Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Duplicate
-
10.11.6
-
official docker images running in kubernetes cluster
Description
Hello,
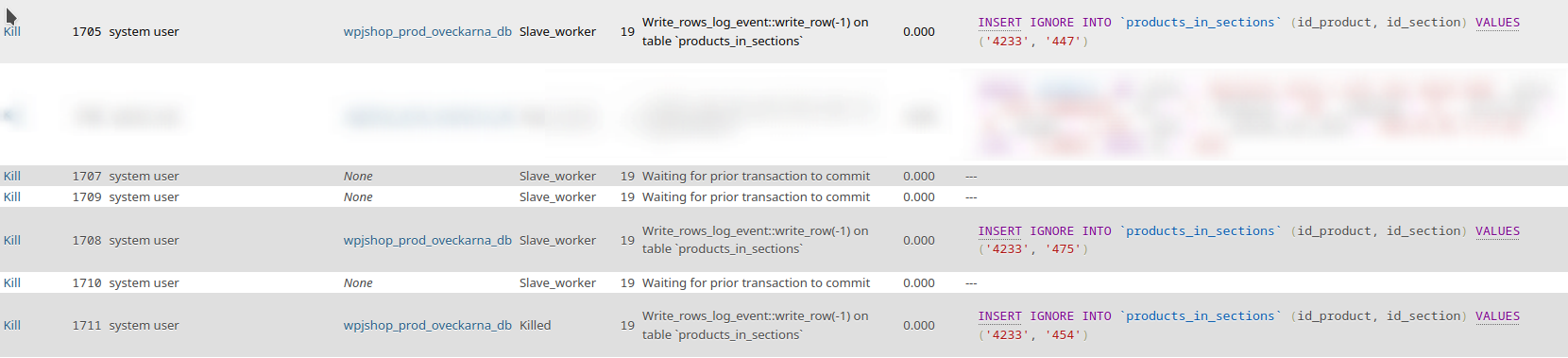
we have 1 master, 9 slaves. All slaves connects from the same master. All slaves started from same snapshot, completely same process. Probably after upgrade from 10.6 to 10.11 every few days random slave errors with
Could not execute Write_rows_v1 event on table ??????.??????; Duplicate entry '8-7' for key 'id_section_2', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log mysqld-bin.001693, end_log_pos 899067800
|
We use MIXED replication mode, no parallel replication, no wsrep.
I do believe it is slave bug, because all other slaves continues without problem. I'm unable to reproduce this on purpose.
Usually the error happens on the same database, same table, but probably this is just the result of another bug in replication that happened earlier.
I understand that this bug report does not contains all the required information, but I need your guidance to provide more relevant data. I can provide binlog or relay log for example.
Attachments
Issue Links
- duplicates
-
-

- Closed
-
- relates to
-
-
- Closed
-
