Details
-
Bug
-
Status: Closed (View Workflow)
-
 Blocker
Blocker
-
Resolution: Fixed
-
10.0.24, 5.5(EOL), 10.0(EOL), 10.1(EOL), 10.2(EOL)
-
Debian Wheezy and Jessie amd64
-
5.5.50
Description
Running the attached query (either with EXPLAIN or by simply doing the SELECT) on the following empty table will exhaust system memory in seconds(uses more than 10G of memory in less than 2 minutes), killing the query even less than a second after having executed it can take up to 30 seconds to finish (the query will be in "Killed" command and "statistics" state on the Processlist) while still keep eating up more memory.
Tested on both Wheezy and Jessie packaged versions of 10.0.24 with the same result, it didnt seemed to happen on 5.5.48 as i hit the bug only since i upgraded.
The bug doesnt happens when :
- Switching the engine to Aria or MyISAM
- When the optimizer switch "extended_keys" = "off" (which was the default on 5.5 but not since 10.0)
- When both columns are "tinyint"
- With only two values on each IN()/NOT IN()
Using "smallint" for both columns result in the query to be faster to kill but still not ending while eating memory.
–
CREATE TABLE `memoryexhaust` (
|
`id` int NOT NULL,
|
`secondary_id` int NOT NULL,
|
PRIMARY KEY (`id`),
|
KEY `secondary_id` (`secondary_id`)
|
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
|
Attachments
Issue Links
- causes
-
-
- Closed
-
- relates to
-
-

- Closed
-
-
-

- Open
-
-
-
- Closed
-
-
-
- Stalled
-
- mentioned in
-
Page Loading...
Activity
| Field | Original Value | New Value |
|---|---|---|
| Description |
Running the attached query (either with _EXPLAIN_ or by simply doing the _SELECT_) on the following empty table will exhaust system memory in seconds, killing the query even less than a second after having executed it can take up to 30 seconds to finish (the query will be in "Killed" command and "statistics" state on the Processlist) while still keep eating up more memory.
Tested on both Wheezy and Jessie packaged versions of 10.0.24 with the same result, it didnt seemed to happen on 5.5.48 as i hit the bug only since i upgraded. The bug doesnt happens when switching the engine to Aria or MyISAM or when both columns are "tinyint". Using "smallint" for both columns result in the query to be faster to kill but still not ending while eating memory. -- {code}CREATE TABLE `memoryexhaust` ( `id` int NOT NULL, `secondary_id` int NOT NULL, PRIMARY KEY (`id`), KEY `secondary_id` (`secondary_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;{code} |
Running the attached query (either with _EXPLAIN_ or by simply doing the _SELECT_) on the following empty table will exhaust system memory in seconds(uses more than 10G of memory in less than 2 minutes), killing the query even less than a second after having executed it can take up to 30 seconds to finish (the query will be in "Killed" command and "statistics" state on the Processlist) while still keep eating up more memory.
Tested on both Wheezy and Jessie packaged versions of 10.0.24 with the same result, it didnt seemed to happen on 5.5.48 as i hit the bug only since i upgraded. The bug doesnt happens when switching the engine to Aria or MyISAM or when both columns are "tinyint", it also doesnt happen with only two values on each IN()/NOT IN(). Using "smallint" for both columns result in the query to be faster to kill but still not ending while eating memory. -- {code}CREATE TABLE `memoryexhaust` ( `id` int NOT NULL, `secondary_id` int NOT NULL, PRIMARY KEY (`id`), KEY `secondary_id` (`secondary_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;{code} |
| Description |
Running the attached query (either with _EXPLAIN_ or by simply doing the _SELECT_) on the following empty table will exhaust system memory in seconds(uses more than 10G of memory in less than 2 minutes), killing the query even less than a second after having executed it can take up to 30 seconds to finish (the query will be in "Killed" command and "statistics" state on the Processlist) while still keep eating up more memory.
Tested on both Wheezy and Jessie packaged versions of 10.0.24 with the same result, it didnt seemed to happen on 5.5.48 as i hit the bug only since i upgraded. The bug doesnt happens when switching the engine to Aria or MyISAM or when both columns are "tinyint", it also doesnt happen with only two values on each IN()/NOT IN(). Using "smallint" for both columns result in the query to be faster to kill but still not ending while eating memory. -- {code}CREATE TABLE `memoryexhaust` ( `id` int NOT NULL, `secondary_id` int NOT NULL, PRIMARY KEY (`id`), KEY `secondary_id` (`secondary_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;{code} |
Running the attached query (either with _EXPLAIN_ or by simply doing the _SELECT_) on the following empty table will exhaust system memory in seconds(uses more than 10G of memory in less than 2 minutes), killing the query even less than a second after having executed it can take up to 30 seconds to finish (the query will be in "Killed" command and "statistics" state on the Processlist) while still keep eating up more memory.
Tested on both Wheezy and Jessie packaged versions of 10.0.24 with the same result, it didnt seemed to happen on 5.5.48 as i hit the bug only since i upgraded. The bug doesnt happens when : * Switching the engine to Aria or MyISAM * When the optimizer switch "_extended\_keys_" = "_off_" (which was the default on 5.5 but not since 10.0) * When both columns are "tinyint" * With only two values on each IN()/NOT IN() Using "smallint" for both columns result in the query to be faster to kill but still not ending while eating memory. -- {code}CREATE TABLE `memoryexhaust` ( `id` int NOT NULL, `secondary_id` int NOT NULL, PRIMARY KEY (`id`), KEY `secondary_id` (`secondary_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;{code} |
| Summary | Quick memory exhaustion on queries having multiple "IN"/"NOT IN" using InnoDB | Quick memory exhaustion with 'extended_keys=on' on queries having multiple 'IN'/'NOT IN' using InnoDB |
| Status | Open [ 1 ] | Confirmed [ 10101 ] |
| Component/s | Optimizer [ 10200 ] | |
| Fix Version/s | 5.5 [ 15800 ] | |
| Fix Version/s | 10.0 [ 16000 ] | |
| Fix Version/s | 10.1 [ 16100 ] | |
| Affects Version/s | 5.5 [ 15800 ] | |
| Affects Version/s | 10.0 [ 16000 ] | |
| Affects Version/s | 10.1 [ 16100 ] | |
| Assignee | Sergei Petrunia [ psergey ] |
The query has form:
EXPLAIN SELECT id
|
FROM memoryexhaust
|
WHERE
|
(
|
(secondary_id IN (...)) OR
|
(secondary_id IN (...)) OR
|
(secondary_id IN (...)) OR
|
...
|
)
|
AND
|
(
|
(id NOT IN (...)) AND
|
(id NOT IN (...)) AND
|
(id NOT IN (...)) AND
|
...
|
);
|
Similar issues.
The were two patches pushed already to 10.1 for MDEV-9764. These should make memory usage somewhat lower (but not fully eliminate it).
| Link | This issue relates to MDEV-10046 [ MDEV-10046 ] |
| Sprint | 5.5.50 [ 71 ] |
| Rank | Ranked higher |
| Affects Version/s | 10.2 [ 14601 ] |
| Priority | Major [ 3 ] | Critical [ 2 ] |
| Fix Version/s | 10.2 [ 14601 ] |
| Support case ID | 23633 | not-23633 |
| Priority | Critical [ 2 ] | Major [ 3 ] |
| Priority | Major [ 3 ] | Critical [ 2 ] |
| Fix Version/s | 5.5 [ 15800 ] | |
| Fix Version/s | 10.0 [ 16000 ] |
| Status | Confirmed [ 10101 ] | In Progress [ 3 ] |
Reproducible on recent 10.4 (and I believe it will be on 10.5, too)
I've added ignore index (PRIMARY) into memoryexhaust.sql and it's stillreproducible.
Debugging one can see that PARAM::alloced_sel_args=0, but the number of SEL_ARG::SEL_ARG calls (total for all signatures) is over 100M and the optimizer is still running.
Ok
EXPLAIN SELECT id FROM memoryexhaust WHERE
|
.
(
|
(secondary_id IN (10040,10041,10042, ... <about 250 elements> ))
|
OR (secondary_id IN (14549,14550,14566, ... <about 250 elements> )))
|
OR (secondary_id IN (18169,19037,19038, ... <about 250 elements> )))
|
....
|
....
|
)
|
AND
|
The above has about 5K constants.
range optimizer constructs around 4086 SEL_ARG objects when processing it.
AND
|
(
|
(id NOT IN (10040,10041,10042, ... <about 250 elements>)) AND
|
(id NOT IN (14549,14550,14566, ... <about 250 elements>)) AND
|
...
|
);
|
4K constants in total, 254 pcs in each NOT IN clause except the last one. 17
NOT IN clauses.
Range optimizer constructs 42K SEL_ARGS when processing this.
| Attachment | pic1.png [ 54381 ] |
| Attachment | pic2.png [ 54382 ] |
| Attachment | pic3.png [ 54383 ] |
My theory about what's going on here.
First, the optimizer produces a SEL_ARG graph representing a range list on secondary_id.
Then, the same happens for the first NOT IN:
(id NOT IN (10040,10041,10042,...)) |
This produces a range list with almost-touching ranges:
(-inf < id < 10040) U (10040 < id < 10041) U (10040 < id < 10041) ...
|
When AND-ing these two, we get this kind of graph:
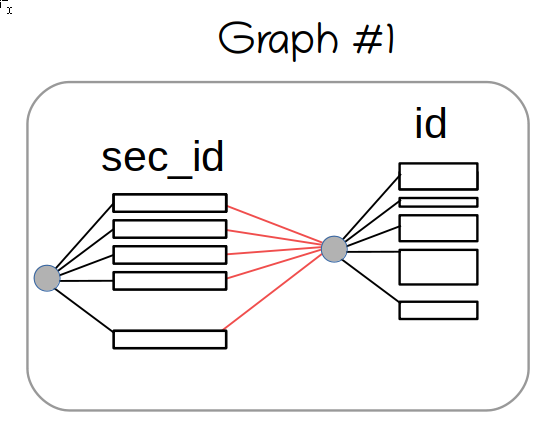
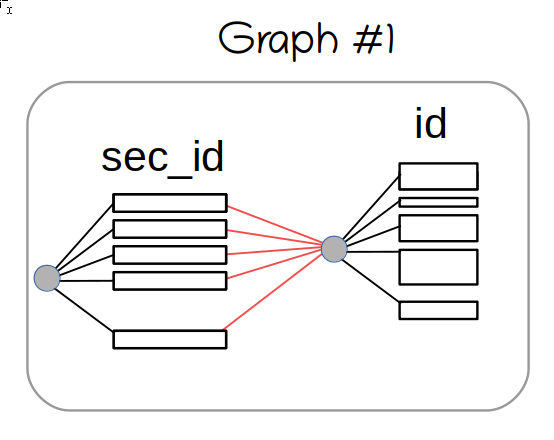
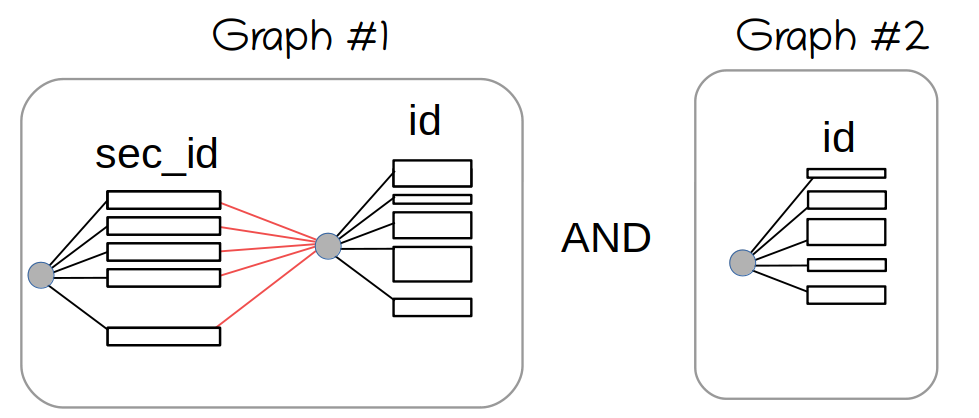
red color shows the SEL_ARG::next_key_part edges. The tree representing the second key part is shared, so the memory consumption is not an issue, yet.
Then, we try to AND this with another graph:
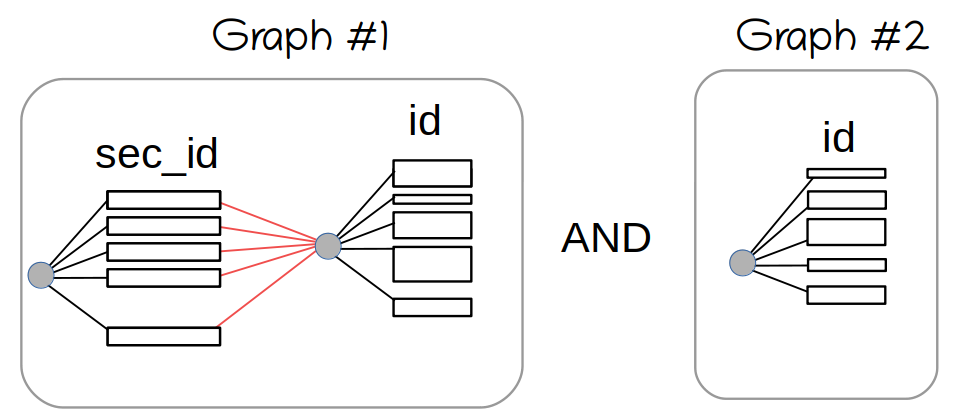
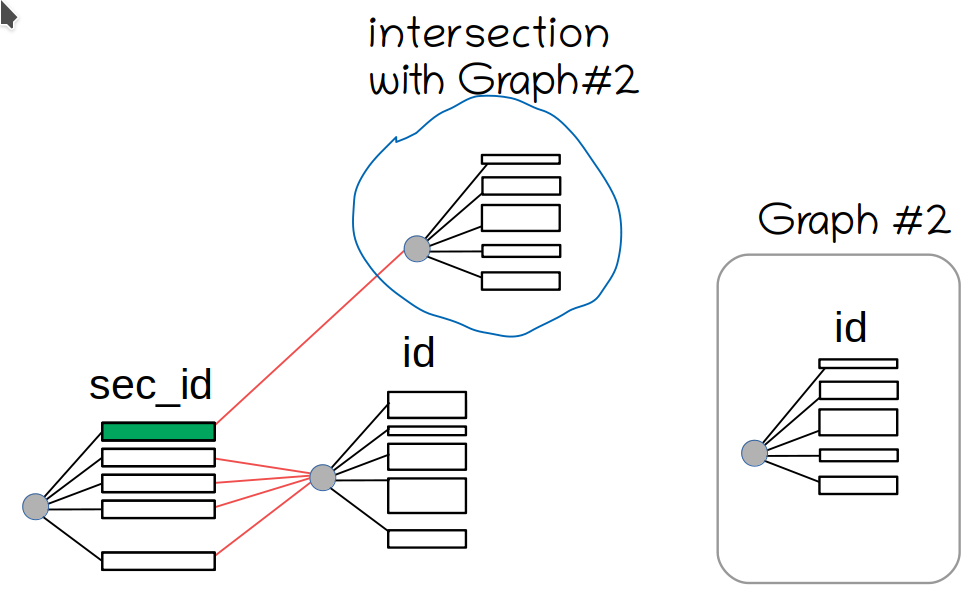
And here, the issues start.
We arrive at the first SEL_ARG element (shown in green). We see there's a shared graph connected through next_key_part pointer. It's shared, so we can't make any modifications to it. So we clone it, and compute the AND:
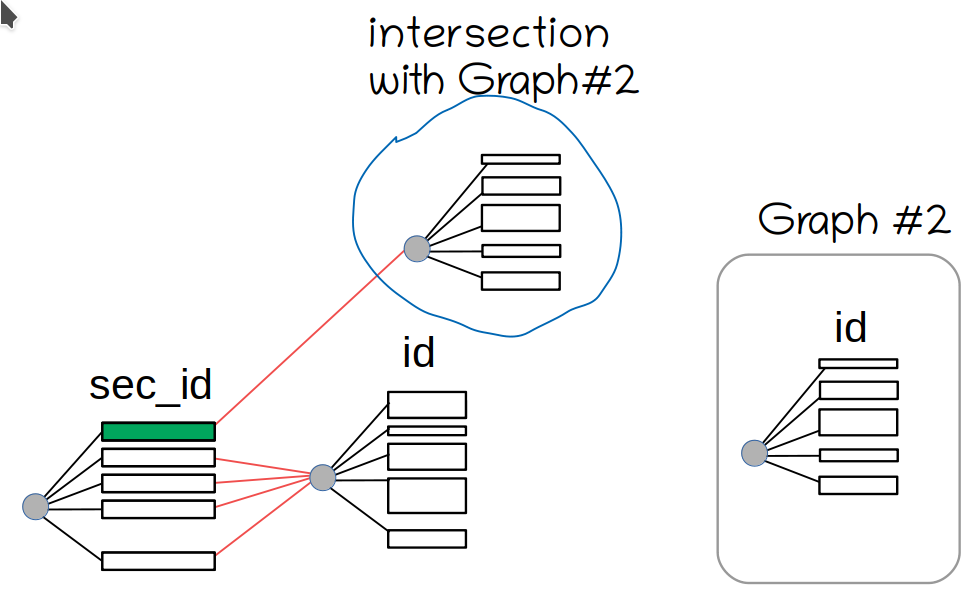
The same goes on for each range on the sec[ondary]_id.
There are 4K intervals on the secondary_id, and each NOT-IN-id list has 250 elements.
This means we will create 4K * 250 = 1M SEL_ARG objects.
When processing the next NOT-IN clause, we will need to fork 500 element tree (since NOT-IN lists do not have common elements). 4K * 500 = 2M
In total there are 16 NOT IN clauses so we'll need to create
1M + 2M + 4M + ... + 1M*2^16 = 1M * 2^17 = 1M * 128K = 128G
|
128 billion SEL_ARG objects.
... the first idea is to make sharing more aggressive. If we were computing a key_or(ptr1, ptr2) where ptr1 and ptr2 were shared, and got ptr3, maybe the next operation which also computes key_or(ptr1, ptr2) should just grab ptr3 as result (and increase its share counter).
This might solve the memory issue, but would it make the query speed adequate?
I have re-ordered parts of the WHERE clause so that
1. ranges on "id" are computed first
2. then they are attached to the ranges on secondary_id
like so:
WHERE
|
(
|
(id NOT IN (10040,10041,10042, ... <about 250 elements>)) AND |
(id NOT IN (14549,14550,14566, ... <about 250 elements>)) AND |
...
|
)AND |
(
|
(secondary_id IN (10040,10041,10042, ... <about 250 elements> )) |
OR (secondary_id IN (14549,14550,14566, ... <about 250 elements> ))) |
OR (secondary_id IN (18169,19037,19038, ... <about 250 elements> ))) |
....
|
....
|
)
|
and now I see that get_mm_tree() part of the range optimizer computes fairly quickly (with total # of SEL_ARG objects constructed = 46716).
But then the optimizer is stuck in doing records_in_range calls.
It has done 12,415,264 and counting.
One can expect in total 5K * 4K = 20M calls.
This calls for a different solution.
| Attachment | memoryexhaust-order2.sql [ 54384 ] |
memoryexhaust-order2.sql![]() modified query described in the previous comment
modified query described in the previous comment
I think the right approach is to modify the optimizer to not produce SEL_ARG graphs that represent > N_MAX ranges, even if the graph itself has [much] less than N_MAX nodes.
Not producing should be achieved by discarding parts of the graph that represent bigger key parts.
Note to self: a bug in this part of code have been fixed recently, it is MDEV-23811. (That fix won't help with this bug, but there might be an overlap in the patches)
Attempts on MySQL-8:
- The original query uses full index scan. Debugger shows that the top get_mm_tree() call returns NULL. It seems, they discard the SEL_ARG graph if it gets too large.
- The modified query ( memoryexhaust-order2.sql ) runs forever (22 minutes for the empty table).
mysql> source memoryexhaust.sql
|
+----+-------------+---------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|
+----+-------------+---------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
|
| 1 | SIMPLE | memoryexhaust | NULL | index | secondary_id | secondary_id | 4 | NULL | 1 | 100.00 | Using where; Using index |
|
+----+-------------+---------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
|
1 row in set, 2 warnings (0.42 sec)
|
and one of the warnings is:
| Warning | 3170 | Memory capacity of 8388608 bytes for 'range_optimizer_max_mem_size' exceeded. Range optimization was not done for this query.
|
MySQL8 implements the check for range_optimizer_max_mem_size using MEM_ROOT::m_max_capacity.
mysql> source memoryexhaust-order2.sql
|
+----+-------------+---------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
|
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|
+----+-------------+---------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
|
| 1 | SIMPLE | memoryexhaust | NULL | index | secondary_id | secondary_id | 4 | NULL | 1 | 100.00 | Using where; Using index |
|
+----+-------------+---------------+------------+-------+---------------+--------------+---------+------+------+----------+--------------------------+
|
1 row in set, 1 warning (22 min 12.42 sec)
|
A suggestion for a fix:
Definitions:
SEL_ARG tree - a set of SEL_ARG structures describing the same key part and connected via prev/next/left/right links.
SEL_ARG graph - same as above but not limited to the same keypart. SEL_ARGs can be connected via next_key_part link, too.
SEL_ARG graph weight
Let each SEL_ARG graph have a "weight". Weight is a metric that's similar to "number of ranges the SEL_ARG graph would generate" but not exactly that as it ignores the limitations that range generation imposes. These limitations include:
- keyparts are adjacent and start from #1: keypart1, keypart2, ...
- SEL_ARG on keypartN+1 can only be used if SEL_ARG on keypartN denotes a bound-including interval.
- etc
if we assume none of that would prevent generation of ranges, then the number of ranges is the weight.
An alternative definition of weight: take a SEL_ARG graph, and make sure there are no "shared trees". That is, there are no nodes with multiple incoming next_key_part links. If the graph has is such nodes, clone them.
Once the graph doesn't use sharing, count the number of SEL_ARG nodes that have next_key_part=NULL, and that will be the weight.
Another possible way to define the weight is: let it be the total number of nodes that SEL_ARG graph would have if sharing is eliminated.
Using the weight.
Don't construct overweight graphs.
When OR-ing or AND-ing SEL_ARG graphs, compute the weight of the result.
If the weight exceeds MAX_WEIGHT:
find max key part used in the graph
remove SEL_ARG nodes (actually whole trees) with key_part=max_key_part.
Repeat the above until the graph is within the weight limit.
Note: when removing SEL_ARG trees, we don't need to care if the node referring to that tree is shared or not. The criteria for removal remains the same regardless of the path that we have arrived to the next_key_part link to the tree we're removing.
Note: SEL_ARG::max_part_no is not actually the number of the biggest key part
present in the tree currently. It is the number of the max key part in some
sub-tree at some point in the past.
Example:
create table t1 (
|
a int,
|
b int,
|
c int,
|
filler char(100),
|
key (a,b,c)
|
);
|
insert into t1 select a,a,a,a from one_k;
|
explain
|
select * from t1
|
where
|
(a between 10 and 20 and b=3 and c=3) or (a between 10 and 20);
|
(gdb) set $a= (tree->keys[0])
|
(gdb) p $a->max_part_no
|
$99 = 3
|
(gdb) p $a->next
|
$100 = (SEL_ARG *) 0x0
|
(gdb) p $a->prev
|
$101 = (SEL_ARG *) 0x0
|
(gdb) p $a->next_key_part
|
$102 = (SEL_ARG *) 0x0
|
(gdb) p dbug_print_sel_arg($a)
|
$103 = 0x7fff6c067340 "SEL_ARG(10<=a<=20)"
|
| Labels | range-optimizer |
Pushed dbug_print_sel_arg patch into 10.2: https://github.com/MariaDB/server/commit/a593e03d58f922a99ba49de1bec6810fc7e9874f
(It doesn't do anything to solve the issue but it helps with debugging).
| Assignee | Sergei Petrunia [ psergey ] | Igor Babaev [ igor ] |
| Status | In Progress [ 3 ] | In Review [ 10002 ] |
| Link |
This issue relates to |
| Fix Version/s | 10.1 [ 16100 ] |
Sergei,
Let's look at your test case. What happens if you add index key2(kp2, kp3,kp4). In this case ranges for key1 and key2 will share the same SEL_ARGs. Will it affect the prune process?
Hi igor,
What happens if you add index key2(kp2, kp3,kp4). In this case ranges for key1 and key2 will share the same SEL_ARGs.
Nitpick: No, they would not, as SEL_ARGs on different indexes are not shared. I've just debugged this:
explain select * from t1 where kp2<10 and kp1 <=200; |
and the execution hit SEL_ARG::SEL_ARG 3 times.
Will it affect the prune process?
But your question is valid, can it occur that the tree that is pruned is shared, and what should be done in that case. Let me get back on this.
.. well, the answer is that yes, it is possible. I don't think doing pruning in a shared sub-graph causes harm , but it makes the semantics of the operation complex.
igor Please find the variant of the patch that only does pruning for complete graphs:
http://lists.askmonty.org/pipermail/commits/2020-November/014351.html
A patch with more comments: http://lists.askmonty.org/pipermail/commits/2020-November/014355.html
| Assignee | Igor Babaev [ igor ] | Sergei Golubchik [ serg ] |
| Assignee | Sergei Golubchik [ serg ] | Julien Fritsch [ julien.fritsch ] |
| Assignee | Julien Fritsch [ julien.fritsch ] | Sergei Petrunia [ psergey ] |
| Status | In Review [ 10002 ] | Stalled [ 10000 ] |
Review input:
Fix the comment with the definition of the weight
Something like "verify_weight" which we could run after every operation in debug mode
- Cut of the level of the tree that has the biggest weight, independent of level!
- consider: if there is a keypart gap, and after the gap there is a heavy tree, remove that.
Make the MAX_WEIGHT user-visibleMove this part of code into and_all_keys():+ Do not combine the trees if their total weight is likely to exceed the+ MAX_WEIGHT.
Print the weight into the optimizer trace (perhaps also print if the cutting has happened)
Patch addressing almost all of the input:
https://github.com/MariaDB/server/commit/ef5fe786a2f6608a67a34b1bfe91603d9a9f04f7
Branch on github https://github.com/MariaDB/server/tree/bb-10.4-mdev9750-v2
| Priority | Critical [ 2 ] | Blocker [ 1 ] |
| Fix Version/s | 10.5.9 [ 25109 ] | |
| Fix Version/s | 10.2 [ 14601 ] |
| Resolution | Fixed [ 1 ] | |
| Status | Stalled [ 10000 ] | Closed [ 6 ] |
| Link |
This issue relates to |
| Link |
This issue relates to |
| Labels | range-optimizer | ServiceNow range-optimizer |
| Labels | ServiceNow range-optimizer | 76qDvLB8Gju6Hs7nk3VY3EX42G795W5z range-optimizer |
| Labels | 76qDvLB8Gju6Hs7nk3VY3EX42G795W5z range-optimizer | range-optimizer |
| Workflow | MariaDB v3 [ 74581 ] | MariaDB v4 [ 150238 ] |
| Link | This issue relates to MDEV-24725 [ MDEV-24725 ] |
| Link |
This issue causes |
| Zendesk Related Tickets | 201658 176536 183515 | |
| Zendesk active tickets | 201658 |
| Remote Link | This issue links to "Page (MariaDB Confluence)" [ 37255 ] |
| Remote Link | This issue links to "Page (MariaDB Confluence)" [ 37258 ] |
| Remote Link | This issue links to "Page (MariaDB Confluence)" [ 37255 ] |
Thanks for the report and test case.