Details
-
New Feature
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
6.1.1
-
None
-
2021-10, 2021-11, 2021-12, 2021-13, 2021-14, 2021-15
Description
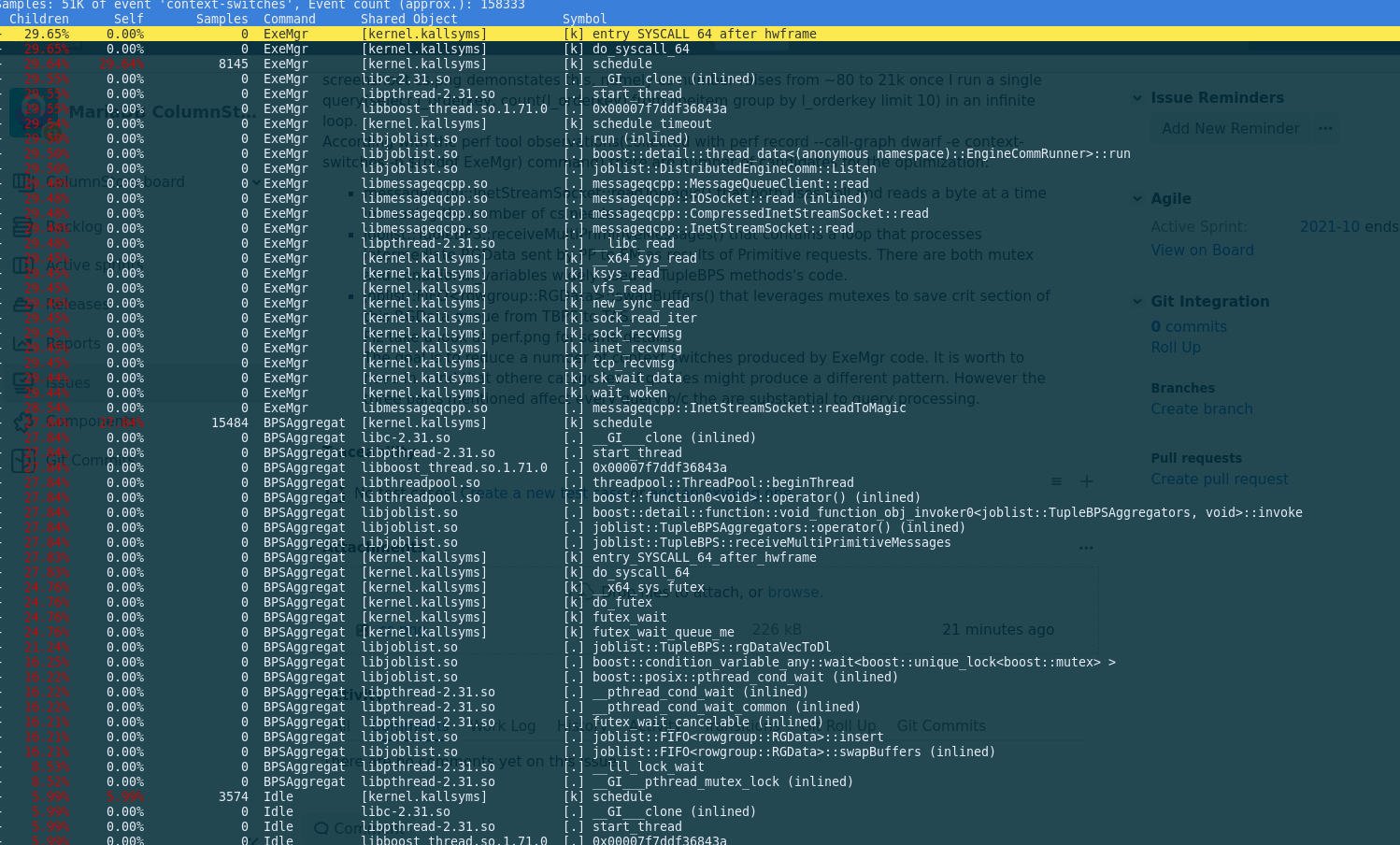
MCS generates enourmous amount of context switches that degrades performance a lot. The screenshoot cs.png demonstates this, namely cs number raises from ~80 to 21k once I run a single query(select l_orderkey, count(l_orderkey) from lineitem group by l_orderkey limit 10) in an infinite loop.
According with the perf tool observations(collected with perf record --call-graph dwarf -e context-switches -p $(pidof ExeMgr) command) there are number of candidates for the optimization:
- messageqcpp::InetStreamSocket::readToMagic() that both uses poll and reads a byte at a time increasing the number of cs needed.
- joblist::TupleBPS::receiveMultiPrimitiveMessages() that contains a loop that processes intermediate RGData sent by PP to EM as results of Primitive requests. There are both mutex and conditional_variables widely used in TupleBPS methods's code.
- joblist::FIFO<rowgroup::RGData>::swapBuffers() that leverages mutexes to save crit section of this RGData queue from TBPS to TAS.
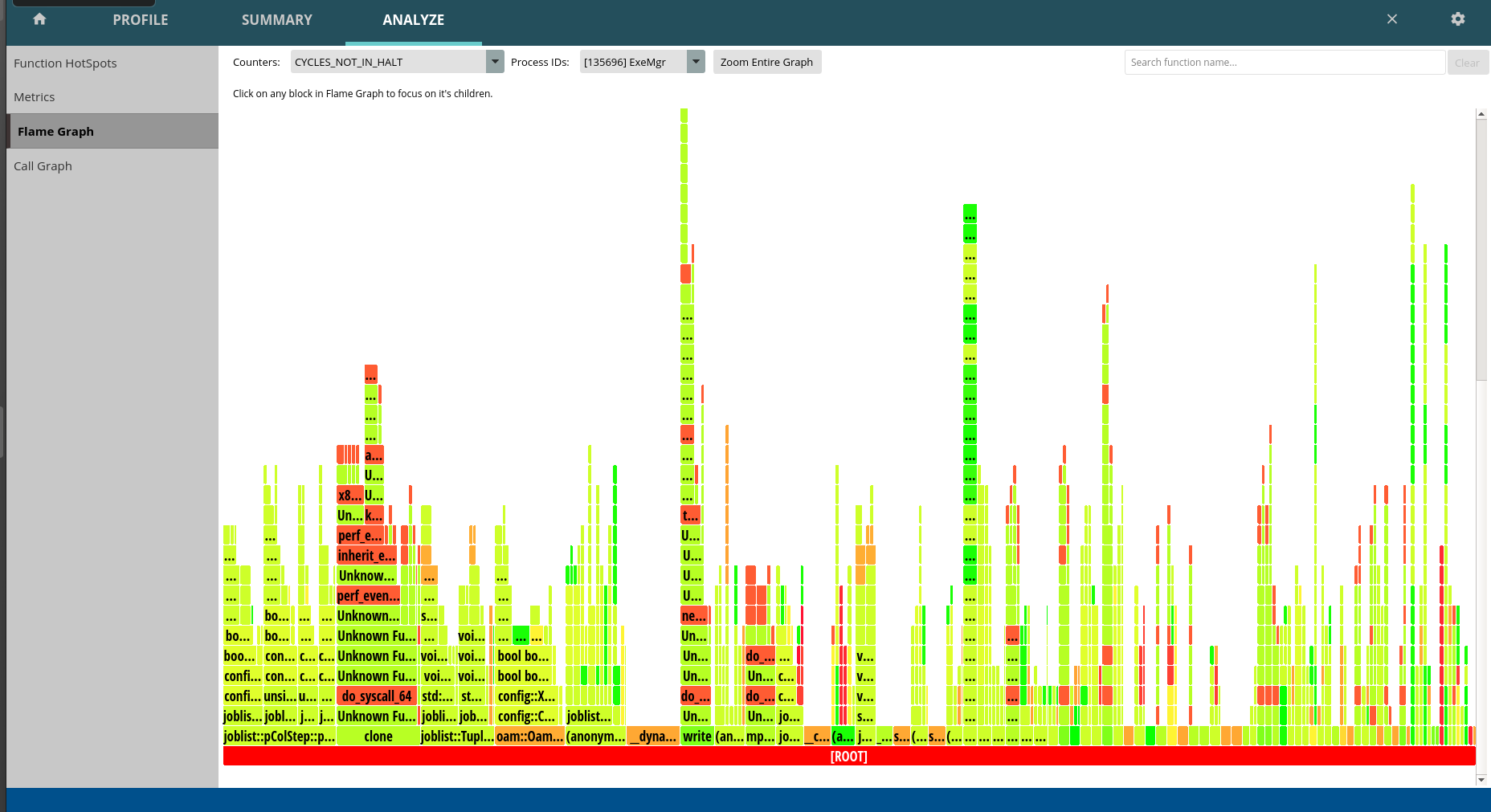
Plz take a look at perf.png for some details.
The goal is to reduce a number of context switches produced by ExeMgr code. It is worth to have in mind that othere categories of queries might produce a different pattern. However the three parts mentioned affect every query b/c the are substantial to query processing.
Attachments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Issue Links
- relates to
-
MCOL-4593 Multiple concurrent queries with aggregates are bottlenecked, result in lack of user scalability
-

- Stalled
-