Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Fixed
-
10.2.7
-
Ubuntu 16.04 x64
8GB ram
4 CPU
300GB SSD
Mariadb installed only, no other services
Description
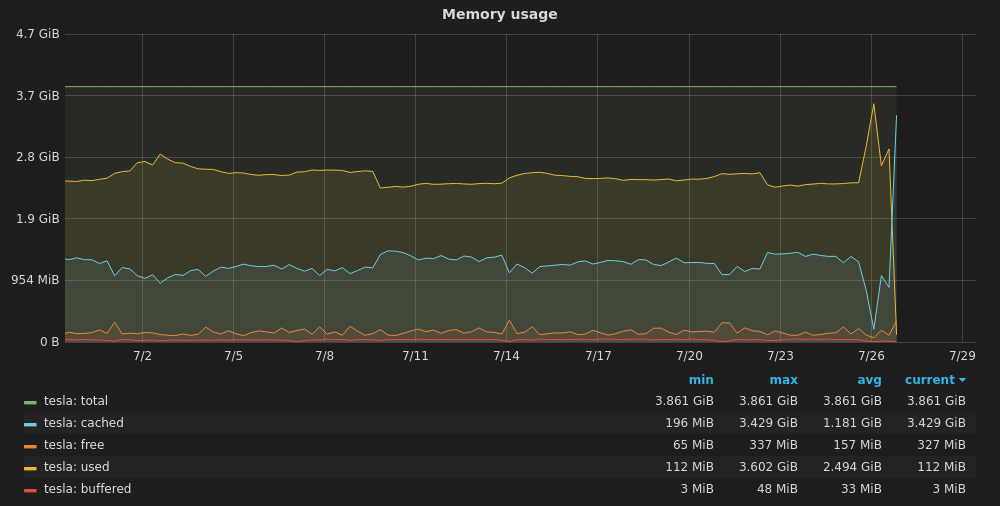
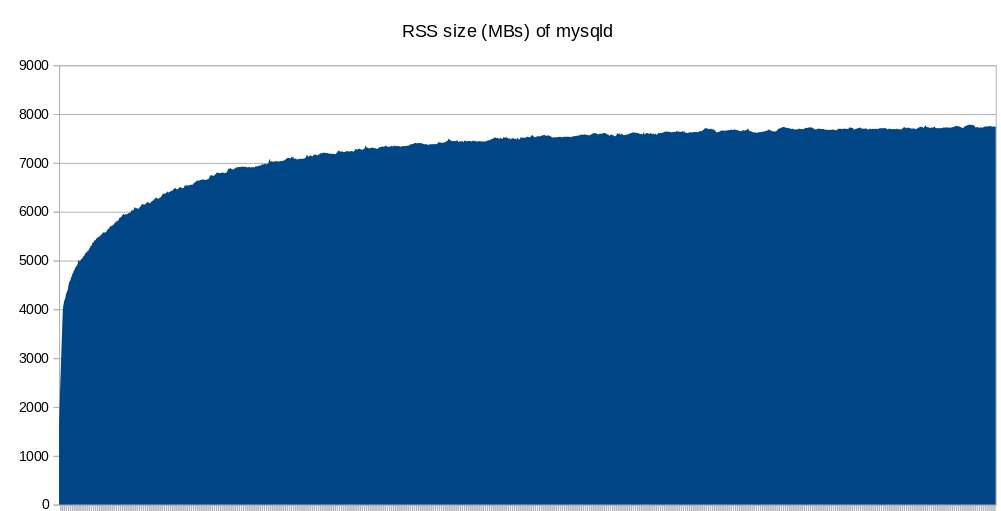
We have been running MariaDB 10.1 with TokuDB on a Ubuntu 14.04 VPS with 4GB ram. This always worked fine. We recently updated to 10.2 and suddenly MariaDB started eating all the memory there is and also uses a lot of swap. We did upgrade our VPS to a Ubuntu 16.04 8 GB instance (not because of the problems, but just because that would improve performance). Here the issues continued.
Settings did not change between te VPS instances, we only allocated 4GB ram to TokuDB instead of 2GB.
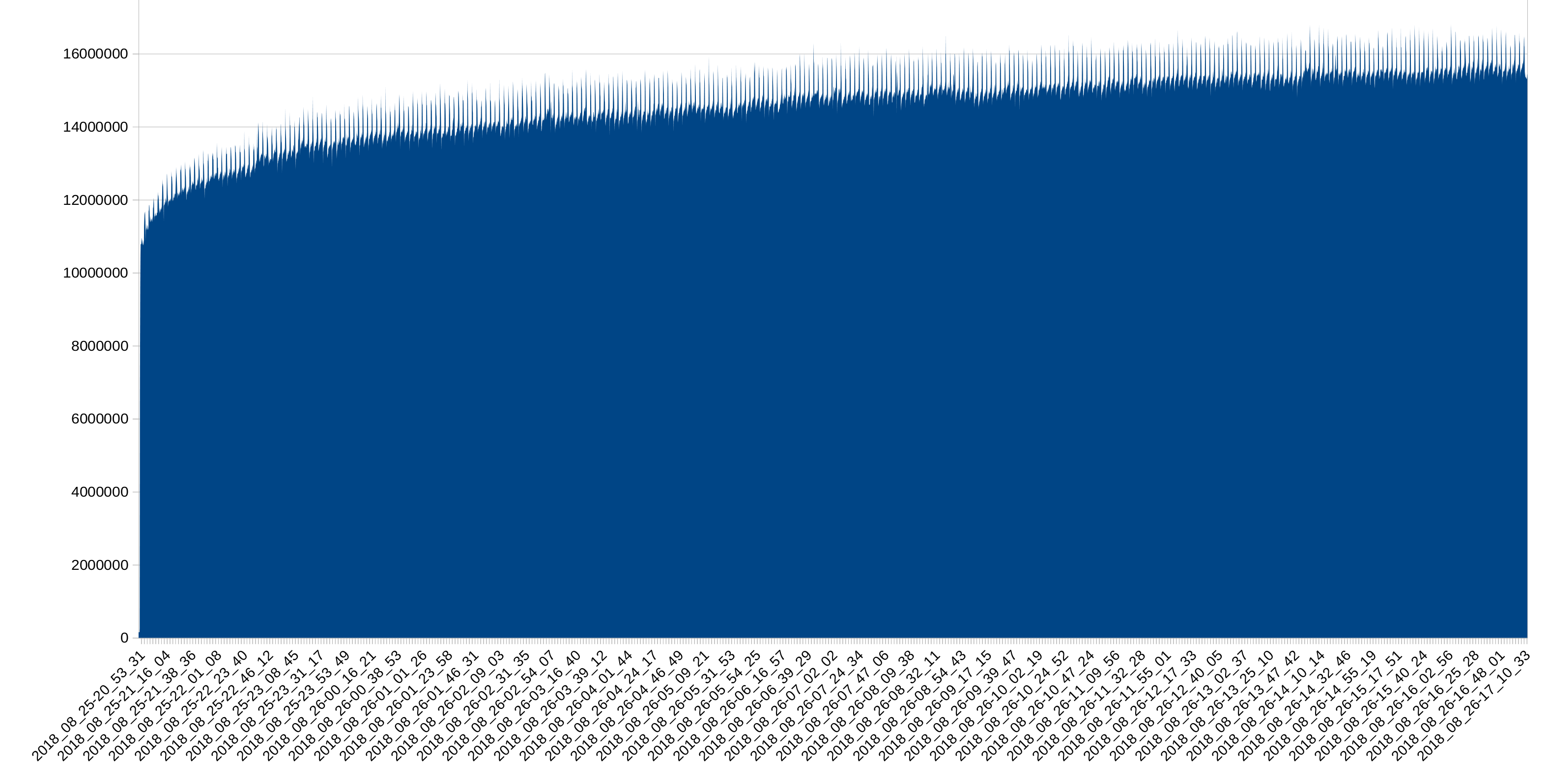
Under the same workload 10.2 eats up all RAM (using 7/8GB ram + 2/8GB Swap) after 2 days, while under 10.1 the ram usage stayed in line with what you would expect.
Unfortunately we can't go back to 10.1, since importing our dataset takes a week.
Our database consists mainly of TokuDB tables, with one table having 9 billion rows. Other tables are in the lower million rows. Total size inclusing indexes is 900GB (uncompressed) and 300GB without indexes.
Workload is lots of reads and inserts, but no deletes.
Strangely the memory balloons most when running the daily stats gathering, which is almost a pure read query, except for some stats entries that get inserted.
We do have a staging server that we can use to run valgrind massive on, and if necessary also on production, since the project is not very critical. However, we are still looking to reproduce the issue on the staging server. Also valgrind massive output does show a lot of '??' entries, even though we installed mariadb-server-core-dgbsym, mariadb-server-dbgsym and mariadb-plugins-tokudb-dbgsym.
I will try to replicate the issue on the staging environment or otherwise use valgrind on production. However, I am not sure if massive option doesn't use much extra ram, making it hard to actually get to the ballooned ram issue.
I attached the most relevant output from mysql and some graphs from grafana.
Let me know if you need more.
Attachments
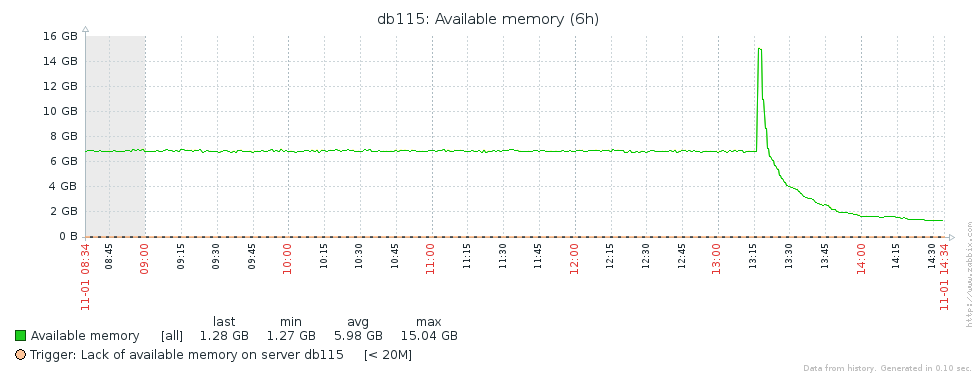
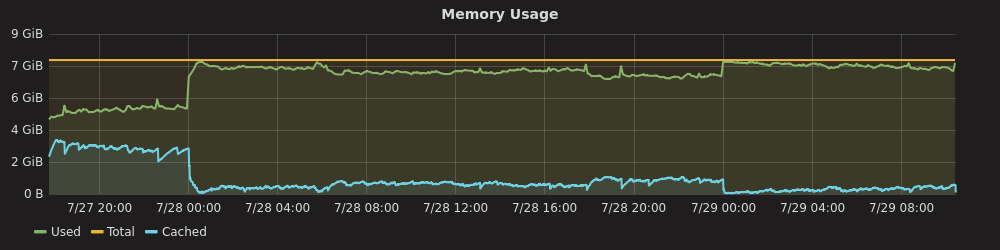

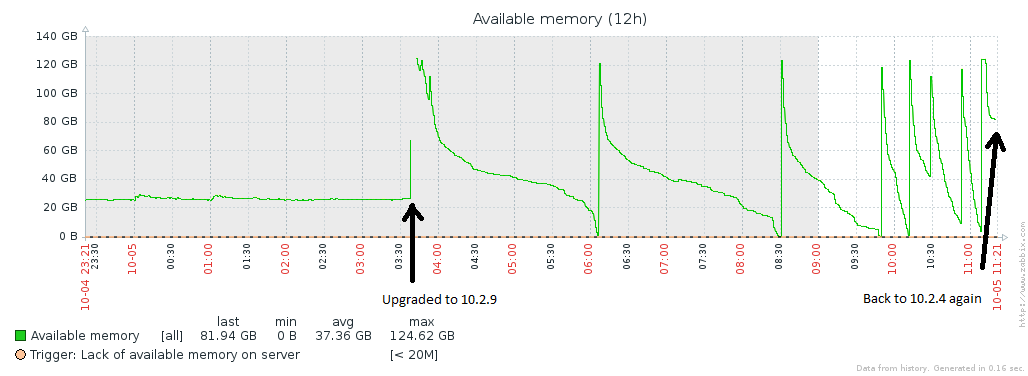
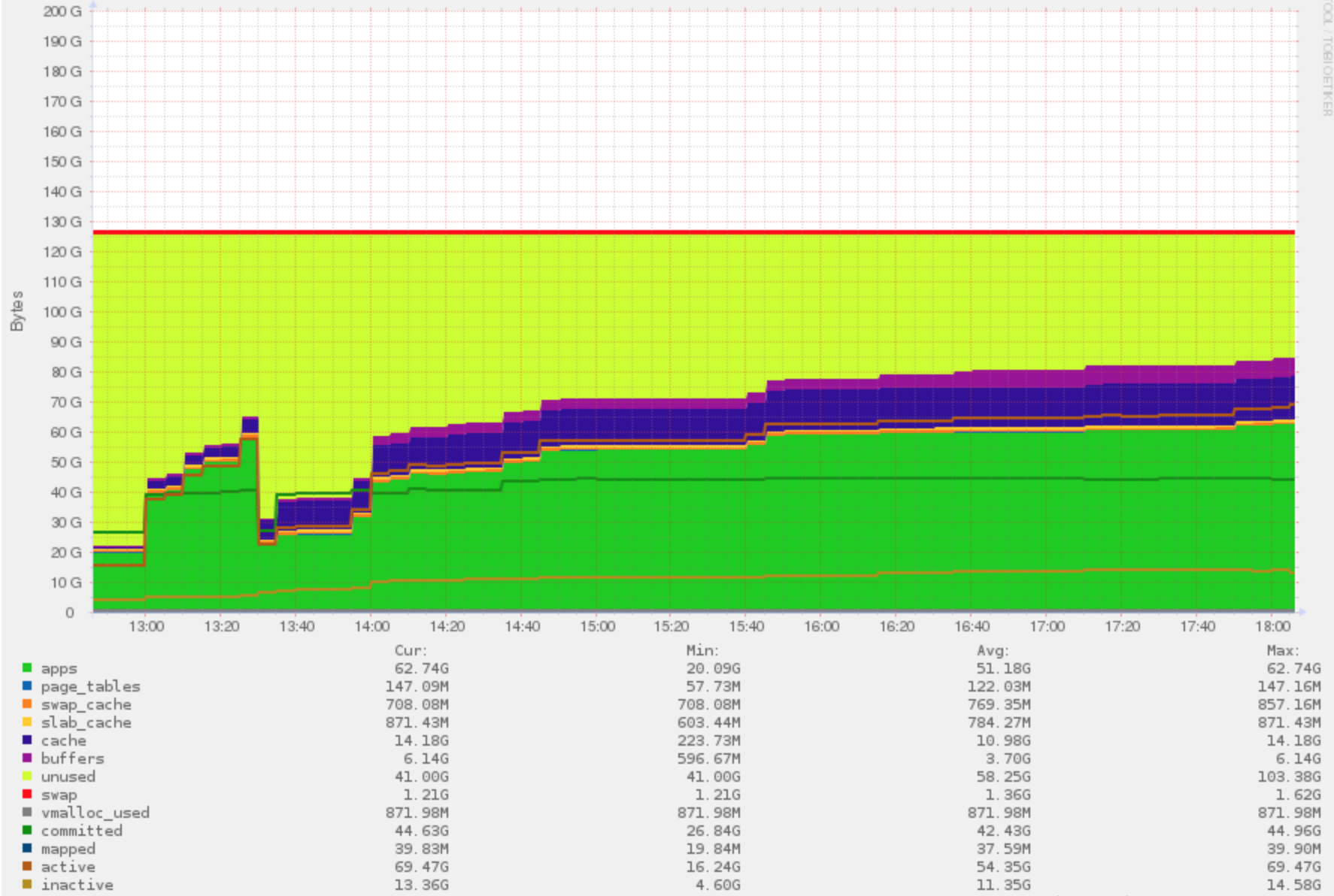
Issue Links
- is duplicated by
-
-

- Closed
-
- relates to
-
-

- Closed
-