Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Not a Bug
-
2.4.11
-
None
-
Amazon EC2
-
MXS-SPRINT-117, MXS-SPRINT-118
Description
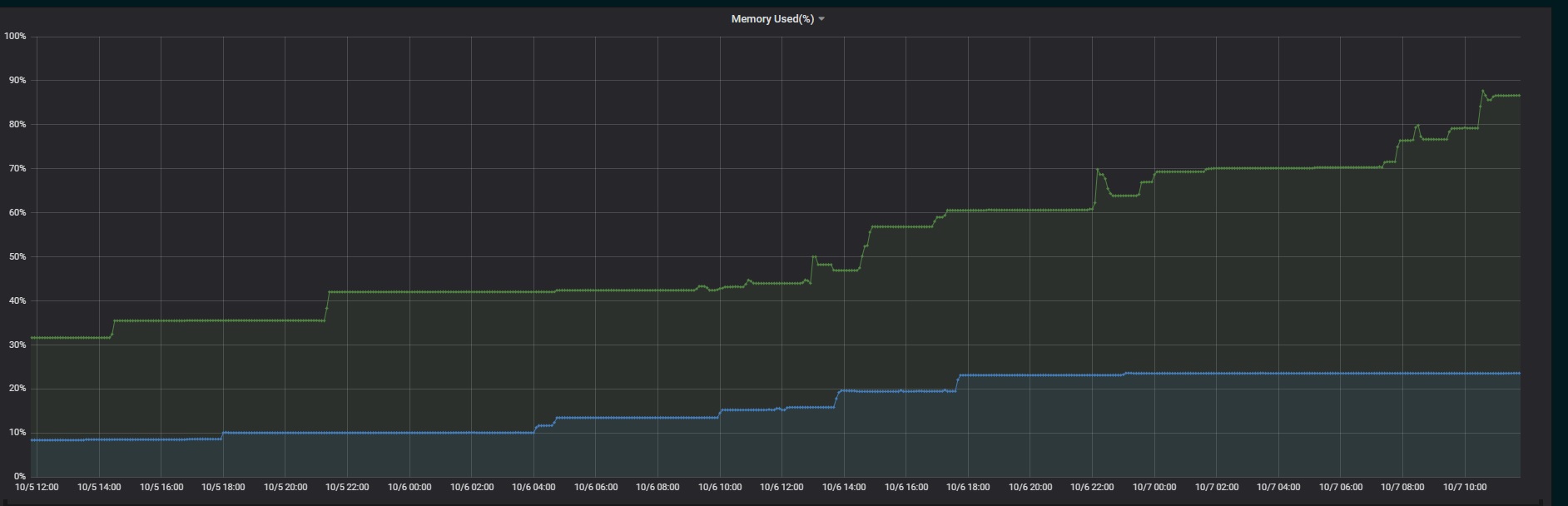
Customer reported maxcale memory usage keeps growing.
# maxscale node 1 |
[root@ip-21-105-20-139 ~]# free |
total used free shared buffers cached
|
Mem: 32467780 31823824 643956 76 71268 3887416 |
-/+ buffers/cache: 27865140 4602640 |
Swap: 10485756 0 10485756 |
{kind=link}