Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
10.8(EOL)
Description
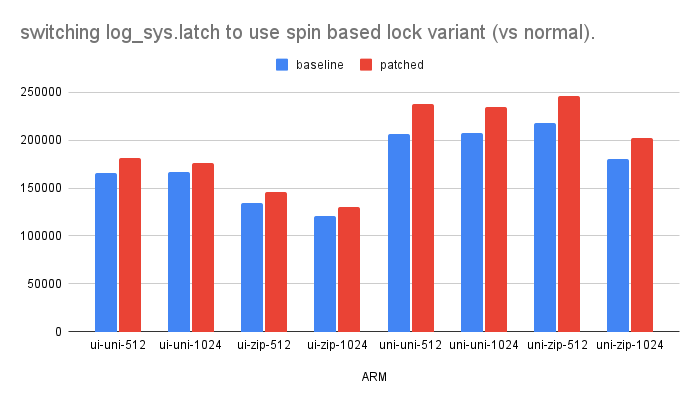
- log_sys.mutex was replaced with log_sys.latch as part of redo log revamp efforts.
- during the experiment it was observed that log_sys.latch spin-based variant
continue to perform better on ARM in the range of 8-15%.
(x86 didn't show any major performance difference).
Attachments
Issue Links
- relates to
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
Activity
Marko/Vlad,
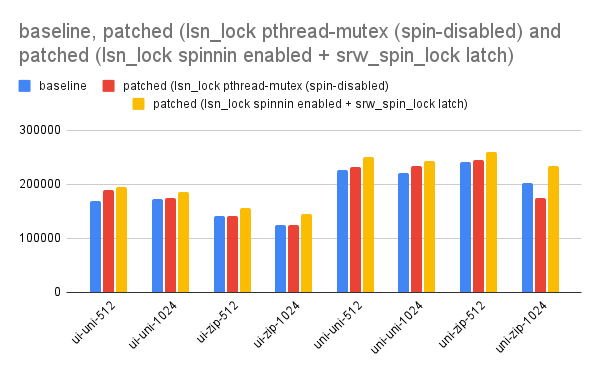
1. I tested the pthread_mutex_t approach from Vlad (with spin-disabled MY_MUTEX_INIT_FAST = 0). This helped improve the performance in some case (w.r.t baseline).
2. I then added the original srw_spin_lock patch. This got me mixed results.
3. Finally, I got a combination that helped me scale best with a significant difference with baseline. (srw_spin_lock for latch + pthread_mutex_t with spinning enabled). This got me best result on ARM.
check the graph attached.
Update 2: If, in the above patch, I replace MY_MUTEX_INIT_FAST with 0, so default mutex, the performance on both single numa node, and 2 numa nodes is better again, that srw_mutex.
| NUMA nodes | srw_mutex | pthread_mutex(MY_MUTEX_INIT_FAST) | pthread_mutex default |
|---|---|---|---|
| 1 | 141851.87 | 152514.50 | 143170.42 |
| 2 | 83495.47 | 65638.71 | 90748.48 |
Based on that, pthread_mutex_t is a winner on this particular box. It is much better on single NUMA node, and slightly better on 2 numa nodes than srw_mutex, and does not have 2 NUMA node regression which MY_MUTEX_INIT_FAST has.
Windows:
| srw_spin_mutex | SRWLOCK | pthread_mutex_t | srw_mutex | CRITICAL_SECTION with spin count 10 |
|---|---|---|---|---|
| 223972.20 | 217495.12 | 222930.06 | 217841.48 | 227981.50 |
All currently perform about the same, although srw_spin_mutex and pthread_mutex_t are slightly better than the others. The absolute winner CRITICAL_SECTION with spin count 10 is pthread_mutex_t == CRITICAL_SECTION, with added SetCriticalSectionSpinCount call
Overall plain (non-adaptive) pthread_mutex_t seems to be quite good in all tests I performed, as candidate for "spinlock" log_sys.lsn_lock.
I attached the patch where lsn_lock is just pthread_mutex (with non-portable adaptive attribute) lsn_lock_is_pthread_mutex.diff![]() , applied to commit bbe99cd4e2d7c83a06dd93ea88af97f2d5796810 (current 10.9)
, applied to commit bbe99cd4e2d7c83a06dd93ea88af97f2d5796810 (current 10.9)
that performs better for me 141851.87 tps without the patch, vs 152514.50 with the patch
in a 30 seconds update_index standoff , and this is on Intel. Perhaps ARM can also benefit from it.
I used 1000 clients , 8 tables x 1500000 rows, large redo log and buffer pool, --innodb-flush-log-at-trx-commit=2 --thread-handling=pool-of-threads #
And it performs good on Windows, too
Update : However, if I run this on Linux on 2 NUMA nodes, results are not so good, it is 83495.47 without the patch vs 65638.71 with the patch. If you notice the single NUMA node numbers, yes that's how the NUMA performs on that box I have, I give it 2x the CPUs, and it makes the server half as fast (therefore I almost never do any NUMA test). That's an old 3.10 kernel, so maybe things are better for someone else.
I think we might have more urgent problems, than that spinlock (for example, getting rid of lock-free transaction hash, the CPU for lf_finds is alarming). If it turns out to be hot, which it seems to be, I'm always for OS mutex, the pthread_mutex, or even for std::mutex, which for me turns out of to be native SRWLOCK. while does not seem to protect large section of code, I'm not sure how often it is entered, so it seems to be oft, and thus maybe we can stay with whatever is just normal mutex (if ARM likes spinning, there is this ADAPTIVE thing it may like). The mysql_mutex_t might give an idea of how hot it is, since it is perfschema-instrumented, on the other hand it might make it even hotter, exactly because of the perfschema overhead.
wlad, thank you for experimenting and benchmarking.
I checked your lsn_lock_is_pthread_mutex.diff , and I am glad to see that it will not only avoid any PERFORMANCE_SCHEMA overhead, but that sizeof(log_sys.lsn_lock) is only 40 on my system. I thought that the size was 44 bytes on IA-32 and 48 bytes on AMD64, but it looks like I got it off by 8.
, and I am glad to see that it will not only avoid any PERFORMANCE_SCHEMA overhead, but that sizeof(log_sys.lsn_lock) is only 40 on my system. I thought that the size was 44 bytes on IA-32 and 48 bytes on AMD64, but it looks like I got it off by 8.
My main concern regarding the mutex size is that the data fields that follow the mutex should best be allocated in the same cache line (typically, 64 bytes on IA-32 or AMD64). That is definitely the case here.
Please commit that change, as well as krunalbauskar’s pull request to enable log_sys.latch spinning on ARMv8.