Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Duplicate
-
10.2(EOL), 10.5(EOL), 10.6, 10.11, 11.4, 11.8
Description
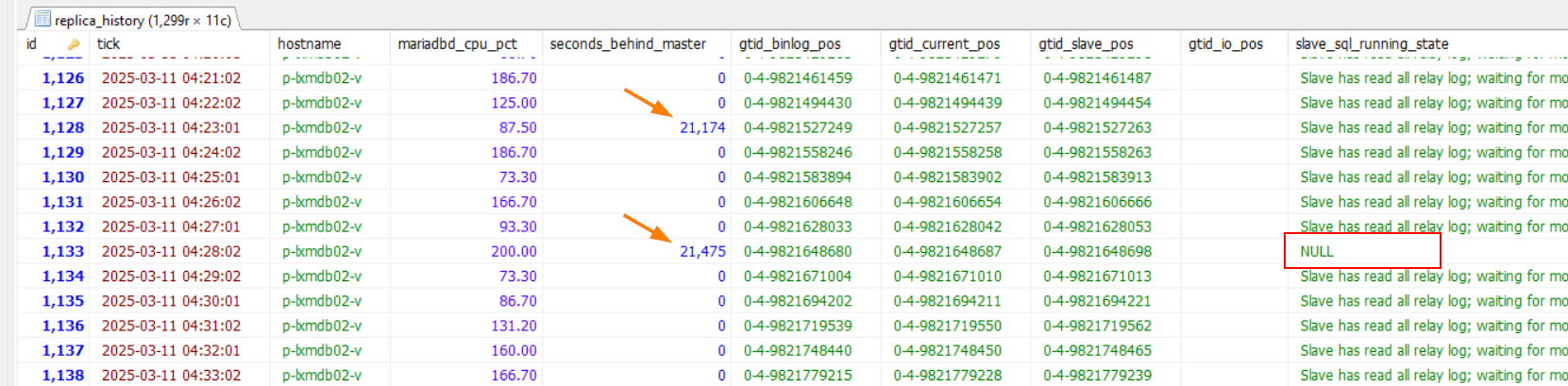
Seconds_Behind_Master can quickly and sporadically spike from 0 to really high values, and then go back to 0 (independent of running on a parallel or serial replica). This is due to the Seconds_Behind_Master computation having a special idleness check which overrides the value to 0. This idleness condition (and thereby when SBM is calculated/written) is based on the SQL thread queueing status:
idle= mi->rli.sql_thread_caught_up;
|
Which isn't tightly coupled with user events. That is, the timestamp of internal events (e.g. Format_description_log_event, Gtid_list_log_event, and Binlog_checkpoint_event) aren't saved on the replica, and thereby the Seconds_Behind_Master value won't reflect a more recent replica when these events are processed. However, when these events are queued by the SQL thread, the idleness condition no longer holds, and then Seconds_Behind_Master will be calculated and displayed based on the last timestamp from a user transaction, which can be very large (particularly when a replica is configured with SQL_Delay. This is particularly prevalent during log rotation, as all events generated during this time are internal, and should not be considered in Seconds_Behind_Master.
The fix should update the idleness condition to not be based on the queueing state of the SQL thread, but rather that there are no new user events from the master to process (e.g. GTID_IO_Pos == GTID_Slave_Pos).
Test case to reproduce (which requires a small patch for debug_sync integration):
#
|
# TODO: Write me
|
#
|
# References:
|
# MDEV-:
|
#
|
|
|
--source include/have_innodb.inc
|
--source include/have_log_bin.inc
|
# Format independent
|
--source include/have_binlog_format_row.inc
|
--source include/master-slave.inc
|
|
|
--connection slave
|
--source include/stop_slave.inc
|
set @@global.debug_dbug="+d,pause_sql_thread_on_next_fde";
|
--source include/start_slave.inc
|
|
|
--echo #
|
--echo # Initialize test data
|
--connection master
|
|
|
create table t1 (a int primary key) engine=innodb;
|
insert into t1 values (1);
|
--source include/save_master_gtid.inc
|
|
|
--echo # Catch slave up with master
|
--connection slave
|
--echo # Debug_sync is set on format description events, so skip 2 (1 for master binlog, 1 for slave relay log)
|
set debug_sync="now wait_for paused_on_fde";
|
set debug_sync="now signal sql_thread_continue";
|
set debug_sync="now wait_for paused_on_fde";
|
set debug_sync="now signal sql_thread_continue";
|
--source include/sync_with_master_gtid.inc
|
|
|
--echo # Rotate master binary logs to force sql thread to read internal only events
|
--connection master
|
FLUSH LOGS;
|
|
|
|
|
--connection slave
|
|
|
--echo #
|
--echo # Skip through format description events from relay log file & master
|
--echo # binlog until we get to the last one
|
--echo #
|
set debug_sync="now wait_for paused_on_fde";
|
set debug_sync="now signal sql_thread_continue";
|
set debug_sync="now wait_for paused_on_fde";
|
set debug_sync="now signal sql_thread_continue";
|
|
|
--echo # Now pause on the last format description event
|
set debug_sync="now wait_for paused_on_fde";
|
|
|
|
|
--echo # Wait 2s so SBM has a chance to increase..
|
--sleep 2
|
--echo # Seconds_Behind_Master should be zero as user events are up-to-date (but is not)
|
--let $status_items= Seconds_Behind_Master
|
--source include/show_slave_status.inc
|
|
|
--echo # Resume SQL thread
|
set debug_sync="now signal sql_thread_continue";
|
--echo # TODO clean up debug_dbug and debug_sync status
|
|
|
--echo #
|
--echo # Cleanup
|
--connection master
|
drop table t1;
|
--source include/save_master_gtid.inc
|
|
|
--connection slave
|
--source include/sync_with_master_gtid.inc
|
|
|
--source include/rpl_end.inc
|
--echo # End of .test
|
--echo # TODO ^ Fill out with test name
|
patch for debug_sync (on 10.6 community):
diff --git a/sql/log_event_server.cc b/sql/log_event_server.cc
|
index 8b740195b24..9fa14a6b873 100644
|
--- a/sql/log_event_server.cc
|
+++ b/sql/log_event_server.cc
|
@@ -2426,6 +2426,12 @@ int Format_description_log_event::do_apply_event(rpl_group_info *rgi)
|
Relay_log_info *rli= rgi->rli;
|
DBUG_ENTER("Format_description_log_event::do_apply_event");
|
|
+ DBUG_EXECUTE_IF("pause_sql_thread_on_next_fde", {
|
+ DBUG_ASSERT(!debug_sync_set_action(
|
+ thd, STRING_WITH_LEN(
|
+ "now SIGNAL paused_on_fde WAIT_FOR sql_thread_continue")));
|
+ });
|
+
|
/*
|
As a transaction NEVER spans on 2 or more binlogs:
|
if we have an active transaction at this point, the master died
|
|
Attachments
Issue Links
- duplicates
-
-
- Closed
-
- relates to
-
-
- Closed
-