Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Incomplete
-
10.11.9
-
Debian 12(ARM)
Description
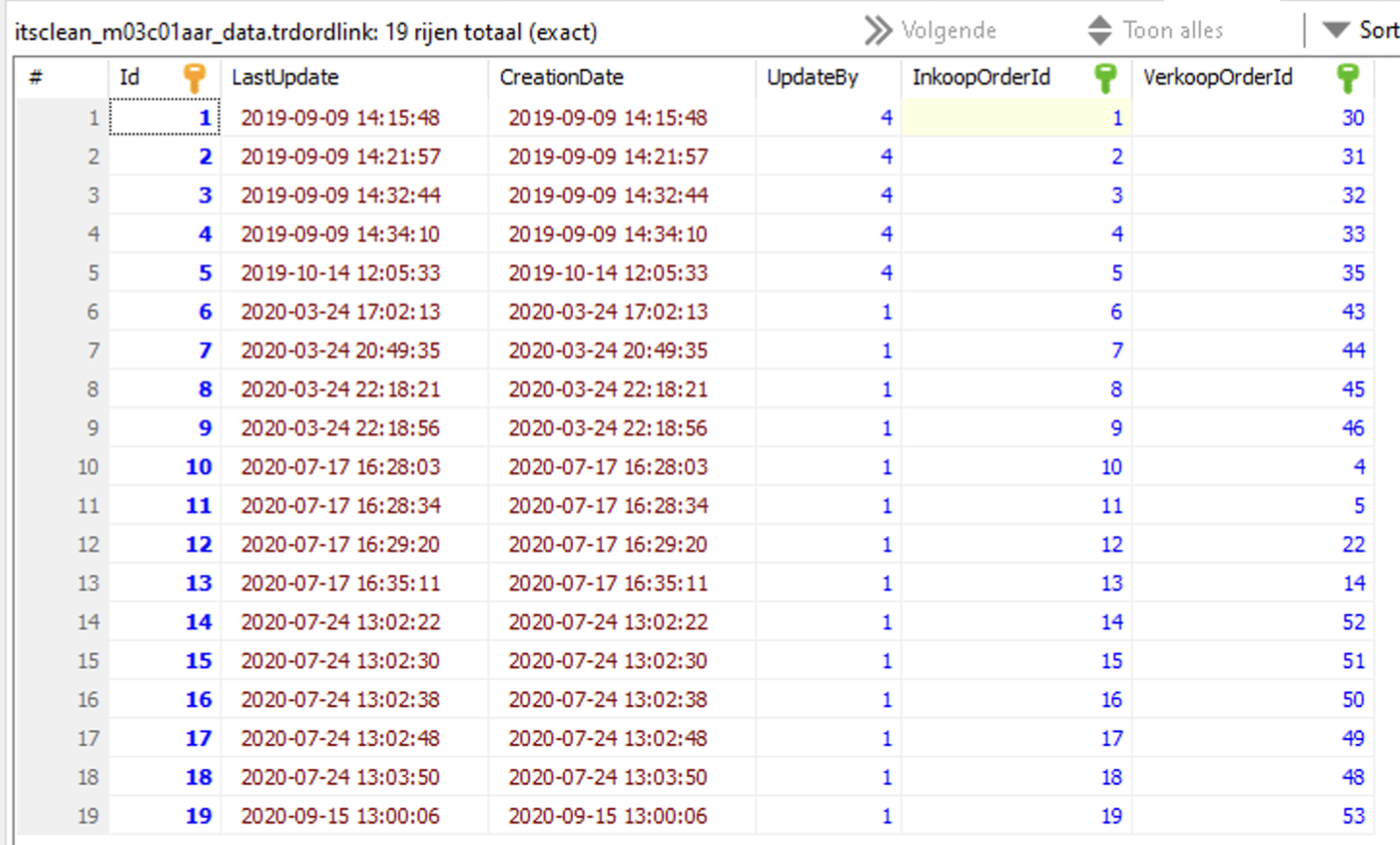
We have recently upgraded MariaDB from 10.11.7 to 10.11.9 in all environments and have recently encountered some corruption errors in the tablespaces and indexes.
Attachments


Issue Links
- relates to
-
-

- Closed
-
