Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Incomplete
-
10.3.27
-
CentOS7.9 ,16C32G2000G,
MariaDB10.3.27
Description
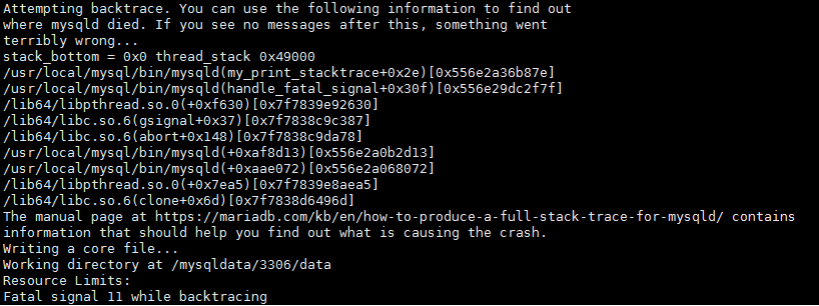
Several days ago,we met a problem a node of MM cluster crashed and then recovery itself.There was a heavy load-in migration task at that time.The related log is in the attachment,11.PNG tells that the server is hanged and crashed raised signal 6. 12.PNG tells the server raised singal 11 and aborting ,that is the reason backtracing file is not generated.13.PNG and 14.PNG tell the informtion when analyzing singal waiting.
If you need any other information to helping solve the problem ,please contact us,thank you!
Attachments



Issue Links
- relates to
-
-
- Closed
-
