Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
10.5.4
-
None
Description
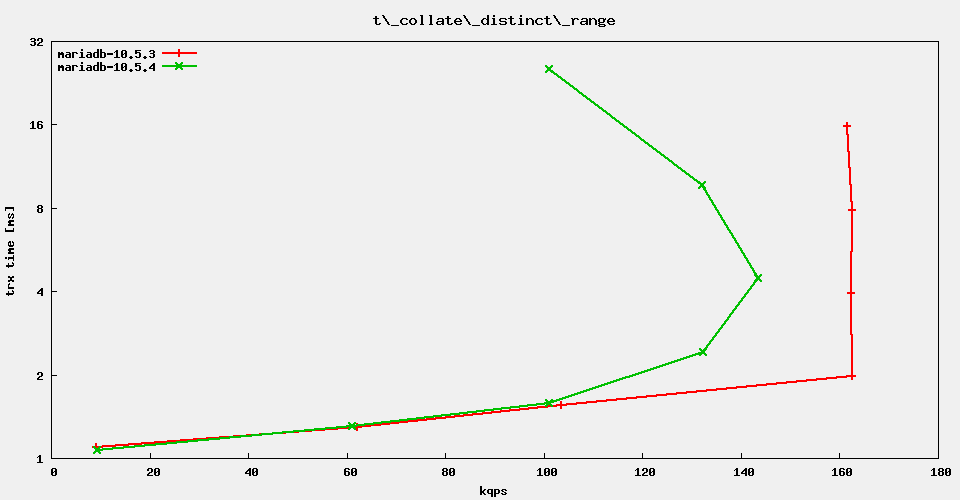
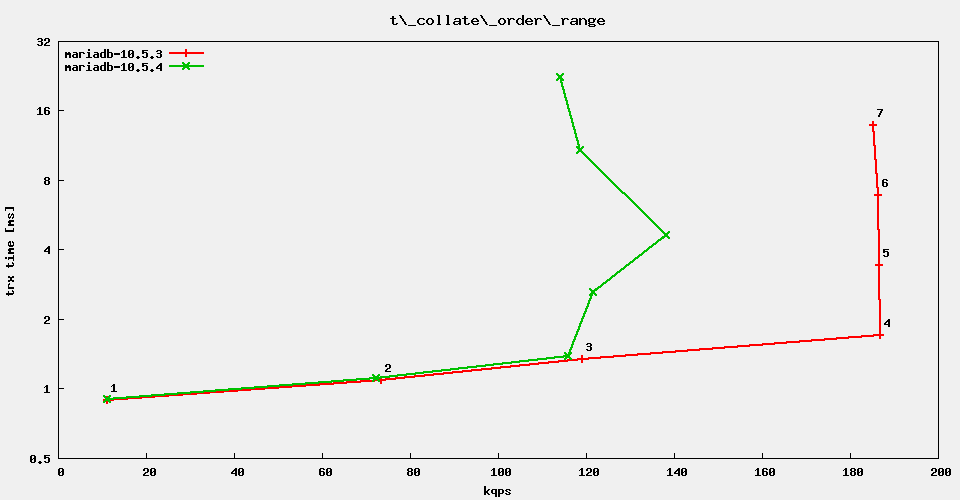
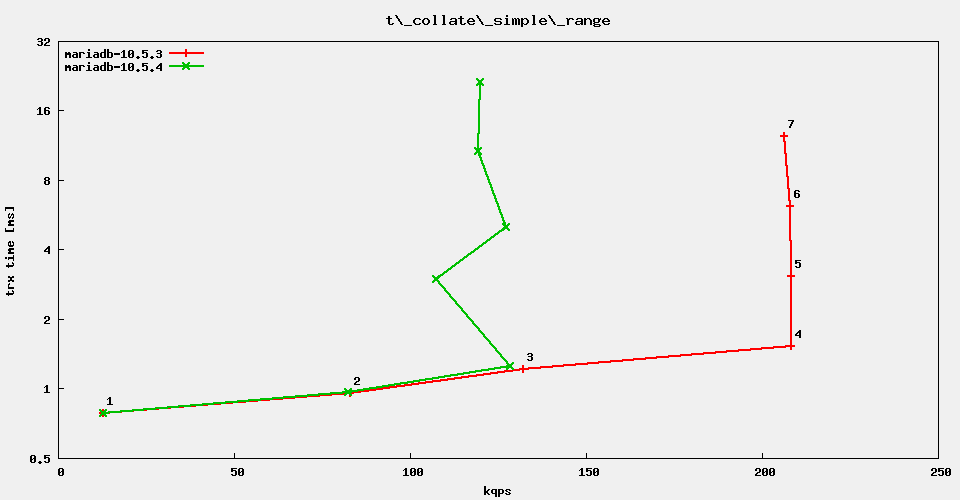
The regression test suite reports rather severe performance regressions in MariaDB 10.5.4 vs. 10.5.3. It looks like it is genuinely for the sysbench OLTP range queries. Example:
Test 't_collate_distinct_range_utf8_general' - sysbench OLTP readonly
|
selecting distinct rows from short range, collation utf8_general_ci
|
1 table, 1 mio rows, engine InnoDB/XtraDB (builtin)
|
numbers are queries per second
|
|
|
#thread count 1 8 16 32 64 128 256
|
mariadb-10.5.3 7840.1 53249 92616 149360 149130 149435 148546
|
mariadb-10.5.4 7794.3 52208 91235 131122 137925 128168 94999
|
Attachments


Issue Links
- is caused by
-
MDEV-15053 Reduce buf_pool_t::mutex contention
-

- Closed
-
- relates to
-
-
- Closed
-
-
-
- Closed
-
