Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Incomplete
-
10.11.7
-
Ubuntu 22.04
Description
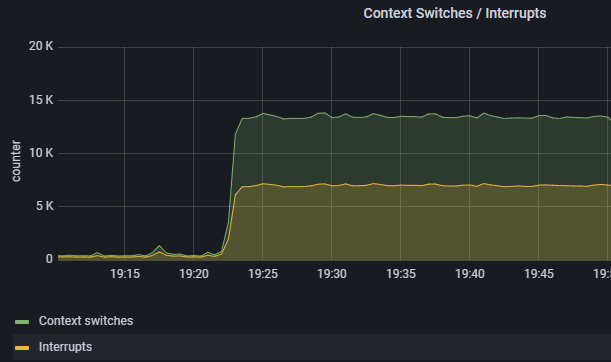
The MariaDB server hangs intermittently for us on a production system, and unfortunately the issue is not reliably reproducible. The last time this happened, two subprocesses of the server hanged, with an increase in context switches for them as observed via htop.
Here are the stack traces captured for these two processes, which seemed to have only one thread:
(gdb) attach 2301451
|
Attaching to program: target:/usr/sbin/mariadbd, process 2301451
|
`target:/usr/sbin/mariadbd' has disappeared; keeping its symbols.
|
warning: .dynamic section for "target:/lib/x86_64-linux-gnu/libuuid.so.1" is not at the expected address (wrong library or version mismatch?)
|
Reading symbols from target:/lib/x86_64-linux-gnu/libpcre2-8.so.0...
|
(No debugging symbols found in target:/lib/x86_64-linux-gnu/libpcre2-8.so.0)
|
Reading symbols from target:/lib/x86_64-linux-gnu/libcrypt.so.1...
|
(No debugging symbols found in target:/lib/x86_64-linux-gnu/libcrypt.so.1)
|
.
|
.
|
.
|
[Thread debugging using libthread_db enabled]
|
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
|
0x00007fd73b7f47f8 in __GI___clock_nanosleep (clock_id=clock_id@entry=0, flags=flags@entry=0, req=0x7fd6841145c0, rem=0x7fd6841145c0) at ../sysdeps/unix/sysv/linux/clock_nanosleep.c:78
|
78 ../sysdeps/unix/sysv/linux/clock_nanosleep.c: No such file or directory.
|
(gdb) bt
|
#0 0x00007fd73b7f47f8 in __GI___clock_nanosleep (clock_id=clock_id@entry=0, flags=flags@entry=0, req=0x7fd6841145c0, rem=0x7fd6841145c0) at ../sysdeps/unix/sysv/linux/clock_nanosleep.c:78
|
#1 0x00007fd73b7f9677 in __GI___nanosleep (req=<optimized out>, rem=<optimized out>) at ../sysdeps/unix/sysv/linux/nanosleep.c:25
|
#2 0x000056402673f831 in ?? ()
|
#3 0x0000564026ed7e8a in ?? ()
|
#4 0x0000564026ee29b5 in ?? ()
|
#5 0x0000564026e5309b in ?? ()
|
#6 0x0000564026e56ac6 in ?? ()
|
#7 0x0000564026e56e22 in ?? ()
|
#8 0x0000564026e68dbe in ?? ()
|
#9 0x0000564026db18fa in ?? ()
|
#10 0x0000564026ad01e0 in handler::ha_write_row(unsigned char const*) ()
|
#11 0x000056402681d6cd in write_record(THD*, TABLE*, st_copy_info*, select_result*) ()
|
#12 0x000056402682745f in mysql_insert(THD*, TABLE_LIST*, List<Item>&, List<List<Item> >&, List<Item>&, List<Item>&, enum_duplicates, bool, select_result*) ()
|
#13 0x000056402685c148 in mysql_execute_command(THD*, bool) ()
|
#14 0x0000564026860b97 in mysql_parse(THD*, char*, unsigned int, Parser_state*) ()
|
#15 0x000056402686338d in dispatch_command(enum_server_command, THD*, char*, unsigned int, bool) ()
|
#16 0x0000564026865288 in do_command(THD*, bool) ()
|
#17 0x000056402698caef in do_handle_one_connection(CONNECT*, bool) ()
|
#18 0x000056402698ce3d in handle_one_connection ()
|
#19 0x0000564026cf1d56 in ?? ()
|
#20 0x00007fd73b7a3ac3 in start_thread (arg=<optimized out>) at ./nptl/pthread_create.c:442
|
#21 0x00007fd73b835850 in clone3 () at ../sysdeps/unix/sysv/linux/x86_64/clone3.S:81
|
and
(gdb) bt
|
#0 0x00007fd73b7f47f8 in __GI___clock_nanosleep (clock_id=clock_id@entry=0, flags=flags@entry=0,
|
req=0x7fd6841f5c60, rem=0x7fd6841f5c60) at ../sysdeps/unix/sysv/linux/clock_nanosleep.c:78
|
#1 0x00007fd73b7f9677 in __GI___nanosleep (req=<optimized out>, rem=<optimized out>)
|
at ../sysdeps/unix/sysv/linux/nanosleep.c:25
|
#2 0x000056402673f831 in ?? ()
|
#3 0x0000564026ed7e8a in ?? ()
|
#4 0x00005640266dbe5b in ?? ()
|
#5 0x0000564026ee264a in ?? ()
|
#6 0x0000564026e78a5c in ?? ()
|
#7 0x0000564026f7d59d in ?? ()
|
#8 0x0000564026f7de84 in ?? ()
|
#9 0x0000564026e86128 in ?? ()
|
#10 0x0000564026e3ca52 in ?? ()
|
#11 0x0000564026ea6824 in ?? ()
|
#12 0x0000564026ea5655 in ?? ()
|
#13 0x0000564026d9d572 in ?? ()
|
#14 0x0000564026ac4c40 in ha_rollback_trans(THD*, bool) ()
|
#15 0x000056402699db07 in trans_rollback(THD*) ()
|
#16 0x000056402685e5ff in mysql_execute_command(THD*, bool) ()
|
#17 0x0000564026860b97 in mysql_parse(THD*, char*, unsigned int, Parser_state*) ()
|
#18 0x000056402686338d in dispatch_command(enum_server_command, THD*, char*, unsigned int, bool) ()
|
#19 0x0000564026865288 in do_command(THD*, bool) ()
|
#20 0x000056402698caef in do_handle_one_connection(CONNECT*, bool) ()
|
#21 0x000056402698ce3d in handle_one_connection ()
|
#22 0x0000564026cf1d56 in ?? ()
|
#23 0x00007fd73b7a3ac3 in start_thread (arg=<optimized out>) at ./nptl/pthread_create.c:442
|
#24 0x00007fd73b835850 in clone3 () at ../sysdeps/unix/sysv/linux/x86_64/clone3.S:81
|
Attachments
Issue Links
- relates to
-
-
- Closed
-
-
-

- Closed
-