Details
-
Task
-
Status: Stalled (View Workflow)
-
 Critical
Critical
-
Resolution: Unresolved
-
None
-
Q1/2026 Server Development
Description
See also MDEV-22180 and MDEV-30103 (comment).
find_fk_prelocked_table traverses all opened tables in connection, MDL_context::find_ticket traverses all mdl tickets which is also not less amount of steps. Both functions are called for each table, taking O(tables^2) time total, during opening tables.
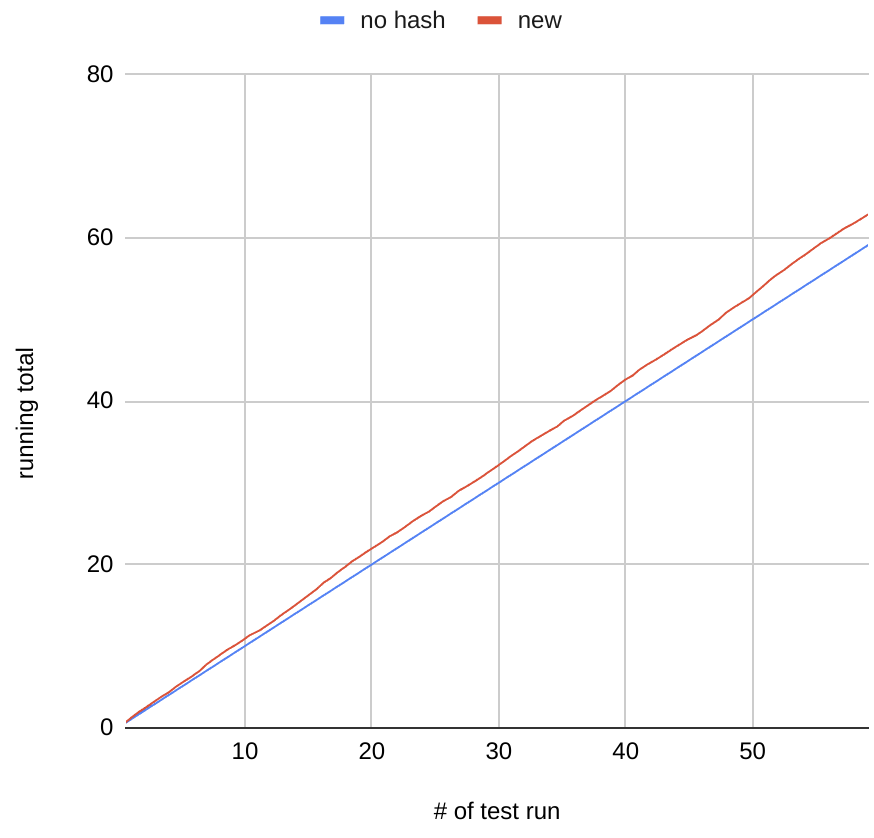
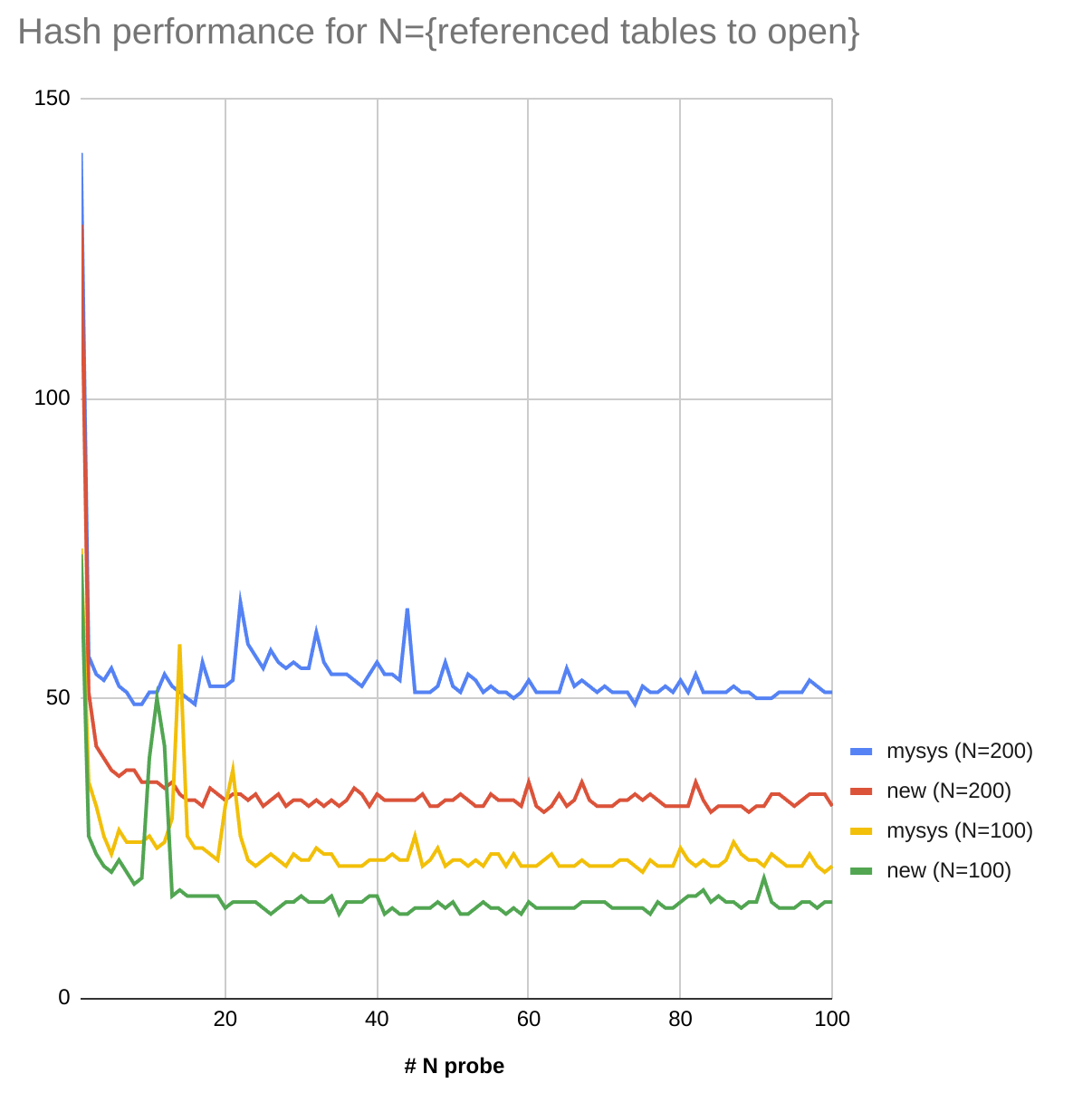
Opening a table for an operation like UPDATE or DELETE for a table with 12k child tables takes about 3.5 seconds on my laptop. Making the two mentioned fuinctions noop takes 0.15 seconds.
What should be done
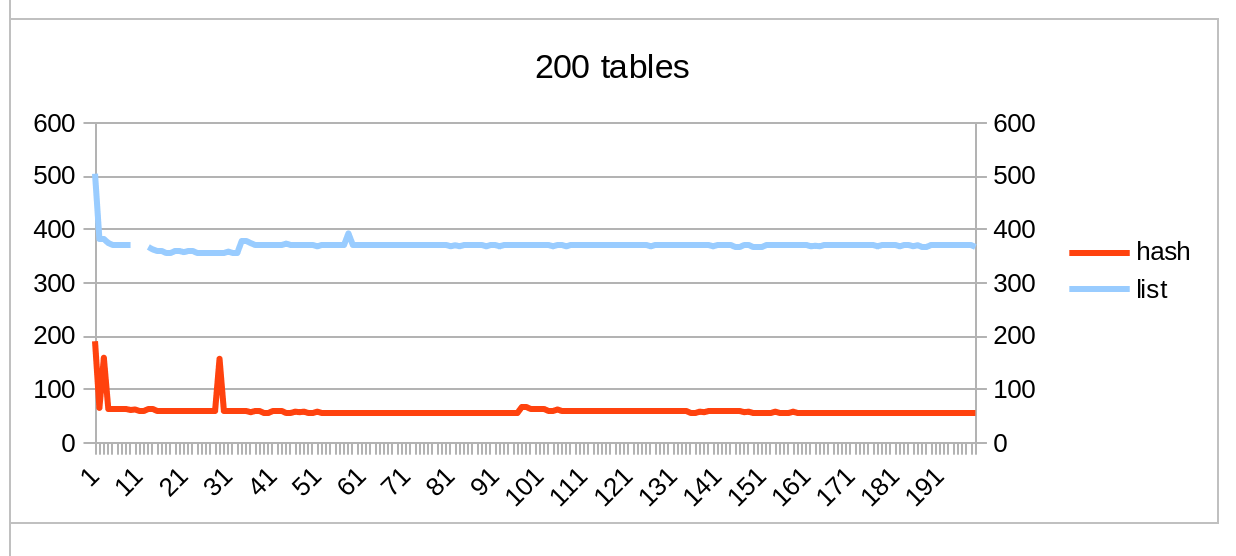
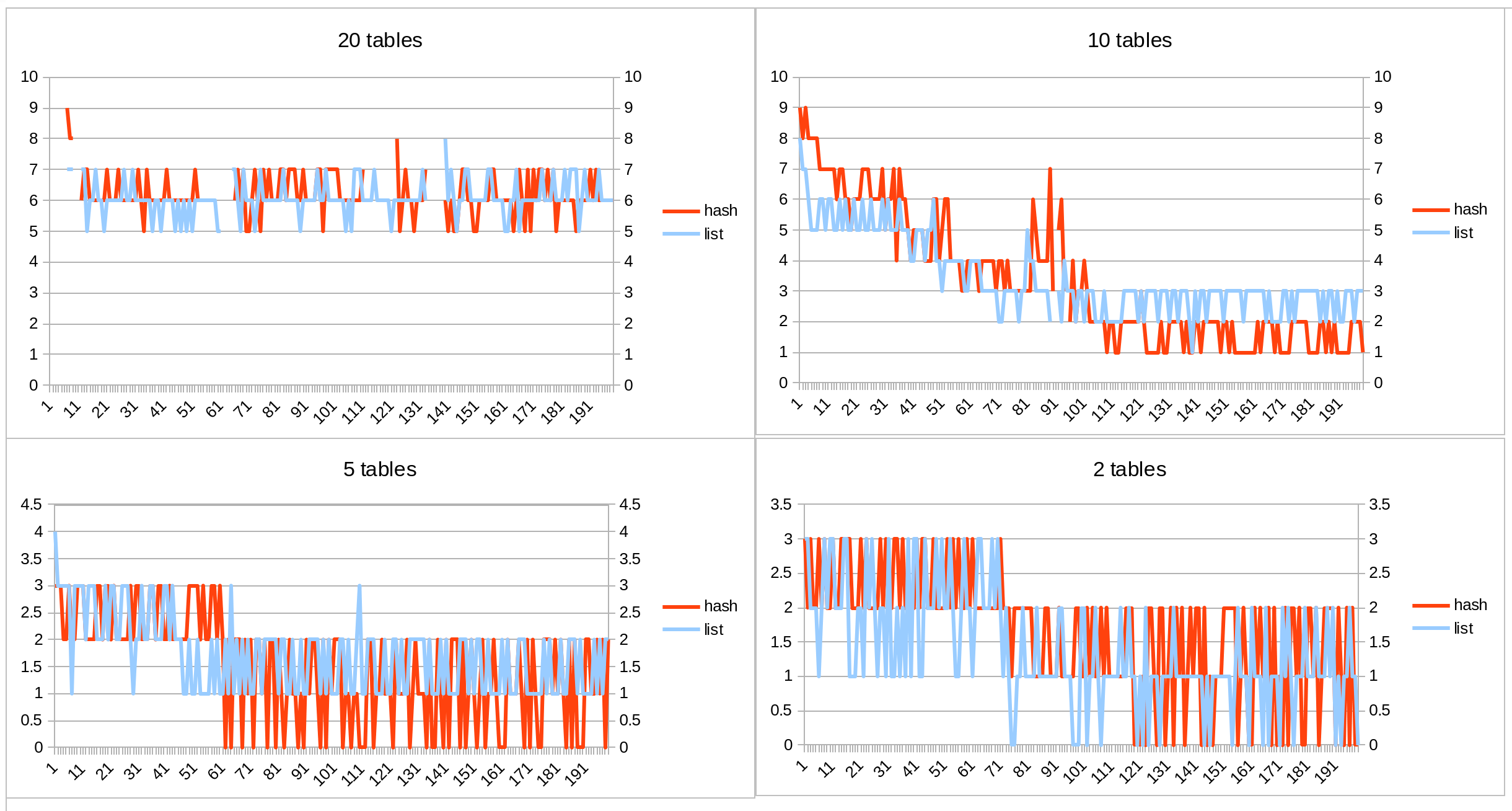
A list traversal should be changed to a hash lookup when a number of tables to open is big.
Hashing is an expensive operation, so for a smaller number of tables (an exact value is to be determined) it should be left as a list traversal.
We can't predict an exact number of tables to open preliminarily: it grows dynamically, once the tables are opened (and triggers/FK relations are checked), so we need a data structure which will also dynamically adapt.
Attachments
Issue Links
- blocks
-
MDEV-12302 Execute triggers for foreign key updates/deletes
-
- Stalled
-
-
-

- Open
-
-
MDEV-31931 FK fields cannot be used anymore in generated columns
-
- Closed
-
-
-
- In Review
-
- relates to
-
-
- Closed
-
-
-
- Stalled
-
-
MDEV-37924 buf_pool.mutex contention under I/O-limited OLTP workload
-
- In Progress
-