By "forever" in the summary I mean that I have never seen it finish, the longest I waited before interrupting was ~1 hour.
The test uses all default server startup options, loads original data set from MDEV-28073 (xpo_full_testcase.sql), runs ANALYZE PERSISTENT FOR ALL on all tables, and executes EXPLAIN for a query structured identically to MDEV-28073 (minus a couple of last JOINs), but the tables and fields in the query are mixed up - that is, different tables and fields from the dataset appear in different JOIN positions and conditions. The exact query will be provided.
A slight abnormality of this particular query is that one of ON conditions compares a datetime field to a string literal (not convertible into a proper date time), and thus produces Truncated incorrect datetime value warning (ER_TRUNCATED_WRONG_VALUE). I'm not sure whether it's a decisive factor for the problem, but it's possible. Except for this condition, the query is identical to MDEV-28928.
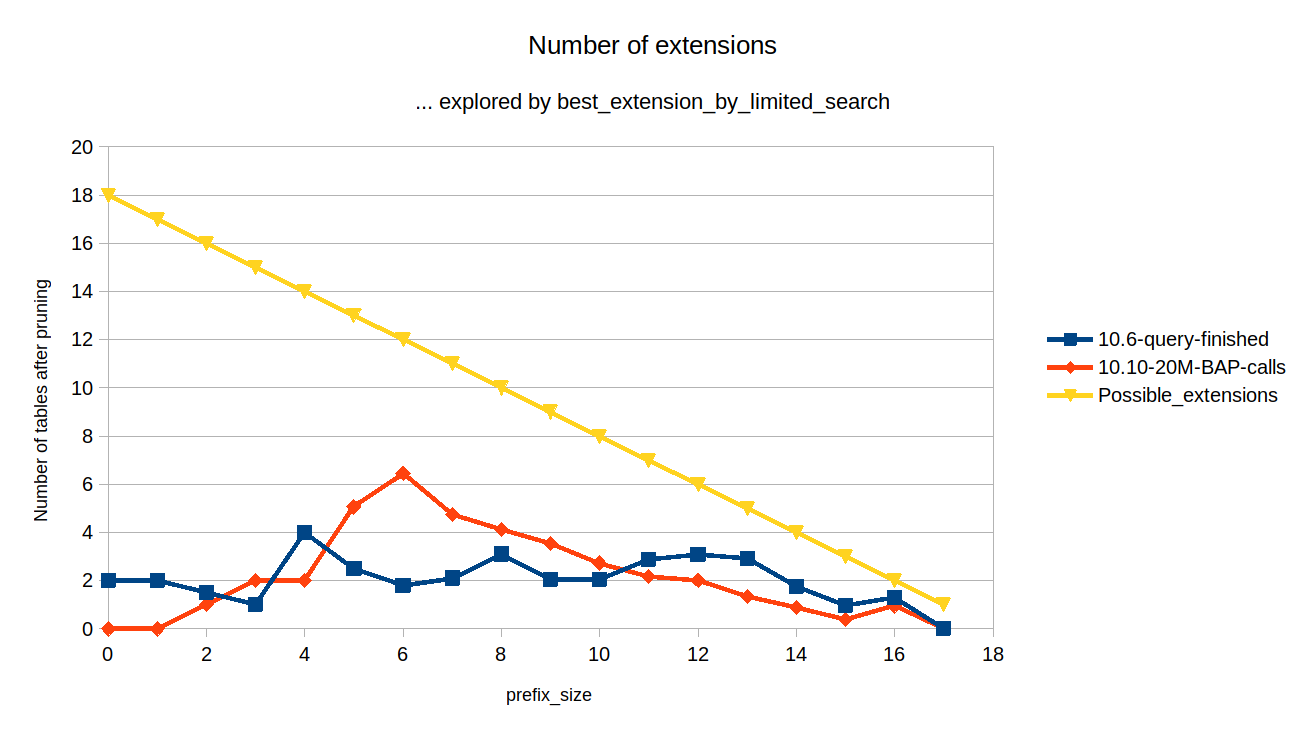
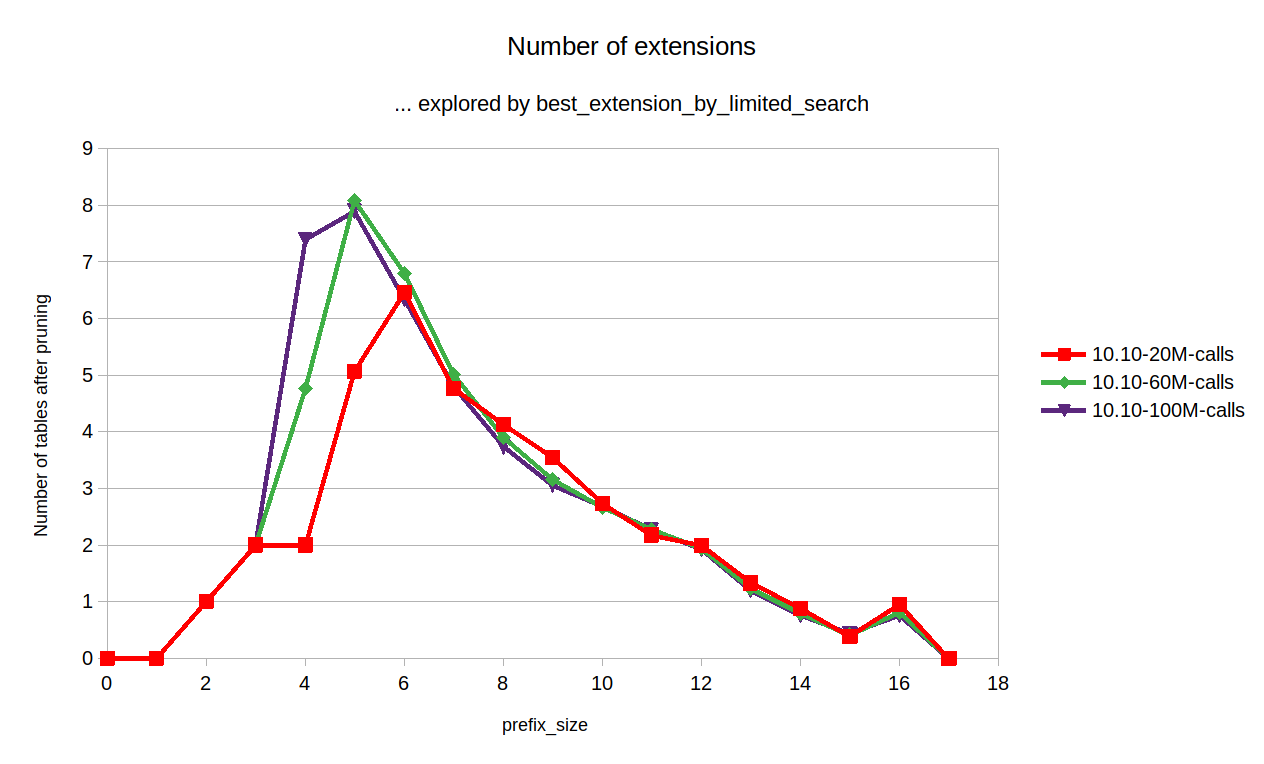
The query was executed with EXPLAIN FORMAT=JSON on several different versions/builds for comparison. All builds are non-debug.
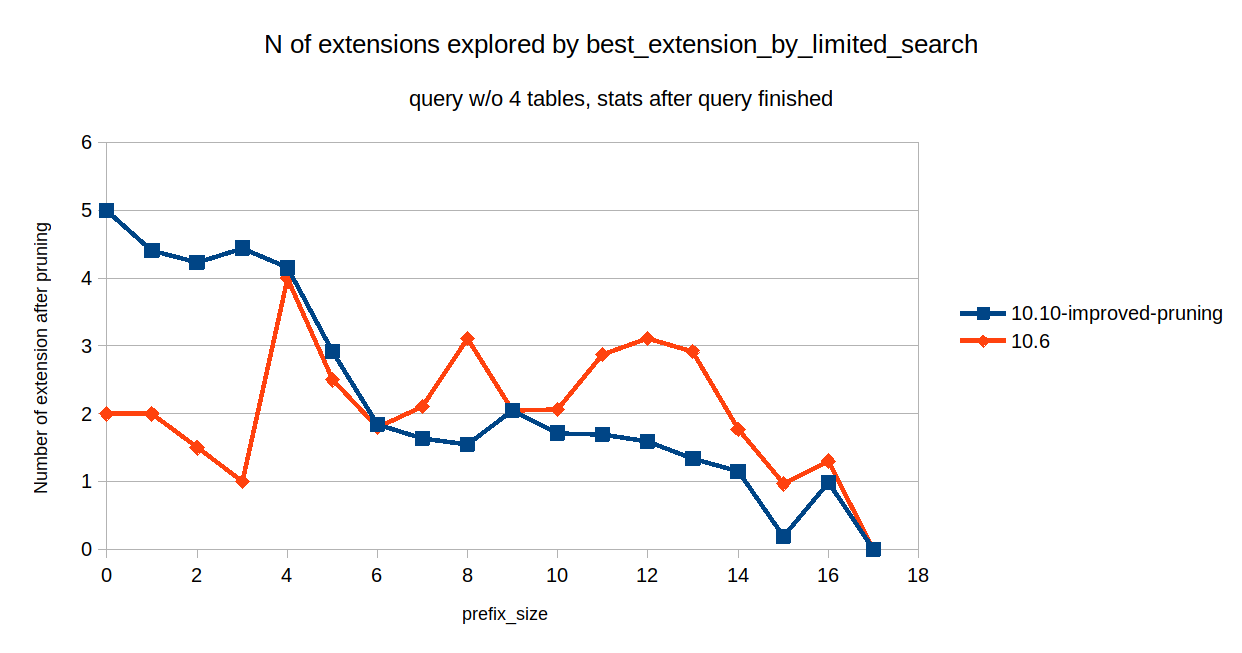
the query without tbl19, tbl21, tbl13, tbl15 - finishes faster than in 10.6
the query without tbl19, tbl21 - finishes in 0.68 sec
the original query finishes in 3.341 sec.
(This is on a debug build)
Sergei Petrunia
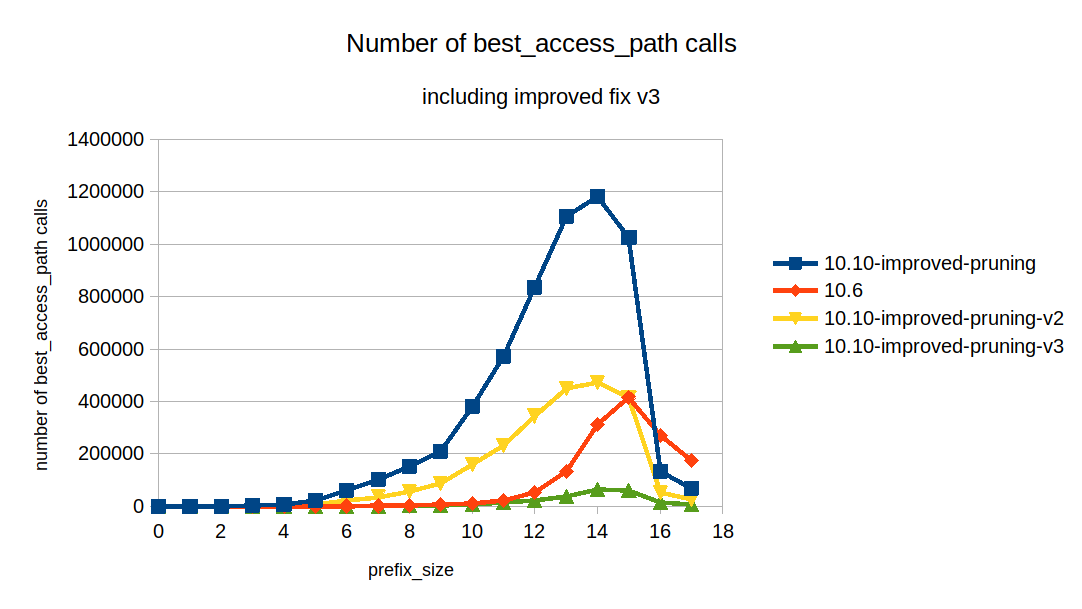
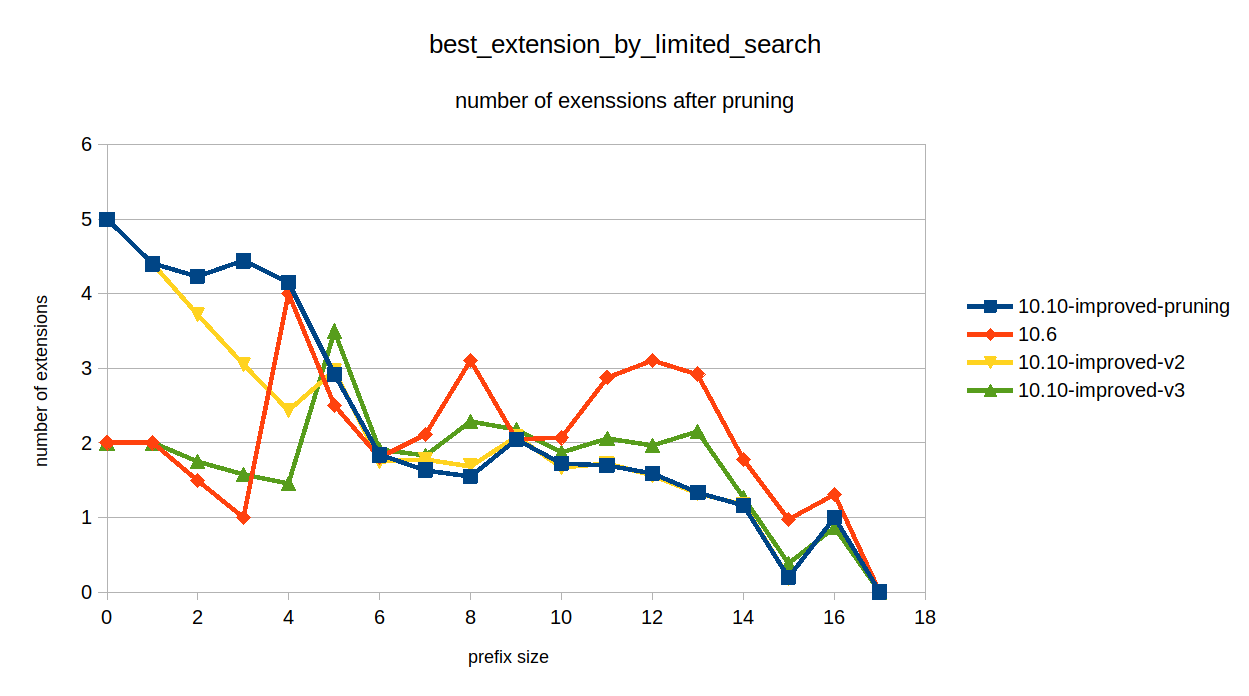
added a comment - The V3 patch helps with all EXPLAINs:
the query without tbl19, tbl21, tbl13, tbl15 - finishes faster than in 10.6
the query without tbl19, tbl21 - finishes in 0.68 sec
the original query finishes in 3.341 sec.
(This is on a debug build)
Let's think of possible query plans considered in best_extension_by_limited_search. The query plans have common join prefix. After adding a table, we get:
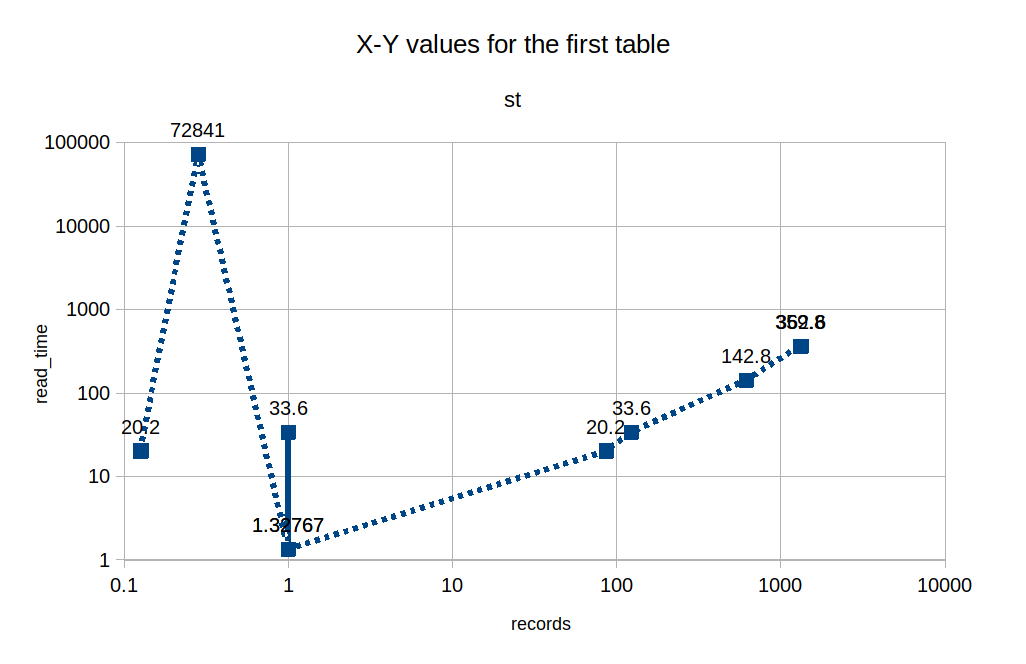
1. read_time. This includes the time spent reading the added table.
2. record_count. The number of row combination we will pass to further parts of the query plan.
3. The cost of the rest of the query plan. We dont know this but it's a function of the choice we've made right now.
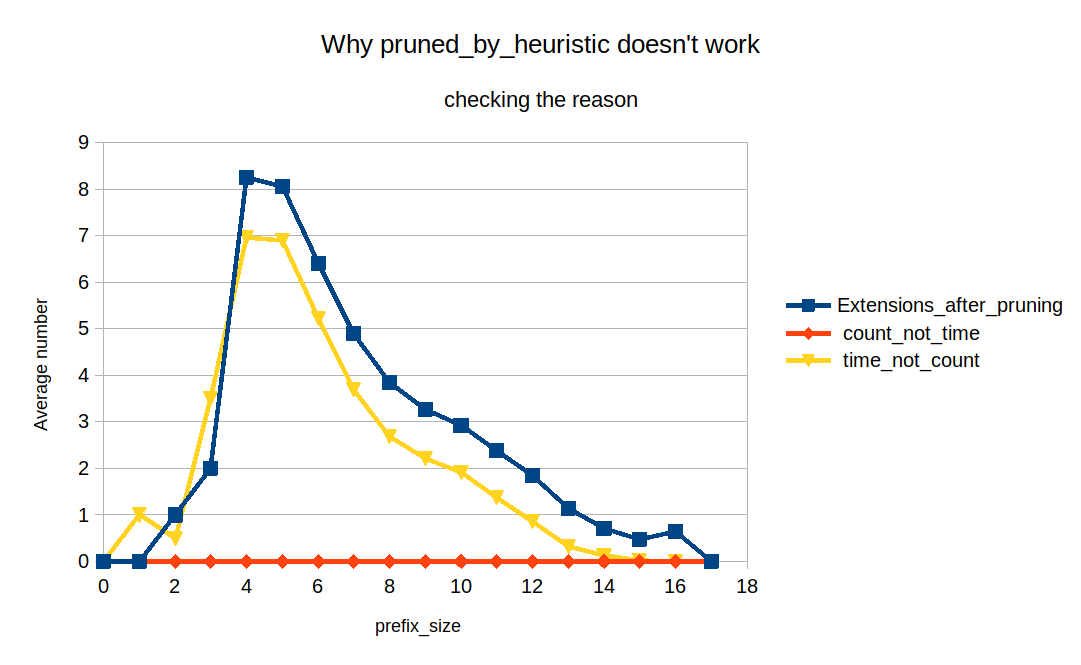
Doing the pruning.
Let's not think about #3, and just focus on #1 and #2. This is "the heuristic".
We don't know the "exchange ratio" between read_time and record_count. But we can tell that if both are bigger, then the query plan is less promising.
This is how pruning works. We discard the plans that have both higher read_time and higher record_count as they are less promising.
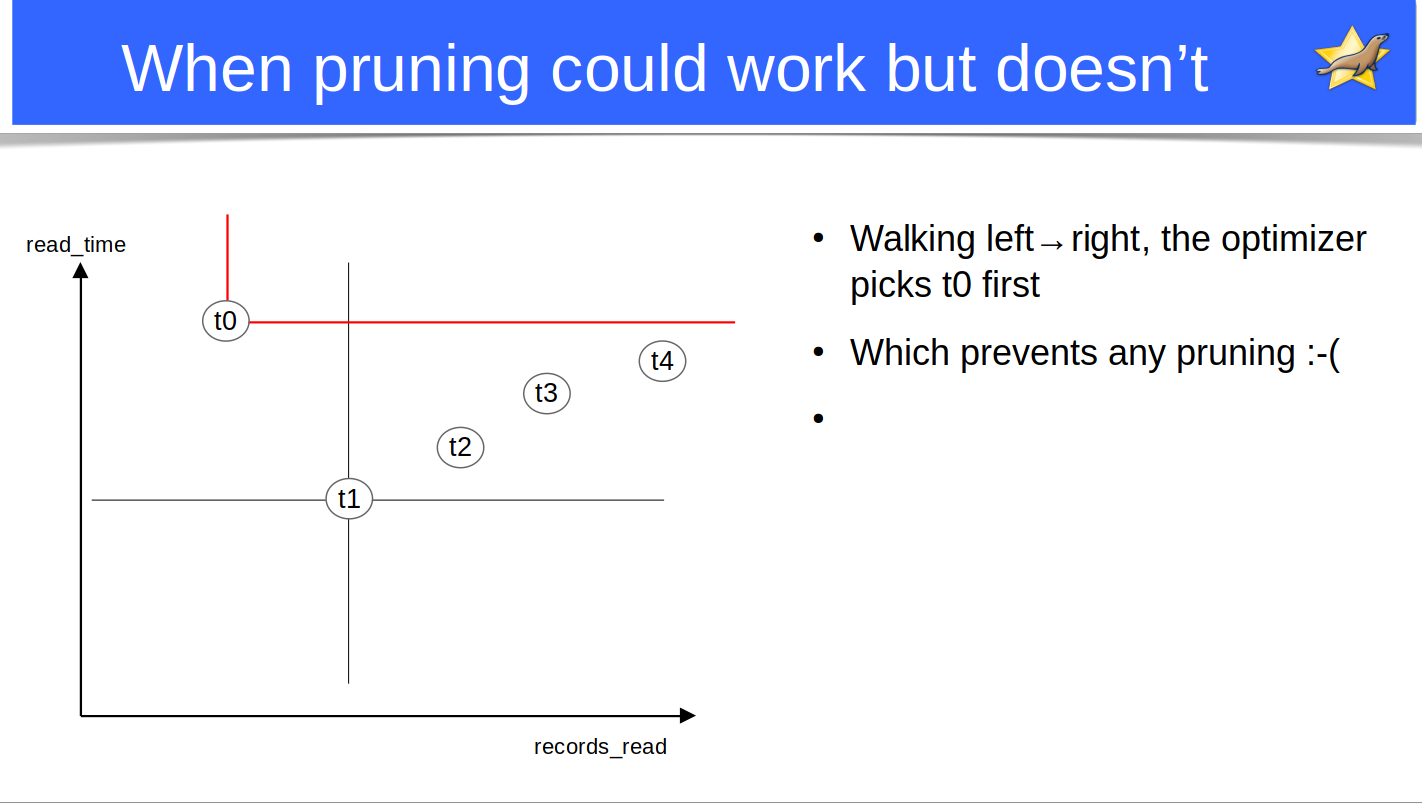
Limitations of pruning
The optimizer considers tables ordered by their record_count.
But it uses A DIFFERENT pruning criteria:
PLAN_X.record_count >= PLAN_Y.record_count AND PLAN_X.read_time >= PLAN_Y.read_time
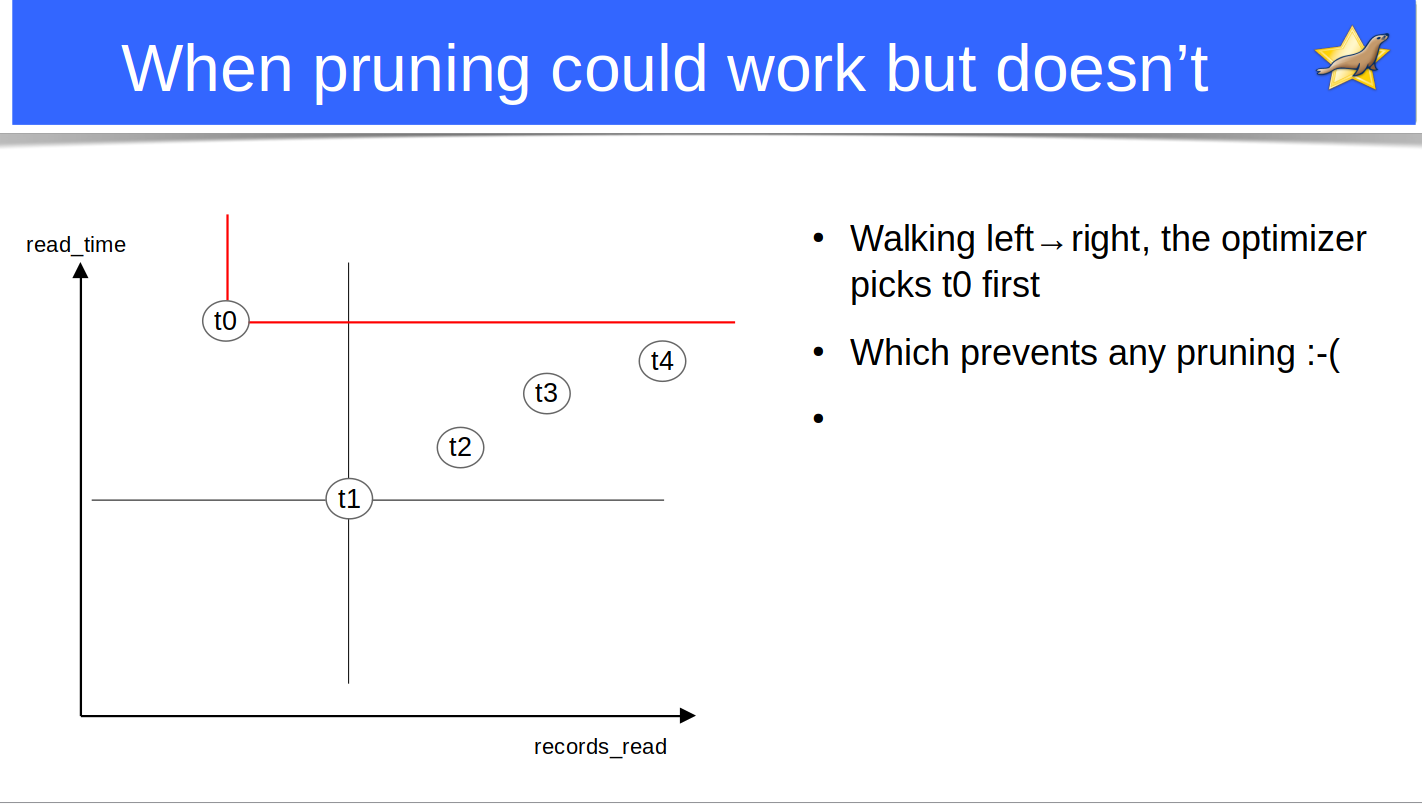
Which means the "best" tables to do pruning are not necessarily the first. We can get cases like this:
where the the table with least record_count is picked as "best" and is unable to do any pruning.
Ideally, we should have ordered the tables by their capacity to prune away other tables. This seems hard to do (I can only think of N^2 algorithms).
A workaround algorithm:
walk the tables from smaller to bigger record_count.
also keep another kind of "best" table, the one with the smallest read_time.
Sergei Petrunia
added a comment - - edited The idea behind pruned_by_heuristic
Let's think of possible query plans considered in best_extension_by_limited_search. The query plans have common join prefix. After adding a table, we get:
1. read_time. This includes the time spent reading the added table.
2. record_count. The number of row combination we will pass to further parts of the query plan.
3. The cost of the rest of the query plan. We dont know this but it's a function of the choice we've made right now.
Doing the pruning.
Let's not think about #3, and just focus on #1 and #2. This is "the heuristic".
We don't know the "exchange ratio" between read_time and record_count. But we can tell that if both are bigger, then the query plan is less promising.
This is how pruning works. We discard the plans that have both higher read_time and higher record_count as they are less promising.
Limitations of pruning
The optimizer considers tables ordered by their record_count.
But it uses A DIFFERENT pruning criteria:
PLAN_X.record_count >= PLAN_Y.record_count AND PLAN_X.read_time >= PLAN_Y.read_time
Which means the "best" tables to do pruning are not necessarily the first. We can get cases like this:
where the the table with least record_count is picked as "best" and is unable to do any pruning.
Ideally, we should have ordered the tables by their capacity to prune away other tables. This seems hard to do (I can only think of N^2 algorithms).
A workaround algorithm:
walk the tables from smaller to bigger record_count.
also keep another kind of "best" table, the one with the smallest read_time.
use both to do pruning.
This is what V3 patch in the psergey-mdev28929-improved-pruning-v3.diff does.
Sergei Petrunia
added a comment - - edited The final version of the patch:
https://github.com/MariaDB/server/commit/ac3b3807cc9b21e23e65b1a70c7dcda1f45a3c57
in bb-10.10-mdev28929-v4
Bug
 Critical
Critical
MDEV-28852 Improve optimization of joins with many tables, including eq_ref tables

 does.
does.
The V3 patch: psergey-mdev28929-improved-pruning-v3.diff