Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
10.2(EOL)
-
None
Description
Branching this off from MDEV-15173 (see that MDEV for all the details)
Parallel slave (slave_parallel_mode=conservative does not provide a lot of speedup over single-threaded slave when log_slave_updates=OFF.
When log_slave_updates=ON the performance is acceptable.
Summary of the investigations from MDEV-15173:
The reason is that with log_slave_updates=ON the server employs XA between the storage engine the binlog:
- Prepare calls sync their effects to disk
- They are are done in parallel, so they can take advantage of the group commit.
- Commit calls are done one-after-another in order to commit in the master's binlog order
- but they dont sync to disk and so are fast.
With log_slave_updates=OFF :
- XA is not used (as MyRocks is the only participant)
- commit() calls are done one-after-another in the binlog order
- The storage engine is instructed to sync.
- The above two together mean that MyRocks' group commit does not function.
Attachments
Issue Links
- relates to
-
MDEV-15173 MyRocks: basic performance checks
-
- Closed
-
-
-
- Open
-
Activity
A similar patch for MyRocks:
diff --git a/storage/rocksdb/ha_rocksdb.cc b/storage/rocksdb/ha_rocksdb.cc b/storage/rocksdb/ha_rocksdb.cc
|
index 4a0a3ed..5b8bda0 100644
|
--- a/storage/rocksdb/ha_rocksdb.cc
|
+++ b/storage/rocksdb/ha_rocksdb.cc
|
@@ -3154,10 +3154,20 @@ static int rocksdb_commit(handlerton* hton, THD* thd, bool commit_tx)
|
- For a COMMIT statement that finishes a multi-statement transaction
|
- For a statement that has its own transaction
|
*/
|
+
|
+ // First, commit without syncing. This establishes the commit order
|
+ tx->set_sync(false);
|
if (tx->commit()) {
|
DBUG_RETURN(HA_ERR_ROCKSDB_COMMIT_FAILED);
|
}
|
thd_wakeup_subsequent_commits(thd, 0);
|
+
|
+ if (rocksdb_flush_log_at_trx_commit == FLUSH_LOG_SYNC)
|
+ {
|
+ rocksdb::Status s= rdb->FlushWAL(true);
|
+ if (!s.ok())
|
+ DBUG_RETURN(HA_ERR_INTERNAL_ERROR);
|
+ }
|
} else {
|
/*
|
We get here when committing a statement within a transaction. |
An alternative suggestion is to have the slave to not flush. Master's binlog is always available, so if we crash and lose some transaction, we will know that from mysql.gtid_slave_pos table, and will replay.
This seems risky and might not work in all cases, e.g. we will need to flush when semi-sync plugin is used?
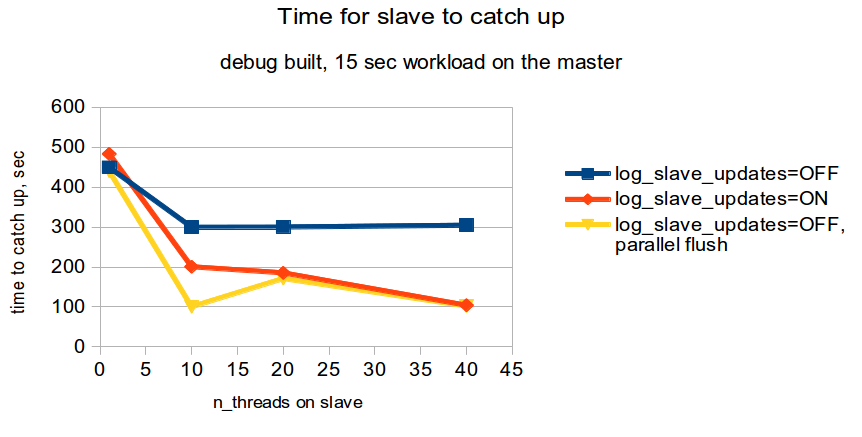
Let's denote the above patch as "parallel flush". I've re-used the benchmark script from MDEV-15173 and ran experiments with a smaller test: 
- The master is a release build on t2.2xlarge, master workload is produced by running for 15 seconds
- The slave is a debug build on t2.xlarge.
== current, log_slave_updates=OFF
|
1 449.36014
|
10 299.69696
|
20 300.150217
|
40 304.607912
|
== parallel flushing patch, log_slave_updates=OFF
|
1 440.069868
|
10 100.363523
|
20 171.010232
|
40 102.043958
|
== current, log_slave_updates=ON:
|
1 483.109567
|
10 200.629623
|
20 185.305239
|
40 104.271133
|
The fix for this issue causes poor performance for non-slave, see MDEV-18080.
With InnoDB, the issue doesn't exist. This seems to be because innobase_commit() has two parts:
The first one is run sequentially:
innobase_commit_ordered_2(trx, thd);}then it informs the SQL layer that the rest can be done in parallel:
thd_wakeup_subsequent_commits(thd, 0);and the slower part is done in parallel:
trx_commit_complete_for_mysql(trx);trx_deregister_from_2pc(trx);