Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
10.6.0
Description
In the futex-based implementation of InnoDB synchronization primitives srw_mutex::wait_and_lock() we are unnecessarily using a compare-and-swap loop for setting the HOLDER flag. We could use a fetch_add (to register the current thread as a waiter) followed by a fetch_or to set the flag. The value of a granted lock word with no waiting threads would change from HOLDER to HOLDER + 1.
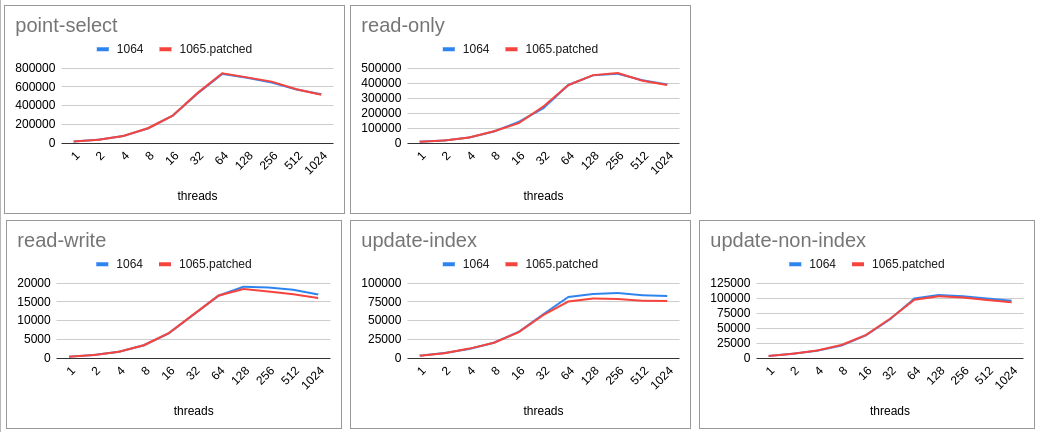
Replacing the compare-and-swap loop seems to slightly improve performance in Sysbench oltp_update_index on my AMD64 based system, using a single NUMA node:
| threads | unpatched transactions/s | patched transactions/s |
|---|---|---|
| 10 | 91110 | 92171 |
| 20 | 158399 | 158623 |
| 30 | 162566 | 163092 |
We still use a compare-and-swap loop in ssux_lock_low::rd_lock_try() ever since MDEV-24271. It used to be a greedy fetch_add() followed by a fetch_sub() back-off, but we observed starvation due to that.
Attachments
Issue Links
- relates to
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
MDEV-32065 Always check whether lock is free at first to optimize InnoDB mutexes
-
- Open
-
