Details
-
New Feature
-
Status: Closed (View Workflow)
-
 Blocker
Blocker
-
Resolution: Fixed
-
None
-
None
-
2021-7, 2021-8, 2021-9
Description
Optimizer statistics
Most engines feeds their query optimizers with different types of statistics, e.g histograms of most common values, fractions of NULL values, Number of Distinct Values, relation cardinality. The statistics allows to make educated guesses regarding cardinality of intermediate and final result of a query, e.g. optimizer finds the optimal join order using this statistics. MCS now has a rudimentary statistics that consist of a relation cardinality only.
The goal
We need to design and build facilities that allows MCS to make educated guesses about cardinality of intermediate and final result of a query and use this knowledge to produce an optimal plan.
What is statistics
The simplest version of statistics must have the list of attributes listed earlier. The improved version should have an extensible format to add attributes(e.g. correlated or dependant histograms on functionaly dependant columns) w/o lots of changes.
What triggers stats collection
There must be a user knob in the form of ANALYZE SQL statement. Bulk insert operation inserting more then N values must also trigger ANALYZE to regresh the stats.
Consumers
ExeMgr or whatever the optimizer goes into is the most important consumer. The fact that there might be more then one EM in the cluster must be taken into account.
Where to put stats and how to save it b/w restarts
EMs in the cluster must have direct access to the stats so stats in-memory representation must reside in the RAM of the primary EM. Other EMs must have a synchronized version of the stats.
Producers
EM must initiate statistics collection. The statistics collection process must not differ much from SELECT * FROM query. The sampling method isn't yet choosen.
Please see the design doc for more details.
Attachments
Issue Links
- blocks
-
MCOL-1205 support queries with circular INNER joins
-
- Closed
-
-
-
- Closed
-
- includes
-
-

- Closed
-
- relates to
-
MCOL-5191 Join Optimizer: histogram statistics/ needed for cost-based optimization
-

- Closed
-
Activity
| Affects Version/s | All [ 25803 ] |
| Description |
From the beginning of time ColumnStore does not keep any meta information required for logical optimization of queries. This task intends to resolve it, and enable a large set of very high impact optimization projects. Primary examples:
1. Even though CS data is always taken from OLTP systems which have primary keys and unique indexes, this information is not recorded. As a result, it is not possible to estimate the impact of any pushed predicate on row size of the a filtering job step - instrumental in deciding on a best join order, or perform a proper join elimination in case of circular joins, among others. 2. Nor is there any column cardinality estimation mechanism (a viable, and likely a more generally applicable alternative to additional table metadata). 3. There is no distribution information either. There are multiple possibilities. 1. A more difficult yet more impactful would be to collect column statistics - cardinalities and distributions, and use them at the planning time. 2. In shorter term, it should be easy enough to enable syntactical constructs PRIMARY KEY and UNIQUE INDEX. There is no need to build the additional data structures. But knowing that a given column is UNIUE would provide tremendous help in estimating the size of a rowset resulting from application of an equi predicate to a scalar (or of a "short" IN list of scalar values), hence in deciding on the proper join order. |
| Description |
From the beginning of time ColumnStore does not keep any meta information required for logical optimization of queries. This task intends to resolve it, and enable a large set of very high impact optimization projects. Primary examples:
1. Even though CS data is always taken from OLTP systems which have primary keys and unique indexes, this information is not recorded. As a result, it is not possible to estimate the impact of any pushed predicate on row size of the a filtering job step - instrumental in deciding on a best join order, or perform a proper join elimination in case of circular joins, among others. 2. Nor is there any column cardinality estimation mechanism (a viable, and likely a more generally applicable alternative to additional table metadata). 3. There is no distribution information either. There are multiple possibilities. 1. A more difficult yet more impactful would be to collect column statistics - cardinalities and distributions, and use them at the planning time. 2. In shorter term, it should be easy enough to enable syntactical constructs PRIMARY KEY and UNIQUE INDEX. There is no need to build the additional data structures. But knowing that a given column is UNIUE would provide tremendous help in estimating the size of a rowset resulting from application of an equi predicate to a scalar (or of a "short" IN list of scalar values), hence in deciding on the proper join order. |
From the beginning of time ColumnStore does not keep any meta information required for logical optimization of queries. This task intends to resolve it, and enable a large set of very high impact optimization projects. Primary examples:
1. Even though CS data is always taken from OLTP systems which have primary keys and unique indexes, this information is not recorded. As a result, it is not possible to estimate the impact of any pushed predicate on row size of the a filtering job step - instrumental in deciding on a best join order, or perform a proper join elimination in case of circular joins, among others. 2. Nor is there any column cardinality estimation mechanism (a viable, and likely a more generally applicable alternative to additional table metadata). 3. There is no distribution information either. There are multiple possibilities. 1. A more difficult yet more impactful would be to collect column statistics - cardinalities and distributions, and use them at the planning time. Knowing that a given column is predominantly UNIUE would provide tremendous help in estimating the size of a rowset resulting from application of an equi predicate to a scalar (or of a "short" IN list of scalar values), hence in deciding on the proper join order. Inversely, knowing that a column has low cardinality relative to the cardinality of the table would enable the detection of a cartesian explosion risks inherent in joins which use such columns on both sides (e.g. Query 5 of TPC-H) - so called join elimination. 2. In shorter term, it should be easy enough to enable syntactical constructs like PRIMARY KEY and UNIQUE INDEX. There is no need to build the additional data structures beyond traditional table metadata - these would be merely PROXY PRIMARY KEY, or a PROXY UNIQUE INDEX, helping the planner to make proper guesses about cardinalities of various job steps leading to proper estimation of their costs, and ending in a proper decision making as regards join ordering or join elimination. |
| Status | Open [ 1 ] | In Progress [ 3 ] |
| Sprint | 2021-7 [ 514 ] |
| Rank | Ranked higher |
| Description |
From the beginning of time ColumnStore does not keep any meta information required for logical optimization of queries. This task intends to resolve it, and enable a large set of very high impact optimization projects. Primary examples:
1. Even though CS data is always taken from OLTP systems which have primary keys and unique indexes, this information is not recorded. As a result, it is not possible to estimate the impact of any pushed predicate on row size of the a filtering job step - instrumental in deciding on a best join order, or perform a proper join elimination in case of circular joins, among others. 2. Nor is there any column cardinality estimation mechanism (a viable, and likely a more generally applicable alternative to additional table metadata). 3. There is no distribution information either. There are multiple possibilities. 1. A more difficult yet more impactful would be to collect column statistics - cardinalities and distributions, and use them at the planning time. Knowing that a given column is predominantly UNIUE would provide tremendous help in estimating the size of a rowset resulting from application of an equi predicate to a scalar (or of a "short" IN list of scalar values), hence in deciding on the proper join order. Inversely, knowing that a column has low cardinality relative to the cardinality of the table would enable the detection of a cartesian explosion risks inherent in joins which use such columns on both sides (e.g. Query 5 of TPC-H) - so called join elimination. 2. In shorter term, it should be easy enough to enable syntactical constructs like PRIMARY KEY and UNIQUE INDEX. There is no need to build the additional data structures beyond traditional table metadata - these would be merely PROXY PRIMARY KEY, or a PROXY UNIQUE INDEX, helping the planner to make proper guesses about cardinalities of various job steps leading to proper estimation of their costs, and ending in a proper decision making as regards join ordering or join elimination. |
Optimizer statistics
Most engines feeds their query optimizers with different types of statistics, e.g histograms of most common values, fractions of NULL values, Number of Distinct Values, relation cardinality. The statistics allows to make educated guesses regarding cardinality of intermediate and final result of a query, e.g. optimizer finds the optimal join order using this statistics. MCS now has a rudimentary statistics that consist of a relation cardinality only. The goal We need to design and build facilities that allows MCS to make educated guesses about cardinality of intermediate and final result of a query and use this knowledge to produce an optimal plan. What is statistics The simplest version of statistics must have the list of attributes listed earlier. The improved version should have an extensible format to add attributes(e.g. correlated or dependant histograms on functionaly dependant columns) w/o lots of changes. What triggers stats collection There must be a user knob in the form of ANALYZE SQL statement. Bulk insert operation inserting more then N values must also trigger ANALYZE to regresh the stats. Consumers ExeMgr or whatever the optimizer goes into is the most important consumer. The fact that there might be more then one EM in the cluster must be taken into account. Producers EM must initiate statistics collection. The statistics collection process must not differ much from SELECT * FROM query. The sampling method isn't yet choosen. Please see the design doc for more details. |
| Summary | Create mechanism for keeping and interpreting column statistics | Optimizer statistics |
| Sprint | 2021-7 [ 514 ] | 2021-7, 2021-8 [ 514, 521 ] |
| Description |
Optimizer statistics
Most engines feeds their query optimizers with different types of statistics, e.g histograms of most common values, fractions of NULL values, Number of Distinct Values, relation cardinality. The statistics allows to make educated guesses regarding cardinality of intermediate and final result of a query, e.g. optimizer finds the optimal join order using this statistics. MCS now has a rudimentary statistics that consist of a relation cardinality only. The goal We need to design and build facilities that allows MCS to make educated guesses about cardinality of intermediate and final result of a query and use this knowledge to produce an optimal plan. What is statistics The simplest version of statistics must have the list of attributes listed earlier. The improved version should have an extensible format to add attributes(e.g. correlated or dependant histograms on functionaly dependant columns) w/o lots of changes. What triggers stats collection There must be a user knob in the form of ANALYZE SQL statement. Bulk insert operation inserting more then N values must also trigger ANALYZE to regresh the stats. Consumers ExeMgr or whatever the optimizer goes into is the most important consumer. The fact that there might be more then one EM in the cluster must be taken into account. Producers EM must initiate statistics collection. The statistics collection process must not differ much from SELECT * FROM query. The sampling method isn't yet choosen. Please see the design doc for more details. |
Optimizer statistics
Most engines feeds their query optimizers with different types of statistics, e.g histograms of most common values, fractions of NULL values, Number of Distinct Values, relation cardinality. The statistics allows to make educated guesses regarding cardinality of intermediate and final result of a query, e.g. optimizer finds the optimal join order using this statistics. MCS now has a rudimentary statistics that consist of a relation cardinality only. The goal We need to design and build facilities that allows MCS to make educated guesses about cardinality of intermediate and final result of a query and use this knowledge to produce an optimal plan. What is statistics The simplest version of statistics must have the list of attributes listed earlier. The improved version should have an extensible format to add attributes(e.g. correlated or dependant histograms on functionaly dependant columns) w/o lots of changes. What triggers stats collection There must be a user knob in the form of ANALYZE SQL statement. Bulk insert operation inserting more then N values must also trigger ANALYZE to regresh the stats. Consumers ExeMgr or whatever the optimizer goes into is the most important consumer. The fact that there might be more then one EM in the cluster must be taken into account. Where to put stats and how to save it b/w restarts EMs in the cluster must have direct access to the stats so stats in-memory representation must reside in the RAM of the primary EM. Other EMs must have a synchronized version of the stats. Producers EM must initiate statistics collection. The statistics collection process must not differ much from SELECT * FROM query. The sampling method isn't yet choosen. Please see the design doc for more details. |
| Attachment | Screenshot from 2021-05-25 00-59-29.png [ 57838 ] |
{kind=link}
| Affects Version/s | All [ 25803 ] |
| Rank | Ranked higher |
| Sprint | 2021-7, 2021-8 [ 514, 521 ] | 2021-7, 2021-8, 2021-9 [ 514, 521, 541 ] |
| Fix Version/s | 6.1.1 [ 25600 ] | |
| Fix Version/s | 6.5.1 [ 25801 ] |
| Attachment | screen.jpg [ 58134 ] |
| Rank | Ranked lower |
| Assignee | Denis Khalikov [ JIRAUSER48434 ] | Daniel Lee [ dleeyh ] |
| Status | In Progress [ 3 ] | In Testing [ 10301 ] |
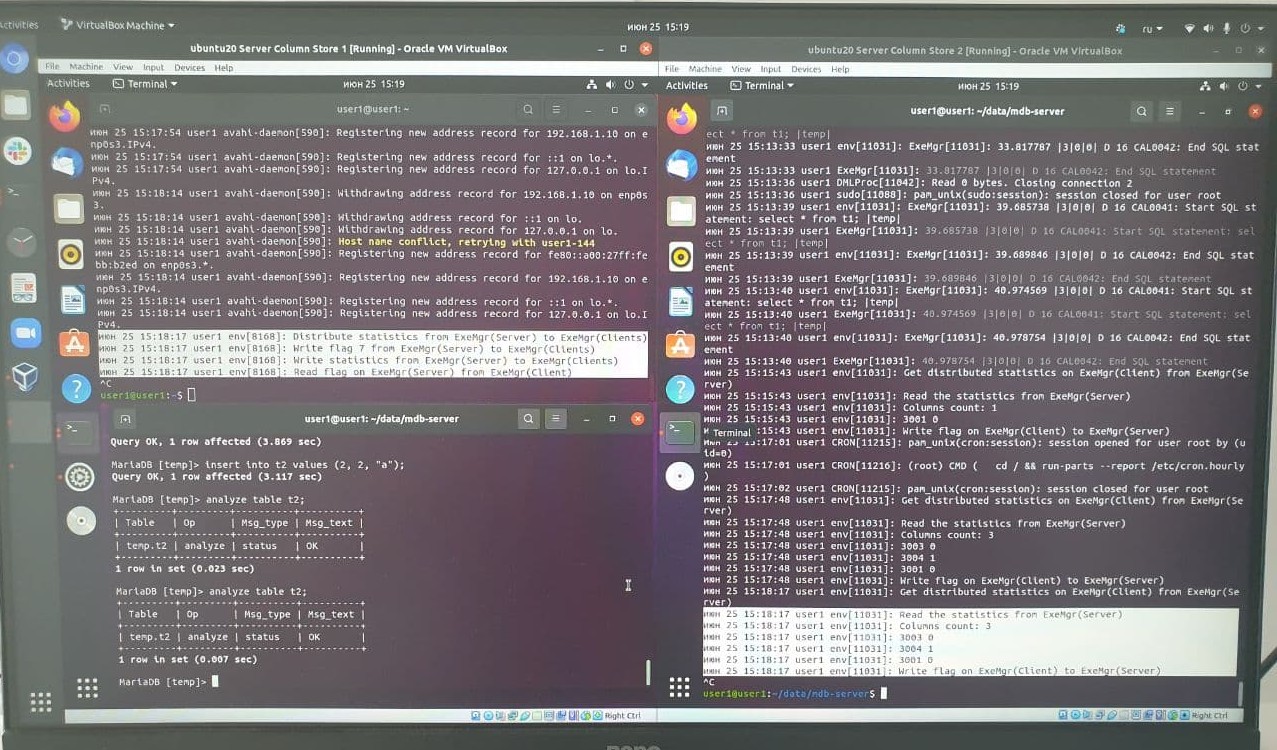
Build verified: 6.1.1 ( #2727)
MariaDB [tpch10]> analyze table customer, orders, lineitem, supplier, nation, region;
----------------------------------------+
| Table | Op | Msg_type | Msg_text |
----------------------------------------+
| tpch10.customer | analyze | status | OK |
| tpch10.orders | analyze | status | OK |
| tpch10.lineitem | analyze | status | OK |
| tpch10.supplier | analyze | status | OK |
| tpch10.nation | analyze | status | OK |
| tpch10.region | analyze | status | OK |
----------------------------------------+
6 rows in set (0.295 sec)
The analyze command did help dbt3's query #5 to work. Please see MCOL-1205.
| Resolution | Fixed [ 1 ] | |
| Status | In Testing [ 10301 ] | Closed [ 6 ] |
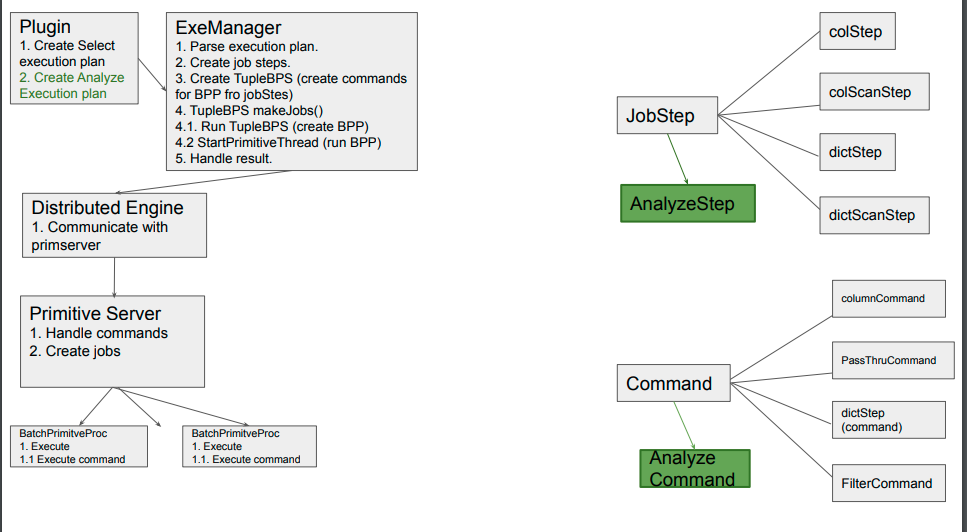
I would like to logically split this task into 3 sub tasks:
1. MCS Plugin part.
1.1. Implement the "Analyze Table execplan" in the MCS plugin part. (Handle analyze table command).
2. ExeManager.
2.1. Implement "Analyze Table Job Step", "Analyze Table Command".
2.2. Parse "Analyze Table execplan", lower it to "Analyze Column Job Steps" and initialize TupleBPS with it.
2.3. Transfer "Analyze Column Job Step" to Primitive Server as "Analyze Column Command ".
2.4. Initialize Batch primitive processor.
2.5. Run Batch Primitive processor.
3. Batch Primitive processor.
3.1. Implement statistic collection ("Analyze Column Command" execution) by Batch Primitive processor.
3.2. Collect statistics for column.
3.3. Send it back to ExeManager.