Details
-
Bug
-
Status: Needs Feedback (View Workflow)
-
 Critical
Critical
-
Resolution: Unresolved
-
10.11.9
-
Debian 12(ARM)
Description
We have recently upgraded MariaDB from 10.11.7 to 10.11.9 in all environments and have recently encountered some corruption errors in the tablespaces and indexes.
Attachments


Issue Links
- relates to
-
-

- Closed
-
Activity
@Stephen Hames. We have a modular application. When modules aren't used, tables don't have any rows. Yet they still experience corruption. We've had corruption on empty tables, that never contained any rows, and we are sure of it (because the module was never activated and authorised).
Edit:
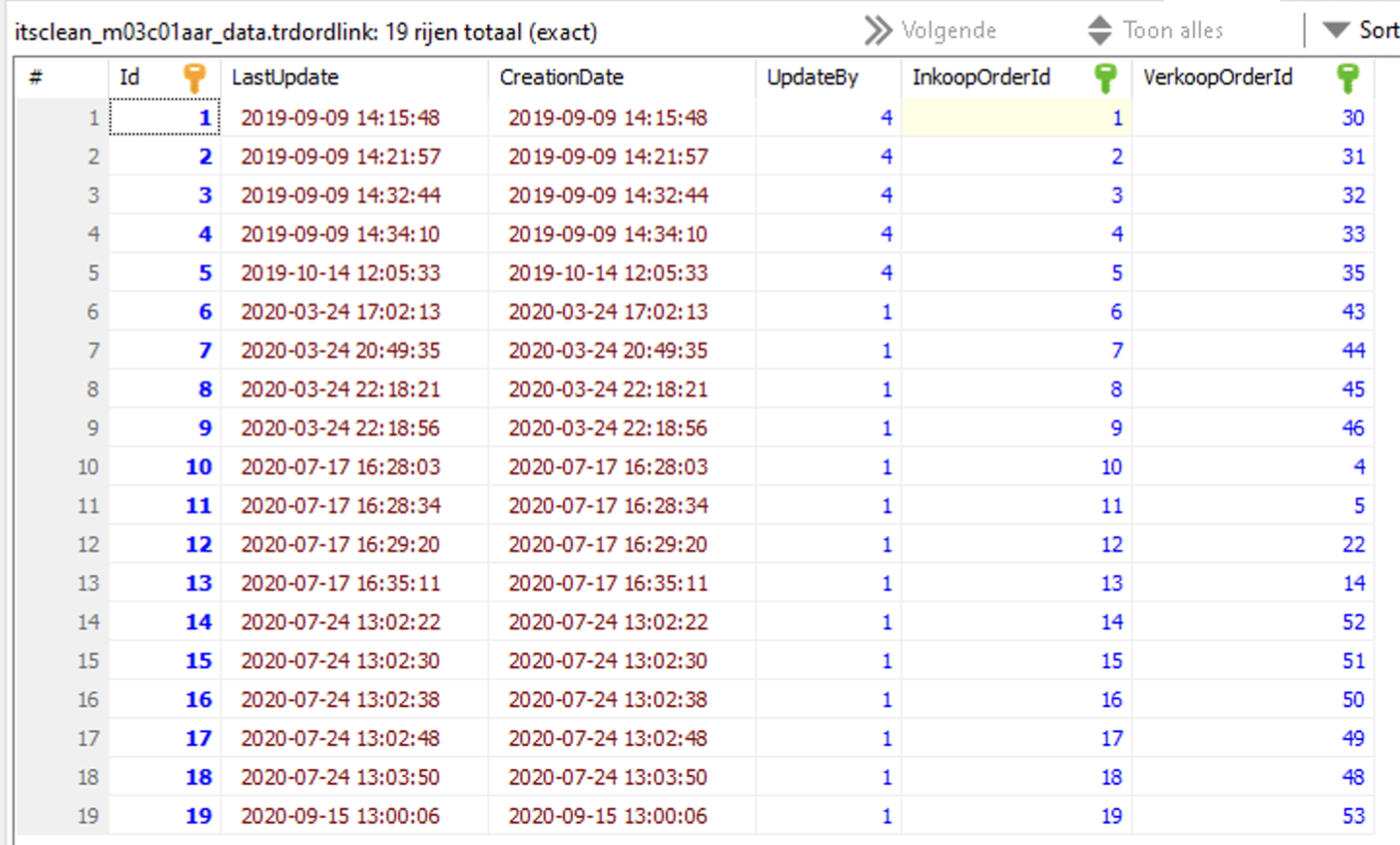
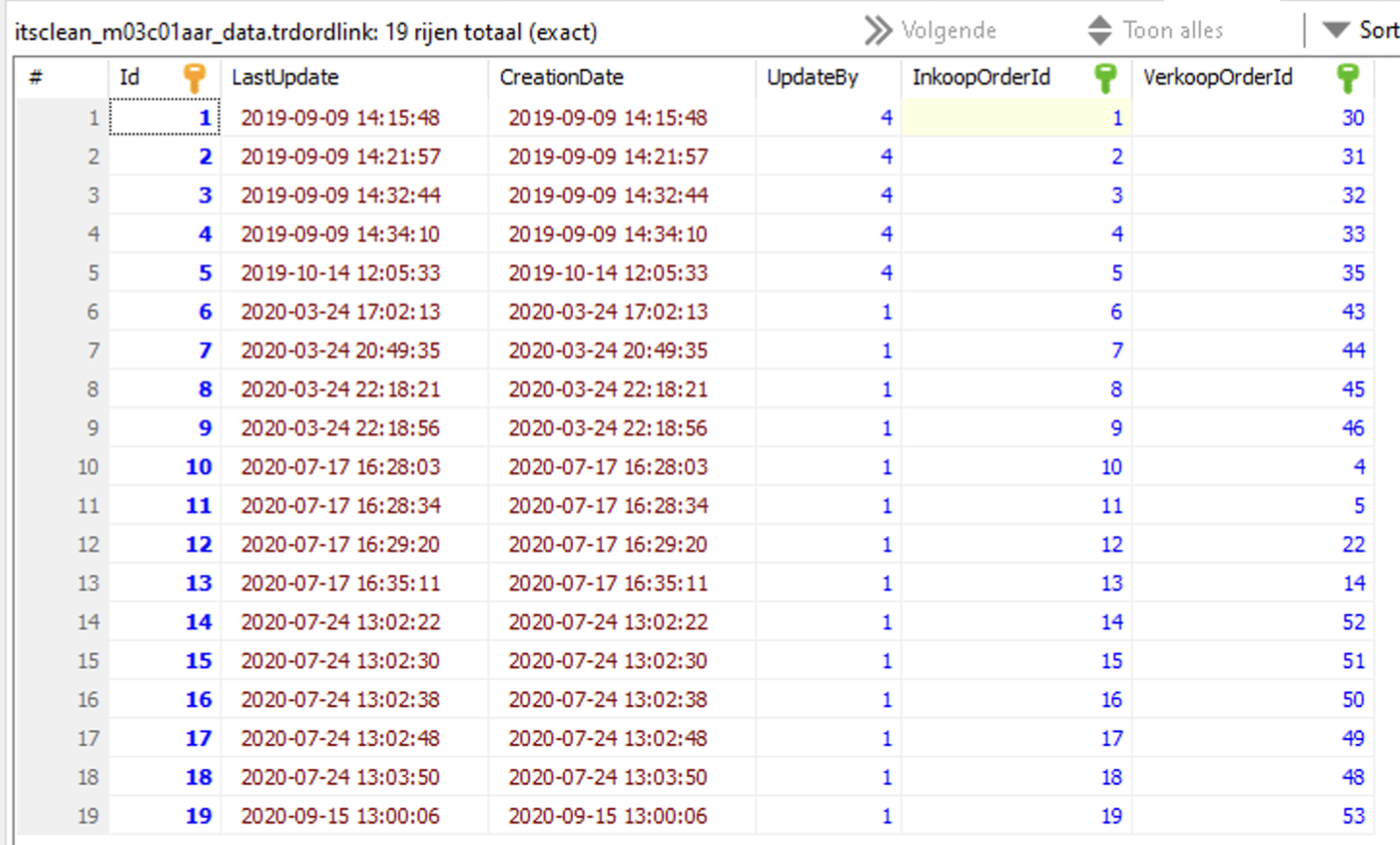
I've included this screenshot that indicates a table that was last modified in 2020. This was the most recently corrupted table (2 days ago). Pretty sure that this table was never written to in more than four years. Only the first byte again was corrupted (01 00 00 00).
jan-willem, we see the same behaviour. Of interest, I added a service restart in one of my processes, and with that, I see corruption on a much more frequent basis. This makes me strongly suspicious that the corruption is happening at server shutdown.
stephen.hames, does the problem actually happen on shutdown, or is it only becoming prominent during shutdown? I mean, could the pages that are corrupted have been written in corrupted form earlier during the mariadbd process lifetime? Have you tried checking the contents of the data files with od -Ax -t x1 -N 4 file.ibd while the server is running? If you force more frequent writes, for example, by SET GLOBAL innodb_max_dirty_pages_pct_lwm=0.01, would you also observe this corruption more frequently before server shutdown?
HI marko,
I actually added that check into the workflow where this is most obvious, and I can see it consistently showing up as soon as the server is restarted...
There is no delay in the steps below:
check table files (no output means no corruption)
restart mysql
check table files again
checking tables BEFORE restart of mysql
|
executing: systemctl restart mysql
|
checking tables AFTER restart of mysql
|
/var/lib/mysql/database_name/victim_table.ibd: 01 00 00 00
|
Just an update on my side. After the kernel update (that resolved the hanging issue) things seem to get better for awhile, and we got through two weeks without any more of these issues.. We were monitoring. Now we've hit this issue again, four times in three days on two separate hosts. Interestingly, two incidents were copies, from approximately same point in time, affecting the same table at about the same time. Neither host have any errors logged. The symptom showed up when maria backup failed on the checksum check. Same 01 00 00 00 for the first four bytes of page 0.
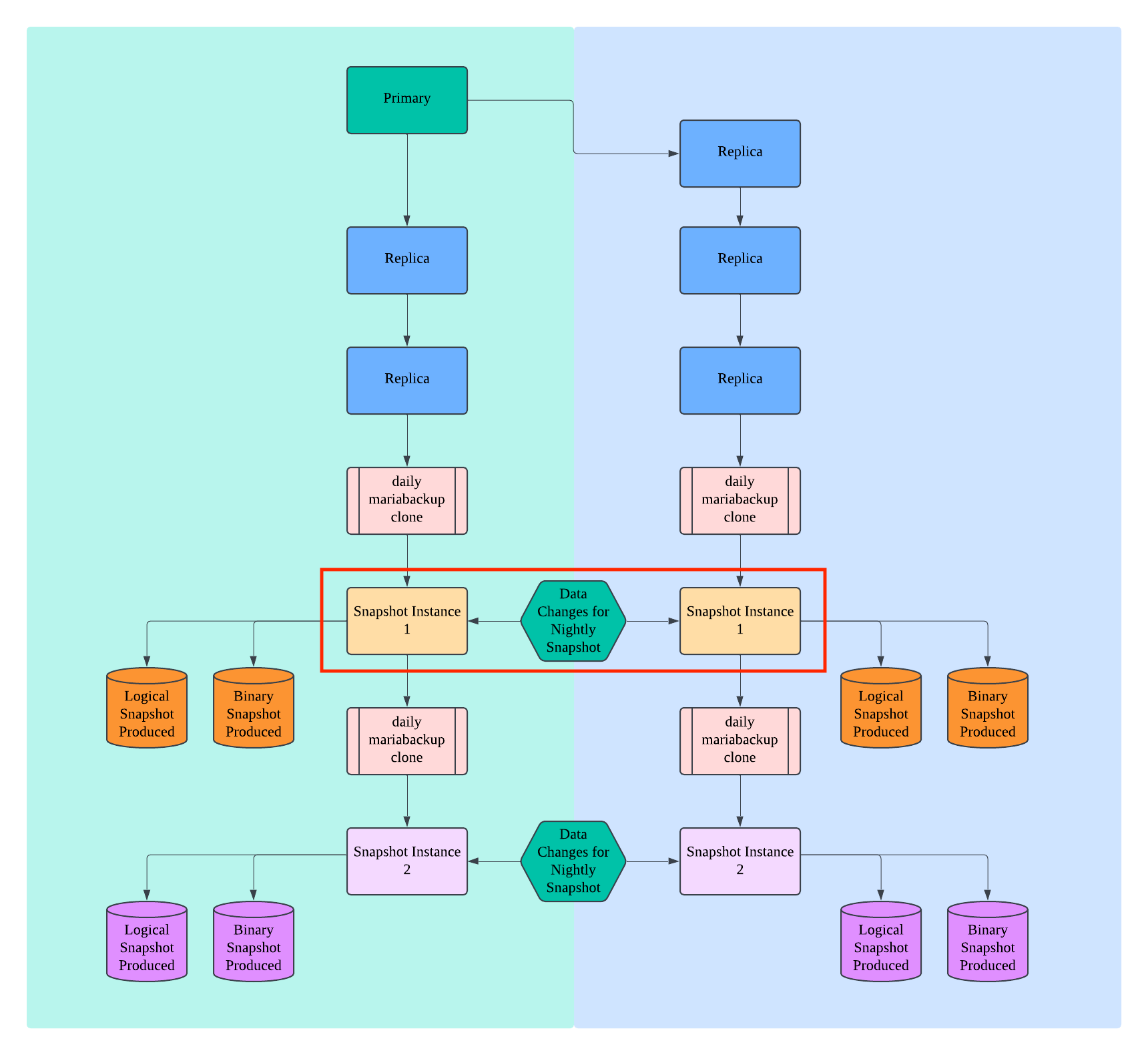
I recently modified the workflow to restart mariadb with fast shutdown disabled to reduce mariabackup prepare time.
Prior to the service restart, we do a lot of bulk deletes. The victim table in this instance is one that receives a cascade delete.
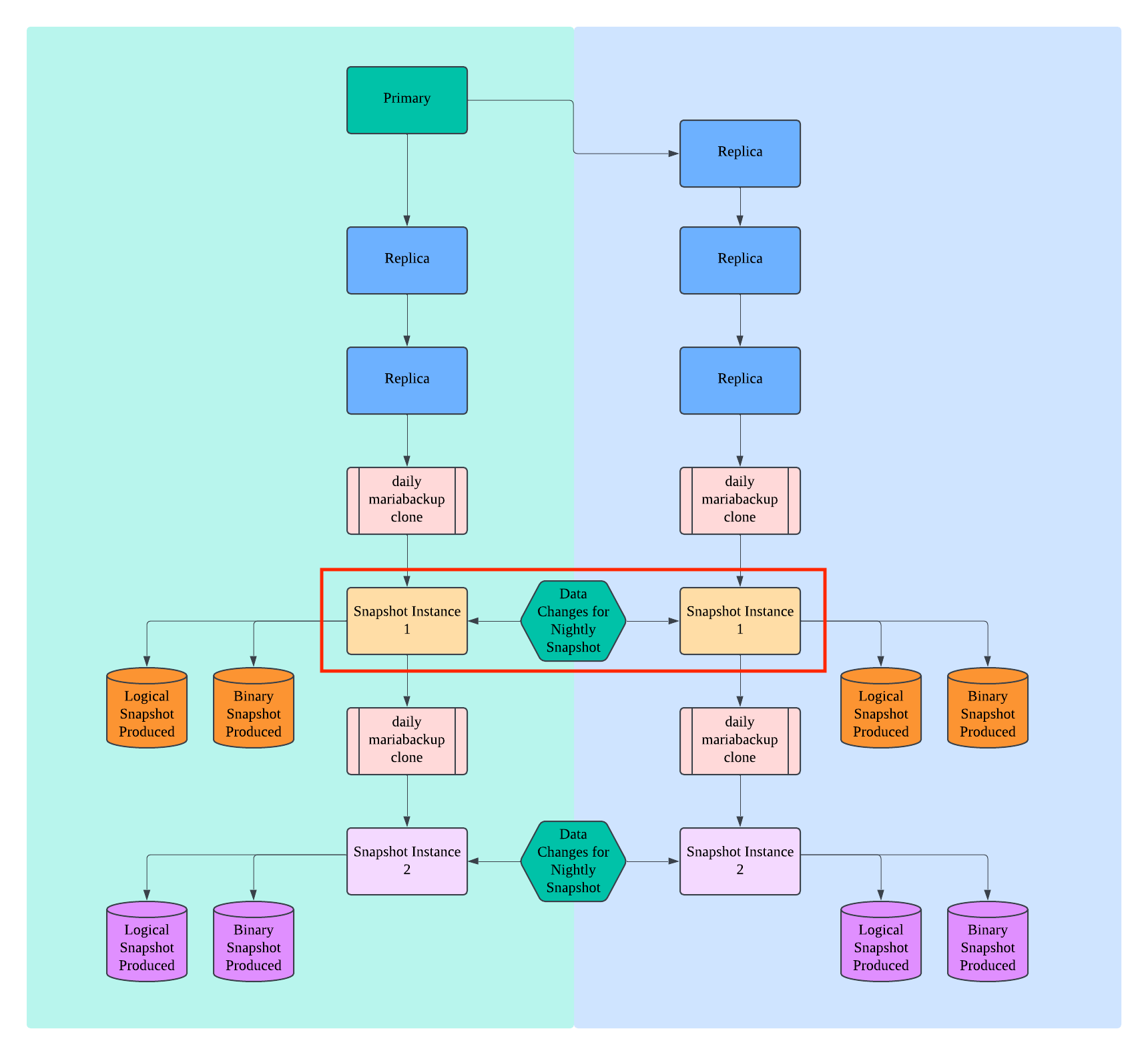
xan.charbonnet, all of our hosts are AWS ec2, both x86_64 and arm64 have shown this issue.
Interesting observation: We have not seen this issue on our legacy CentOS 7 instances. Only on Debian 12 instances.
Interesting observation #2: One of the victim tables on one of the replicas is a backup table that has not had any reads or writes via query in over two years. So am unsure why an otherwise unmodified table would also suffer page0 corruption.