Details
-
Bug
-
Status: Stalled (View Workflow)
-
 Critical
Critical
-
Resolution: Unresolved
-
None
-
Q4/2025 Server Maintenance, Q3/2026 Server Maintenance
Description
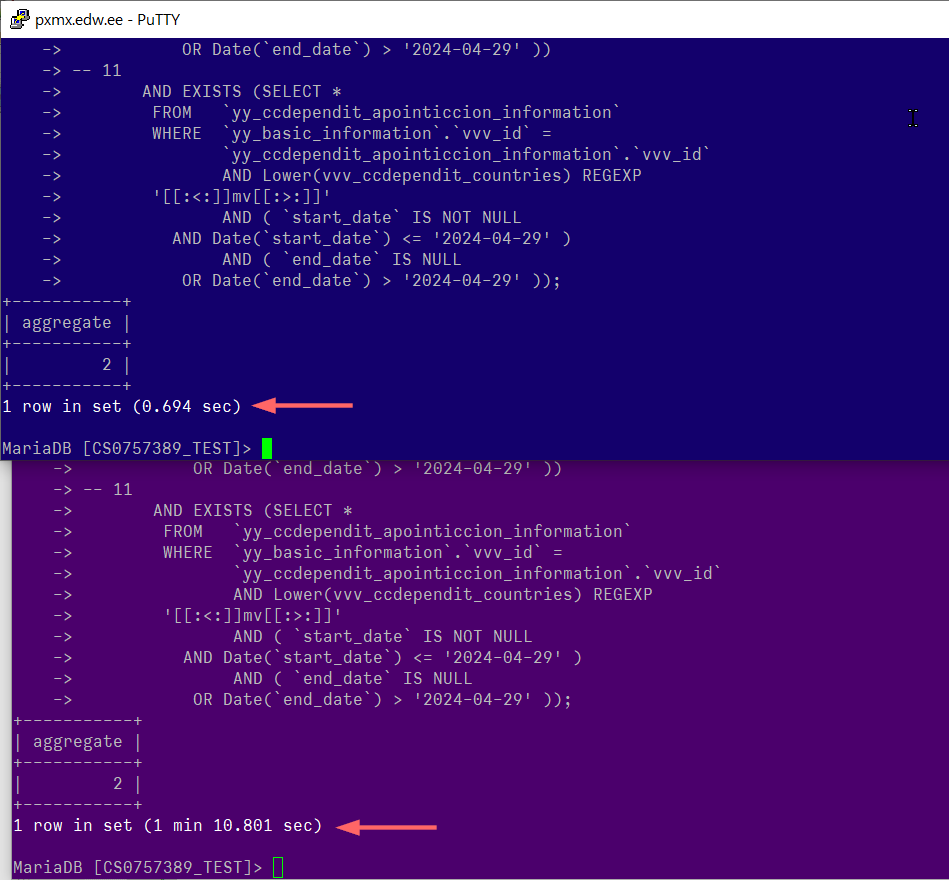
The query has many subqueries with EXISTS (SELECT ...)
10.5 can handle all 26 of these.
10.11 can reach up to 11 of these at which point it gets exponentially slower for each subquery added.
Attachments
Issue Links
- relates to
-
-

- Stalled
-