Limiting look-ahead when the user doesn't need the rrf value.
The task
So, we're looking to efficiently compute a query in this form:
SELECT
id,
1/(60 + RANK() OVER (ORDERBY VEC_DISTANCE(vec, x'03401272819837e')))
+
1/(60 + RANK() OVER (ORDERBY MATCH (text) AGAINST ("red tshirt with fun text") DESC))
AS rrf
FROM
t1
ORDERBY rrf DESC
LIMIT 10
(TODO: is this RANK() where peers are equal or ROW_NUMBER()? This is not important at this point)
(TODO: does the user actually need the value of rrf or it's only there for ORDER BY? A: no, the value of rrf is only usable for ordering)
We can construct index scans that return rows in the increasing ORDER BY criteria.
Can we construct a query plan that would take advantage of the LIMIT and scan fewer rows?
Search algorithm draft
So, we have
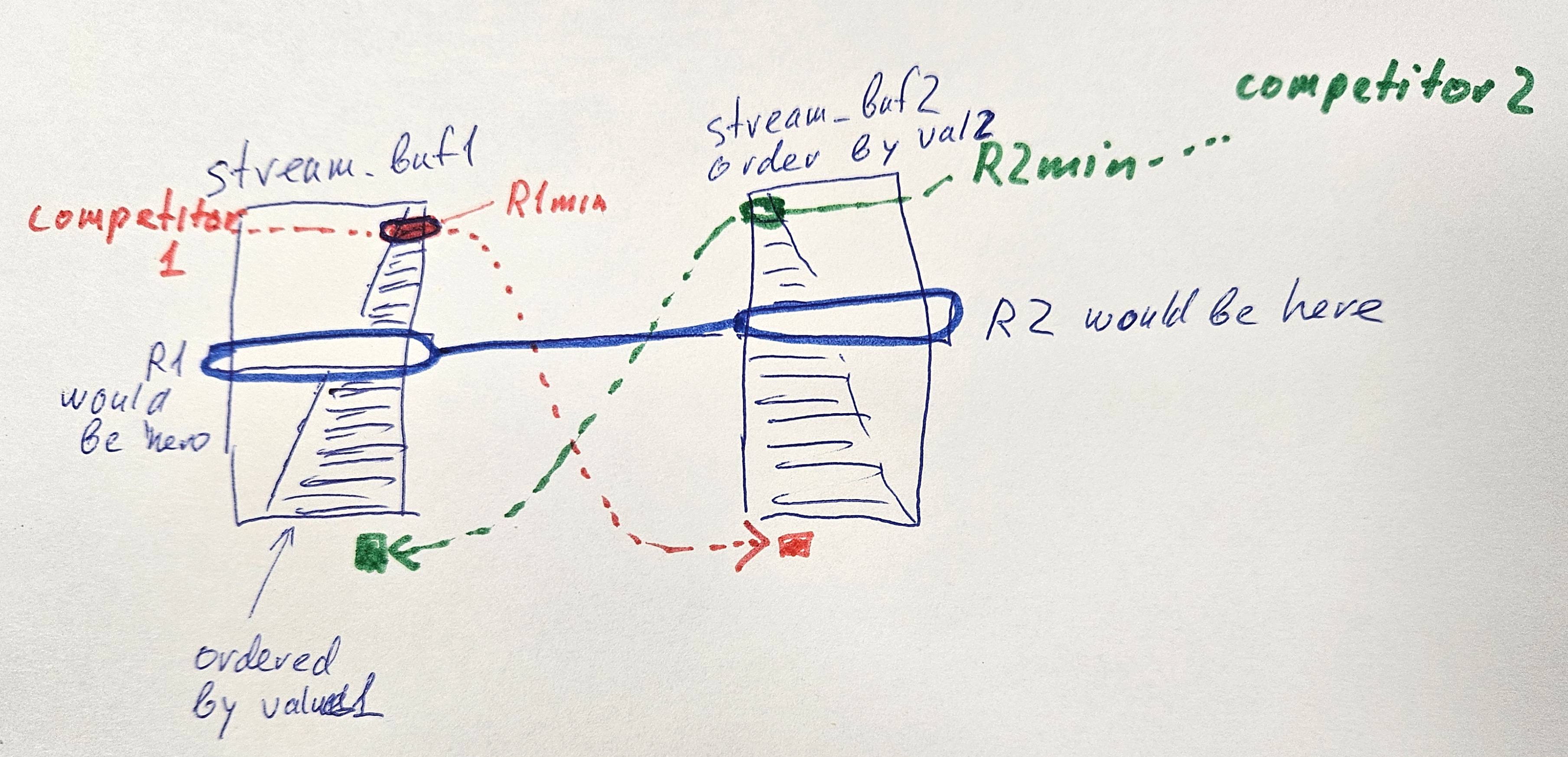
stream1 produces (value1,rowid) ordered by value1 desc
stream2 produces (value2,rowid) ordered by value2 desc
and we want to produce first LIMIT $LIMIT rows ordered by
value1 + value2 DESC
Do as follows:
const N= <pick some reasonable lookahead size>;
Priority_queue priority_queue(size=N);
start:
get N rows from stream1 into stream_buf1;
get N rows from stream2 into stream_buf2;
if (stream_buf1.is_empty() && steam_buf2.is_empty())
return;
foreach row R1 in stream_buf1 {
if (R2= stream_buf2.find_row(R1.rowid)) {
// Ok, {R1,R2} is a matching combination.
priority_queue.put({ R1, R2 });
stream_buf1.delete_row(R1);
stream_buf2.delete_row(R2);
}
}
Ok, priority_queue has matching record combinations. Can we emit them already?
Consider a row combination {R1, R2} that's in the priority_queue.
Let's take the "most competitive" value from stream_buf1:
R1min= stream_buf1.first_value1();
We know it doesn't have a match in stream_buf2 (we would have removed it if it did).
Its match is "worse" than anything in stream_buf2. The "worst" value there is stream_buf2.last_value2(). On the picture, these are drawn in red:
while ( {R1, R2} = priority_queue.top_element()) {
if (R1.value1 + R2.value2< min_bound) {
priority_queue.remove_top();
emit_row({R1, R2});
else
break;
}
At this point, we may have:
something left in the priority_queue
some "singles" in stream_buf1 and stream_buf2 that haven't got their match, yet.
We should read more rows from the input and continue the process, so we:
goto start;
Notes about the algorithm
There's no limit on how large stream_buf1 and stream_buf2 can get.
If we're unlucky and the searches return rows with few/no overlaps we can end up having stream_buf1.size() + stream_buf2.size() = rows_in_the_table .
A case of non-matches
A problem with the used SQL form is that we must find the rank() for both parts of the rrf.
Suppose we scan 1000 rows in the vector index and get rowids of 1000 nearest rows:
+------------------+-------+
| 1/(60+RANK(...))| rowid |
+------------------+-------+
| 0.0164 | rw1 |
| 0.0161 | rw2 |
| 0.0159 | rw3 |
| 0.0156 | ... |
| 0.0154 | |
| 0.0152 | |
| 0.0149 | |
| 0.0147 | |
| 0.0145 | |
...
...
| 0.0009 | |
+------------------+-------+
and get the same, rowids of rows with 1000 best fulltext matches.
Suppose these have no overlap at all.
Then, do we really want to continue searching to find matches for the best rows?
The best row has a vector score of 0.0164 .
We know its fulltext score is less than 0.0009, that is, it will make a difference of less than 5.4 %.
Maybe we should take the #LIMIT=10 rows with the best partial scores we've seen so far and return them?
The search is approximate anyhow.
Limiting look-ahead when the user doesn't need the rrf value.
If we only get rows without matches, how far do we need to look
before we know that the row with R(1) is ordered as first regardless
of what rank it has in the other "source" ?
This is
Task
 Major
Major
MDEV-36593 Window functions: reuse sorting and/or scanning with the main query
MDEV-35629 Hybrid Search (Text + Vector) w/ Simple Re-Ranking

MDEV-36538 EXPLAIN shows wrong rows value for LIMIT in derived tables