interactive session. We got CHECK TABLE crashing when row_check_index was trying to report index records in a wrong order, invoking ut_print_buf() on what looked like a negative length (wrapping around to a large 64-bit unsigned integer). We didn’t save the stack trace, but I have the info locals from the row_check_index. I think that the crash was around here:
int cmp= cmp_dtuple_rec_with_match(prev_entry, rec, index, offsets, |
&matched_fields);
|
const char* msg; |
|
|
if (UNIV_LIKELY(cmp < 0)); |
else if (cmp > 0) |
{
|
prebuilt->autoinc_error= DB_INDEX_CORRUPT;
|
msg= "index records in a wrong order in "; |
not_ok:
|
ib::error() << msg << index->name << " of table " << index->table->name |
<< ": " << *prev_entry << ", " |
<< rec_offsets_print(rec, offsets);
|
}
|
We had rec right after the page infimum record, at byte offset 0x8b from the start of the page frame.
I traversed the next-record list from the page infimum to the last record (at 0x3e04, with PRIMARY KEY(id)=0x3bc992). All records have been inserted in ascending order of the PRIMARY KEY(id). There are 699 bytes of PAGE_GARBAGE, in 3 deleted records.
The first two records have id=0x3bc950 and id=0x3bc951. I do not see an immediate reason for the crash or the attempt to record corruption yet. I will have to check the records in more detail.
archon810, the previous page would be page number 0x60bb or 24763. Can you send a copy of that?
dd bs=16384 skip=24763 count=1 if=the_corrupted_table.ibd of=prev_page.bin
|
Also, if possible, can you run CHECK TABLE on 10.11 using a copy of the original data before the upgrade to 11.0 was attempted?
Not sure if related to this, but I'm occasionally seeing various TUPLE errors on the slaves (not master).
Slave 1:
2023-09-06 16:32:47 5 [ERROR] InnoDB: Record in index `date_gmt_status_type` of table `XXXXXXXXXXXXXXXX`.`wp_posts` was not found on update: TUPLE (info_bits=0, 4 fields): {[5] (0x8000000000),[5]draft(0x6472616674),[11]app_release(0x6170705F72656C65617365),[8] s(0x000000000009ED73)} at: COMPACT RECORD(info_bits=0, 4 fields): {[5] (0x8000000000),[5]draft(0x6472616674),[11]app_release(0x6170705F72656C65617365),[8] |(0x000000000009CC7C)} |
2023-09-07 11:06:48 5 [ERROR] InnoDB: Record in index `date_gmt_status_type` of table `XXXXXXXXXXXXXXXX`.`wp_posts` was not found on update: TUPLE (info_bits=0, 4 fields): {[5] (0x8000000000),[5]draft(0x6472616674),[11]app_release(0x6170705F72656C65617365),[8] (0x00000000000A0705)} at: COMPACT RECORD(info_bits=0, 4 fields): {[5] (0x8000000000),[5]draft(0x6472616674),[11]app_release(0x6170705F72656C65617365),[8] |(0x000000000009CC7C)} |
Slave 2:
2023-09-02 13:11:02 5 [ERROR] InnoDB: Record in index `post_parent` of table `XXXXXXXXXXXXXXXX`.`wp_posts` was not found on update: TUPLE (info_bits=0, 2 fields): {[8] (0x0000000000000000),[8] B (0x00000000004207C1)} at: COMPACT RECORD(info_bits=0, 2 fields): {[8] (0x0000000000000000),[8] (0x000000000007C104)} |
Thankfully, they don't break replication, but probably result in failed queries.
Edit: On one of the slaves still running MariaDB 10.11, I ran `check table wp_posts`, which marked it as corrupted due to a bad index and started spitting out "[ERROR] Got error 180 when reading table" errors to the log. I then ran `optimize table wp_posts` which fixed the corruption.
archon810, thank you.
The further error messages that you posted are a sign that some secondary indexes are not in sync with the clustered index (primary key index), where InnoDB stores the data. You will find many such reports in MDEV-9663. It seems that we did a good job in MDEV-13542 and related fixes, because InnoDB is no longer crashing in those cases. It is only refusing to execute some DML when it encounters corruption.
For corrupted secondary indexes, the strategy should be to flag the index as corrupted, so that all further operations that would normally have to modify the index will skip the corrupted index. Any reads that would want to use the index should return an error. In include/my_base.h I found the following:
#define HA_ERR_INDEX_CORRUPT 180 /* Index corrupted */ |
The copy of the previous page that you provided proves that this is a scenario like the one that we were able to reproduce in MDEV-30009; see my FOSDEM 2023 talk and slides and a scriptreplay of an rr replay debugging session that shows in more detail what happened.
In both page dumps, the field PAGE_INDEX_ID at 0x42 contains 0x7296, so they belong to the same index, which looks like the clustered index of the corrupted table. The first PRIMARY KEY value on the previous page 0x60bb (at infimum+0x1e6) is 0x3bc912. The last valid-looking PRIMARY KEY value is 0x3bc94f at 0x35b1. The first PRIMARY KEY value on the successor page 0x60bd is 0x3bc950 at 0x8b. As you can see, these key values are adjacent.
However, the next record of 0x35b1 on the page 0x60bb is not the page supremum, but a record that looks like it belongs to a secondary index. That record starts at 0x3666. It starts with an ASCII string apps_postpublish and the entire length of the record is 0x24 (36) bytes, including the record header. It looks like the actual record is ('apps_post','publish',five_bytes,0x272d62). The last index field is a 8-byte PRIMARY KEY value. There are 5 records like this at the end of the page. Maybe you can tell which secondary index these records could have been part of in the history of the .ibd file. I think that the secondary index key must have comprised 3 or 4 columns, and all columns after the first 2 must have been of fixed length. The PRIMARY KEY columns (in this case just one) are automatically appended to each secondary index.
I am sure that the corruptions that you experience is due to the old bug that was fixed in MDEV-30009.
How to remedy this? I would be very eager to know if the table would have been corrupted if you had done a shutdown with innodb_fast_shutdown=0 of the 10.x server. If it would, then I don’t think there is anything that can be improved in the upgrade procedure.
I think that a safe remedy would be to use a debug build option that was added in MDEV-20864, to dump the contents of the change buffer. Then, for every tablespace ID that is present in the change buffer, you would check
SELECT name FROM information_schema.innodb_sys_tables WHERE space IN (…); |
and then run OPTIMIZE TABLE on each table. In that way, neither a shutdown with innodb_fast_shutdown=0 nor an upgrade to 11.0 should be able to propagate the corruption from the change buffer to the tables.
I think that the data corruption scenario is as follows:
- The InnoDB change buffer was enabled, and some INSERT operations for page 0x60bb were buffered in the past. This was the default until the change buffer was disabled by default in
MDEV-27734. - You had executed DROP INDEX on this index while buffered changes existed. The entries in the change buffer became stale at this point. This is how Heikki Tuuri designed it; he was a friend of lazy execution at that time.
- You executed ADD INDEX on another index of the table, using a server version where
MDEV-30009had not been fixed. Page 0x60bb was allocated for this index. Heikki Tuuri’s design was such that any stale change buffer entries would be removed at the time when a page is reallocated for something else. This was missed by those who implemented and reviewed an optimization of InnoDB ALTER TABLE in MySQL 5.7, which was applied to MariaDB 10.2.2 without any review. - Later, page 0x60bb was freed for some reason and finally reused for a PRIMARY KEY.
- On the upgrade to 11.0, the 5 stale change buffer entries were wrongly applied to the page 0x60bb, corrupting the table.
It could be that multiple pages of the table are corrupted. What I would have liked to know is if a 10.x server shutdown with innodb_fast_shutdown=0 would have corrupted the table as well. Because you do not have older physical backups of this database instance, we will not be able to know that.
I don’t think that there is much that we can do at this point. If you could provide a copy of the database (which I do not expect you to do, since it is confidential data), I could try to see how to avoid a crash on this type of data corruption.
archon810, because you are now cloning the data from a healthy 10.11 instance, I don’t think that we will be able to diagnose this any further.
I filed MDEV-32132 for the CREATE INDEX bug that had been fixed as part of MDEV-30009, because that bug needs to be fixed in MariaDB Server 10.4, which still has not reached its end-of-life.
Thank you, Marko, for all your help. As we reached a conclusion that it wasn't possible to repair (or at least easily repair) the table and prevent crashes, I blew up the slave data on the 11.0.3 machine, ran an extended check and then fixed whatever index issues that were found with an optimize command on another slave that was still on 10.11, and then copied that slave's fixed data onto the 11.0.3 machine. This time, the crashes did not occur anymore, and the server has been running smoothly.
I think that we can try to make the upgrade logic similar to how the slow shutdown fix in MDEV-30009 works: disregard any buffered changes for pages for which there are no buffered changes according to the change buffer bitmap.
This should avoid corruption of any actual data (clustered index pages), unless the change buffer bitmaps are really corrupted.
To prove that the current upgrade in 11.0 does not care about the change buffer bitmap bits, I ran the following test modification on an older 10.6 server (right before MDEV-30400) and then started 11.0 on the data directory that was left behind by the failing test:
diff --git a/mysql-test/suite/innodb/t/ibuf_not_empty.test b/mysql-test/suite/innodb/t/ibuf_not_empty.test
|
index 9362f8daffa..a1895f4c49c 100644
|
--- a/mysql-test/suite/innodb/t/ibuf_not_empty.test
|
+++ b/mysql-test/suite/innodb/t/ibuf_not_empty.test
|
@@ -33,6 +33,8 @@ SET GLOBAL innodb_change_buffering=all;
|
# used for modifying the secondary index page. There must be multiple
|
# index pages, because changes to the root page are never buffered.
|
INSERT INTO t1 SELECT 0,'x',1 FROM seq_1_to_1024;
|
+UPDATE t1 SET b='y';
|
+UPDATE t1 SET b='x';
|
let MYSQLD_DATADIR=`select @@datadir`;
|
let PAGE_SIZE=`select @@innodb_page_size`;
|
|
@@ -69,6 +71,7 @@ syswrite(FILE, $page, $ps)==$ps || die "Unable to write $file\n";
|
close(FILE) || die "Unable to close $file";
|
EOF
|
|
+stop_already_here;
|
--let $restart_parameters= --innodb-force-recovery=6 --innodb-change-buffer-dump
|
--source include/start_mysqld.inc
|
|
|
This is similar to the upgrade test MDEV-29694, except that we stop after some Perl code had corrupted the change buffer bitmap in t1.ibd to claim that no buffered changes exist. It is noteworthy that this test fails to actually use the change buffer when the MDEV-30400 fix is present, so I used an older build. Regrettably I did not record the exact revision in MDEV-29694:
|
10.6 e0dbec1ce38688e25cab3720044d6e7e676381f6 |
innodb.ibuf_not_empty 'innodb,strict_crc32' [ fail ]
|
Test ended at 2023-09-19 13:52:09
|
|
|
CURRENT_TEST: innodb.ibuf_not_empty
|
mysqltest: At line 74: query 'stop_already_here' failed: <Unknown> (2006): Server has gone away
|
Unfortunately, no matter what I try (including stopping the test before the Perl code corrupts the .ibd file), I keep getting the following output on the upgrade:
2023-09-19 13:53:11 0 [Note] InnoDB: Upgrading the change buffer
|
2023-09-19 13:53:11 0 [Note] InnoDB: Upgraded the change buffer: 0 tablespaces, 0 pages
|
That is, the change buffer was actually empty to begin with.
I will next attempt creating a modified version of the data.tar.xz that was attached to MDEV-31443, with a modified change buffer bitmap that claims that no changes need to be applied. By using such a modified data directory, I expect to get some corrupted secondary indexes reported when this bug has been fixed. The plain 11.0 without the fix should recover that kind of a corruption fine (apply the possibly stale changes to the index pages).
I created ibuf_page.bin.xz![]() to corrupt the data.tar.xz of
to corrupt the data.tar.xz of MDEV-31443 as follows:
tar xJf data.tar.xz
|
xzcat ibuf_page.bin.xz|
|
dd bs=4096 count=1 seek=1 conv=notrunc of=data/test/table100_innodb_int_autoinc.ibd
|
If I start up the unmodified 11.0 server on this, it will apply changes to one page:
|
11.0 d515fa72a0294d97e3f8d6894714c10331bd771d |
2023-09-19 15:23:49 0 [Note] InnoDB: Upgrading the change buffer
|
2023-09-19 15:23:49 0 [Note] InnoDB: Upgraded the change buffer: 1 tablespaces, 1 pages
|
After this, CHECK TABLE test.table100_innodb_int_autoinc EXTENDED; does not report any error. I hope that after my not-yet-written code fix, it will report some error. (Yes, this is corrupting the file the "wrong way around", opposite of MDEV-32132.)
The above data set contains exactly 2 buffered changes in the change buffer root page (file offset 0x4000 in data/ibdata1), both for the same record in page 5:0x3a: a delete-marking and an insert of the record at file byte offset 0x3adbe (page 0x3a, byte 0xdbe) in file table100_innodb_int_autoinc.ibd. The funny thing is that these two operations will cancel out each other. So, for this particular dataset, there will be no corruption no matter whether the changes to the page are merged or discarded.
I debugged with rr record and rr replay that the revised upgrade logic works as expected: the bitmap bit in the original data.tar.xz is set, and clear when I artificially corrupt the change buffer bitmap page. The changes were applied or discarded accordingly. The message
2023-09-19 18:03:59 0 [Note] InnoDB: Upgraded the change buffer: 1 tablespaces, 1 pages
|
will count all pages for which change buffer records exist, including those for which the changes will be skipped due to the IBUF_BITMAP_BUFFERED bit being clean.
gdb output:
No symbol table info available.No symbol table info available.No locals.local_len = <optimized out>data = <optimized out>data = <optimized out>templ = <optimized out>field_no = <optimized out>set_also_gap_locks = <optimized out>err = DB_SUCCESSuse_covering_index = <optimized out>no_gap_lock = <optimized out>page_corrupted = <optimized out>comp = <optimized out>search_tuple = <optimized out>clust_index = <optimized out>thr = <optimized out>unique_search = <optimized out>moves_up = <optimized out>next_offs = <optimized out>spatial_search = <optimized out>need_vrow = <optimized out>set_stats_temporary = <optimized out>mode = <optimized out>match_mode = <optimized out>ret = <optimized out>error = <optimized out>result = <optimized out>tmp = <optimized out>No locals.error = <optimized out>rc = <optimized out>error = NESTED_LOOP_OKtop_level_tables = <optimized out>rc = <optimized out>error = <optimized out>top_level_tables = <optimized out>res = <optimized out>last_tab = <optimized out>state = <optimized out>end_select = <optimized out>cleared_tables = <optimized out>columns_list = <optimized out>join_tab = <optimized out>sort_tab = <optimized out>join_tab = <optimized out>const_tables = <optimized out>columns_list = <optimized out>res = <optimized out>first_select = <optimized out>derived_is_recursive = <optimized out>res = <optimized out>derived_result = <optimized out>save_current_select = <optimized out>error = <optimized out>rc = NESTED_LOOP_OKskip_over = <optimized out>info = <optimized out>error = NESTED_LOOP_OKtop_level_tables = <optimized out>rc = <optimized out>error = <optimized out>top_level_tables = <optimized out>res = <optimized out>last_tab = <optimized out>state = <optimized out>end_select = <optimized out>cleared_tables = <optimized out>columns_list = <optimized out>join_tab = <optimized out>sort_tab = <optimized out>join_tab = <optimized out>const_tables = <optimized out>columns_list = <optimized out>res = <optimized out>res = <optimized out>select_lex = <optimized out>res = <optimized out>privileges_requested = <optimized out>wsrep_error_label = <optimized out>error = <optimized out>select_lex = <optimized out>rpl_filter = <optimized out>orig_binlog_format = BINLOG_FORMAT_MIXEDorig_current_stmt_binlog_format = BINLOG_FORMAT_STMTfound_semicolon = <optimized out>error = <optimized out>err = <optimized out>res = <optimized out>return_value = <optimized out>packet_length = <optimized out>command = COM_QUERYthr_create_utime = <optimized out>pfs = <optimized out>klass = <optimized out>No symbol table info available.No symbol table info available.