Details
Description
We have multiple galera clusters working in a multi-master setup. And noticed that a "sleeping" system thread could hung the whole cluster.
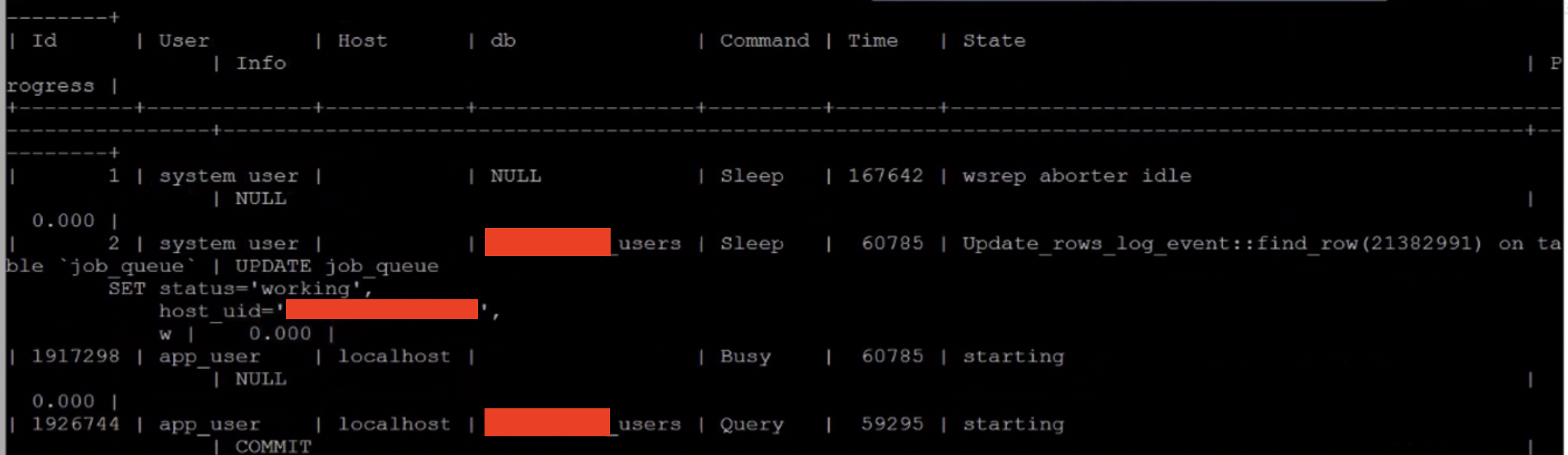
When this system thread hung as shown in the screenshot, the whole galera cluster goes into a stand still. Nothing an be written into the database

We have a log that print the "wsrep_last_committed", it shows that one of the node 's wsrep_last_commited is not moving. Did the wsrep plugin in Galera hung?
The h5 server is the one that stuck. There is nothing in the mysql.err showing any stacktrace
2022-08-18 06:10:04,862 INFO galera_alert line:93 galerastats on node xxx-h4: |
2022-08-18 06:10:04,861 INFO galera_alert line:94 {'error': 0, 'payload': {'output': '{"Threads_connected": "150", "wsrep_last_committed": "21383020", |
2022-08-18 06:10:04,862 INFO galera_alert line:93 galerastats on node xxx-h5: |
2022-08-18 06:10:04,862 INFO galera_alert line:94 {'error': 0, 'payload': {'output': '{"Threads_connected": "590", "wsrep_last_committed": "21382990", |
2022-08-18 06:10:04,863 INFO galera_alert line:93 galerastats on node xxx-h6: |
2022-08-18 06:10:04,863 INFO galera_alert line:94 {'error': 0, 'payload': {'output': '{"Threads_connected": "204", "wsrep_last_committed": "21383020", |
....
|
....
|
2022-08-18 06:30:04,996 INFO galera_alert line:93 galerastats on node xxx-h4: |
2022-08-18 06:30:04,996 INFO galera_alert line:94 {'error': 0, 'payload': {'output': '{"Threads_connected": "170", "wsrep_last_committed": "21383020", |
2022-08-18 06:30:04,997 INFO galera_alert line:93 galerastats on node xxx-h5: |
2022-08-18 06:30:04,997 INFO galera_alert line:94 {'error': 0, 'payload': {'output': '{"Threads_connected": "643", "wsrep_last_committed": "21382990", |
2022-08-18 06:30:04,997 INFO galera_alert line:93 galerastats on node xxx-h6: |
2022-08-18 06:30:04,997 INFO galera_alert line:94 {'error': 0, 'payload': {'output': '{"Threads_connected": "228", "wsrep_last_committed": "21383020", |
The only solution to "unbreak" it is to stop the hung node, kill mariadb and start the mariadb service
Attachments
Issue Links
- is caused by
-
MDEV-29293 MariaDB stuck on starting commit state (waiting on commit order critical section)
-

- Closed
-
- relates to
-
-

- Closed
-
-
-
- Closed
-
Activity
@daniel, does installing the debug-info packages have any performance impact ?
No, they are information only and used by gdb. Small bit of storage but no impacts to the running server or any replacement of code.
@daniel,
Does this means i do not need to install the debug info packages? As my binary is not stripped.
/opt/sbin/mariadbd: ELF 64-bit LSB shared object, x86-64, version 1 (GNU/Linux), dynamically linked (uses shared libs), for GNU/Linux 2.6.32, BuildID[sha1]=893a0b4698fc39d184df3f3c32df693dfa008884, not stripped |
When i tried to gdb attach <pid>, i get these lines. Does that mean i need to install the debuginfo?
Reading symbols from /usr/lib64/libgssapi_krb5.so.2...Reading symbols from /usr/lib64/libgssapi_krb5.so.2...(no debugging symbols found)...done. |
The binary is not technically stripped however a split-debug technique commonly used means that the debug info isn't in the binary, but in separate files, hence the debuginfo packages are still needed.
Missing debug information from the libraries mariadb uses isn't a large impediment as the fault is unlikely to be in these libraries. If in doubt, just include the generated gdb information.
If for some reason you feel uncomfortable with the detail in the gdb output you can upload it privately to the ftp server.
@daniel, we are building our own mariadb using the spec file , however the debuginfo rpm is not getting generated for 10.6.5 , however it is getting generated for 10.6.9
any idea what could be causing it?
| Field | Original Value | New Value |
|---|---|---|
| Assignee | Jan Lindström [ jplindst ] |
> we are building our own mariadb using the spec file ,
Why? What is it?
> however the debuginfo rpm is not getting generated for 10.6.5 , however it is getting generated for 10.6.9
> any idea what could be causing it?
No. I could guess the cmake version is different. But I can't think of a code change that made this difference.
hi daniel, the command provided by the doc does not seems to work in my system.
sudo gdb --batch --eval-command="thread apply all bt -frame-arguments all full" /usr/sbin/mariadbd $(pgrep -xn mariadbd) > mariadbd_full_bt_all_threads.txt |
The command above give me output like this
[New LWP 27304] |
[New LWP 27303] |
[New LWP 27110] |
...
|
...
|
[New LWP 29265] |
[Thread debugging using libthread_db enabled]
|
Using host libthread_db library "/usr/lib64/libthread_db.so.1". |
0x00007f4727783ccd in poll () from /usr/lib64/libc.so.6 |
|
|
Thread 100 (Thread 0x7f4729b7c700 (LWP 29265)): |
[Inferior 1 (process 29263) detached] |
However, this alternate command seems to be working
sudo gdb --batch --eval-command="thread apply all bt full" /usr/sbin/mariadbd $(pgrep -xn mariadbd) > mariadbd_full_bt_all_threads.txt |
Sample output looks like this, is this something you guys are looking for?
Thread 1 (Thread 0x7f4729cfc8c0 (LWP 29263)): |
#0 0x00007f4727783ccd in poll () from /usr/lib64/libc.so.6 |
No symbol table info available.
|
#1 0x000055b20755e7ca in poll (__timeout=-1, __nfds=<optimized out>, __fds=<optimized out>) at /usr/include/bits/poll2.h:46 |
No locals.
|
#2 handle_connections_sockets() () at /usr/src/debug/MariaDB-Galera-/src_0/sql/mysqld.cc:6112 |
sock = {fd = 33, is_unix_domain_socket = <optimized out>, is_extra_port = <optimized out>, address_family = <optimized out>, m_psi = 0x0} |
error_count = 0 |
cAddr = {ss_family = 1, |
__ss_padding = "\263$\177\000\000\001\000\000\000\000\000\000\000\000p\017\340\v\262U\000\000h\210\220\304\376\177\000\000\200%c\b\262U\000\000G*\344\a\262U\000\000\352\f\000\000\000\000\000\000\330+\344\a\262U\000\000\270\nc\b\262U\000\000\060Bc\b\262U\000\000\000\000\000\000\000\000\000\000!\000\000\000\000\000\000\000\300s\220\304\376\177\000\000I\002X\a\262U\000\000\023p\372\a\262U\000", __ss_align = 0} |
retval = <optimized out>
|
fds = {array = {buffer = 0x55b20bd5d808 "\037", elements = 3, max_element = 16, alloc_increment = 16, size_of_element = 8, m_psi_key = 0, malloc_flags = 0}} |
#3 0x000055b20755f739 in mysqld_main(int, char**) () at /usr/src/debug/MariaDB-Galera-/src_0/sql/mysqld.cc:5817 |
please_close_stdin = true |
ho_error = <optimized out>
|
new_thread_stack_size = <optimized out>
|
user = <optimized out>
|
---Type <return> to continue, or q <return> to quit--- |
#4 0x00007f47276b2555 in __libc_start_main () from /usr/lib64/libc.so.6 |
No symbol table info available.
|
#5 0x000055b207553ec4 in _start () at /usr/src/debug/MariaDB-Galera-/src_0/sql/sql_array.h:129 |
| Fix Version/s | 10.6 [ 24028 ] |
khaiping.loh Yes, that output would be more than useful. Please provide also full error log. Can you try with more recent version of MariaDB and Galera library.
| Status | Open [ 1 ] | Needs Feedback [ 10501 ] |
| Link |
This issue relates to |
> Please provide also full error log
and the full output of the sudo gdb --batch ....
| Attachment | mariadbd_full_bt_all_threads.txt [ 68208 ] |
@daniel , i have attached mariadbd_full_bt_all_threads.txt![]() .
.
Is this issue resolve in mariadb 10.6.12? I am referencing this ticket https://jira.mariadb.org/browse/MDEV-29684, it seems like it is fixed?
Thank you. What analysis have you done that makes you think it is MDEV-29684?
This does have killed threads holding locks so it potentially the same, but a more complete look than what I have time for now is required to be more definate.
| Assignee | Jan Lindström [ jplindst ] | Julius Goryavsky [ sysprg ] |
| Status | Needs Feedback [ 10501 ] | Open [ 1 ] |
- Due to the release notes , https://mariadb.com/kb/en/mariadb-10-6-12-release-notes/ . It mention "Fixes for cluster wide write conflict resolving"
- In my environment, we only see this problem in multi master galera nodes. Our application can send the writes to any of the galera nodes. In high concurrency, there is bound to have galera write conflicts. In
MDEV-29684, it mention this line "This requires multi-master testing" - And also in
MDEV-29684, the first sentence mention this "There are a number of bug reports of cluster wide conflict resolving related crashes or hangs." When this issue happens in our environment, nothing can be written anymore, it is as tho the cluster hung
Appreciate your prompt response, i hope the bt thread logs is helpful. That log is retrieve from the node that hung.
| Attachment | mariadbd_full_bt_all_threads_11feb246.txt [ 68215 ] |
@Julius Goryavsky , any idea if the logs were useful in helping to find out if it is related to MDEV-29684?
| Status | Open [ 1 ] | In Progress [ 3 ] |
Automated message:
----------------------------
Since this issue has not been updated since 6 weeks, it's time to move it back to Stalled.
Automated message:
----------------------------
Since this issue has not been updated since 6 weeks, it's time to move it back to Stalled.
| Status | In Progress [ 3 ] | Stalled [ 10000 ] |
| Priority | Critical [ 2 ] | Major [ 3 ] |
| Link |
This issue relates to |
| Assignee | Julius Goryavsky [ sysprg ] | Seppo Jaakola [ seppo ] |
| Assignee | Seppo Jaakola [ seppo ] | Jan Lindström [ JIRAUSER53125 ] |
| Status | Stalled [ 10000 ] | Needs Feedback [ 10501 ] |
khaiping.loh Can you provide full unedited error log from node that hangs, show processlist, show engine innodb status? Is issue reproducible? If it is can you provide steps to reproduce. Used MariaDB server and Galera library versions are quite old, please consider upgrading to more recent ones. More recent version has fixes on cluster conflict hang cases and this could be one of them.
Jan Lindström , when the issue happen is there is no errors on the mysql.err. However, when we go into one of the node, the processlist will show a system_user thread stuck indefinitely.
Do you know which version have those fixes related to cluster hanging? Is it 10.6.15?
khaiping.loh I looked the stack trace and I can find selects from there but not that update-clause. I do not see any real evidence that server would be hang. https://mariadb.com/kb/en/mariadb-10-6-12-release-notes/ contains the fix but https://mariadb.com/kb/en/mariadb-10-6-17-release-notes/ is the latest and recommended release.
Jan Lindström , i noticed this changelog in 10.6.15 as well. Could this help also?
MariaDB stuck on starting commit state (waiting on commit order critical section) (MDEV-29293)
Looking at the performance regression in MDEV-33508, i do not think upgrading it to 10.6.17 should be recommended?
khaiping.loh Yes it would help, but then I did not see evidence you are hitting it. I do not know how severe the performance regression is.
| Attachment | mariadb stacktrace.zip [ 73413 ] |
@jan, i uploaded another set of stacktrace of another cluster whereby 1 node hung. Inside the logs contain 3 servers.
[^mariadb stacktrace.zip]
khaiping.loh I can't read those MAXOS files but I strongly suspect https://jira.mariadb.org/browse/MDEV-29293 for that you would need to upgrade.
| Attachment | mariadb stacktrace.zip [ 73413 ] |
| Attachment | mariadbd_full_bt_all_threads-h14_1712676357.log [ 73414 ] | |
| Attachment | mariadbd_full_bt_all_threads-h15_1712676357.log [ 73415 ] | |
| Attachment | mariadbd_full_bt_all_threads-h12_1712676357.log [ 73416 ] |
@jan , i uploaded the non-zip files.
mariadbd_full_bt_all_threads-h12_1712676357.log![]()
mariadbd_full_bt_all_threads-h15_1712676357.log![]()
mariadbd_full_bt_all_threads-h14_1712676357.log![]()
Thanks, we will proceed with the upgrade .
| Status | Needs Feedback [ 10501 ] | Open [ 1 ] |
| Status | Open [ 1 ] | In Progress [ 3 ] |
| Fix Version/s | 10.6.15 [ 29013 ] | |
| Fix Version/s | 10.6 [ 24028 ] | |
| Resolution | Fixed [ 1 ] | |
| Status | In Progress [ 3 ] | Closed [ 6 ] |
| Link |
This issue is caused by |
| Fix Version/s | 11.3.2 [ 29522 ] | |
| Fix Version/s | 11.2.3 [ 29521 ] | |
| Fix Version/s | 11.1.4 [ 29024 ] | |
| Fix Version/s | 10.11.7 [ 29519 ] | |
| Fix Version/s | 10.10.7 [ 29018 ] | |
| Fix Version/s | 10.9.8 [ 29015 ] |
@jan , can you tell me based on a stack trace how we can identify the issue?
khaiping.loh If you find a thread doing sql_kill function it was MDEV-29293.
@jan, thanks!
How about seeing this in the processlist ? It seems to have cause the hung too. In this example, unfortunately i do not have the stacktrace.
ID,QUERY_ID,USER,DB,TIME,STATE,MEMORY_USED,MAX_MEMORY_USED,EXAMINED_ROWS,TID,INFO
276168,3416992,flask_user,None,4517,acquiring total order isolation,75568,75568,0,2831340,KILL CONNECTION ?
276167,3416991,flask_user,None,4517,acquiring total order isolation,74712,74712,0,2831239,KILL CONNECTION ?
276152,3416920,flask_user,None,4545,acquiring total order isolation,74712,74712,0,2831209,KILL CONNECTION ?
276141,3416909,flask_user,None,4566,acquiring total order isolation,74712,74712,0,2831188,KILL CONNECTION ?
When that happen, we noticed alot of commit transaction were stuck
277541,3422826,app_user,database_1,601,starting,83152,1033792,0,313531,COMMIT
277149,3421496,app_user,database_1,1501,starting,82080,1032720,0,2835445,COMMIT
276707,3420193,app_user,database_1,2401,starting,82080,1032720,0,2834972,COMMIT
276639,3420300,app_user,replication,2323,starting,82080,1032720,0,2834556,COMMIT
Seems to be related to MDEV-29293 as well.
khaiping.loh Yes, it is indication of MDEV-29293 fixed on more recent version of MariaDB server.
Can you: