Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Not a Bug
-
11.7.0
-
Not for Release Notes
-
Description
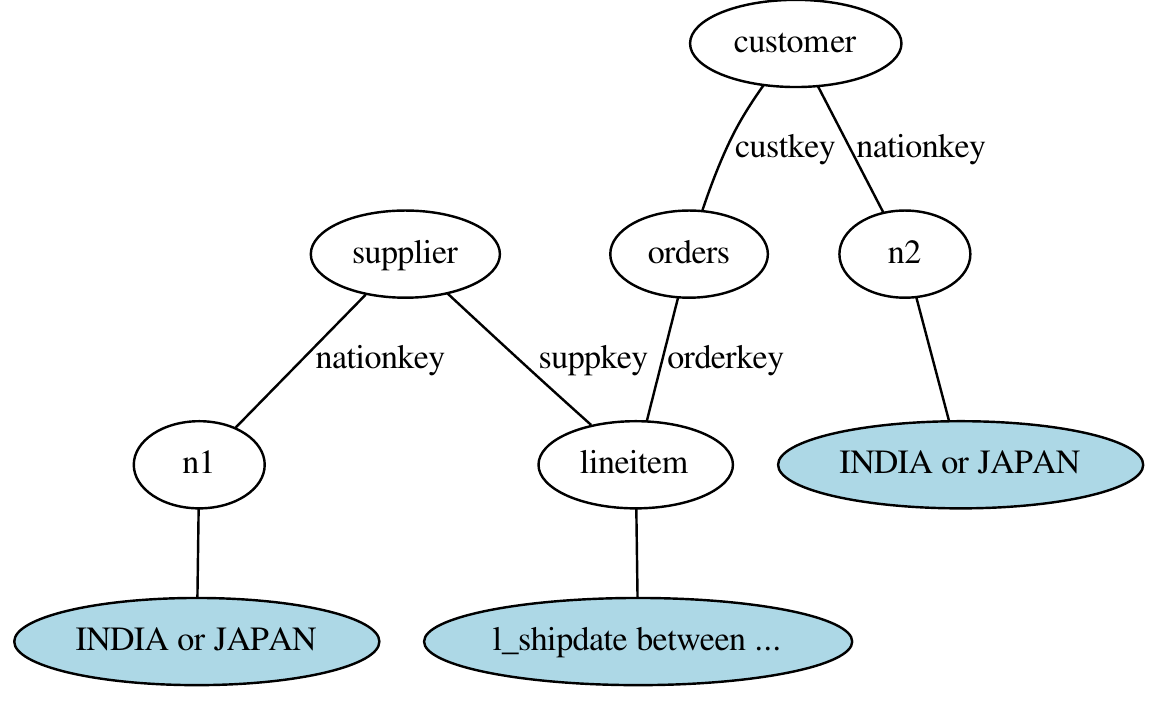
For query 7 in the TPC-H benchmark;
select
|
supp_nation,
|
cust_nation,
|
l_year,
|
sum(volume) as revenue |
from
|
(
|
select |
n1.n_name as supp_nation, |
n2.n_name as cust_nation, |
extract(
|
year |
from |
l_shipdate
|
) as l_year, |
l_extendedprice * (1 - l_discount) as volume |
from |
SUPPLIER,
|
LINEITEM,
|
ORDERS,
|
CUSTOMER,
|
NATION n1,
|
NATION n2
|
where |
s_suppkey = l_suppkey
|
and o_orderkey = l_orderkey |
and c_custkey = o_custkey |
and s_nationkey = n1.n_nationkey |
and c_nationkey = n2.n_nationkey |
and ( |
(
|
n1.n_name = 'JAPAN' |
and n2.n_name = 'INDIA' |
)
|
or ( |
n1.n_name = 'INDIA' |
and n2.n_name = 'JAPAN' |
)
|
)
|
and l_shipdate between date '1995-01-01' and date '1996-12-31' |
) as shipping |
group by |
supp_nation,
|
cust_nation,
|
l_year
|
order by |
supp_nation,
|
cust_nation,
|
l_year;
|
When executing with ANALYZE, its query plan and execution time are:
id select_type table type possible_keys key key_len ref rows r_rows filtered r_filtered Extra
|
1 SIMPLE ORDERS index PRIMARY,ORDERS_FK1 ORDERS_FK1 4 NULL 1488600 1500000.00 100.00 100.00 Using index; Using temporary; Using filesort
|
1 SIMPLE CUSTOMER eq_ref PRIMARY,CUSTOMER_FK1 PRIMARY 4 tpch.ORDERS.O_CUSTKEY 1 1.00 100.00 100.00
|
1 SIMPLE n2 eq_ref PRIMARY PRIMARY 4 tpch.CUSTOMER.C_NATIONKEY 1 1.00 100.00 7.95 Using where
|
1 SIMPLE LINEITEM ref PRIMARY PRIMARY 4 tpch.ORDERS.O_ORDERKEY 3 4.00 100.00 30.38 Using where
|
1 SIMPLE SUPPLIER eq_ref PRIMARY,SUPPLIER_FK1 PRIMARY 4 tpch.LINEITEM.L_SUPPKEY 1 1.00 100.00 100.00
|
1 SIMPLE n1 eq_ref PRIMARY PRIMARY 4 tpch.SUPPLIER.S_NATIONKEY 1 1.00 100.00 4.10 Using where
|
|
|
0.00s user 0.00s system 0% cpu 11.165 total
|
If we apply the following patch:
diff --git a/sql/sql_select.cc b/sql/sql_select.cc
|
index d6e9818a5a2..eac319b24d3 100644
|
--- a/sql/sql_select.cc
|
+++ b/sql/sql_select.cc
|
@@ -12707,23 +12707,6 @@ prev_record_reads(const POSITION *position, uint idx, table_map found_ref,
|
|
for (const POSITION *pos= cur_pos-1; pos != pos_end; pos--)
|
{
|
- if (found_ref & pos->table->table->map)
|
- {
|
- /* Found a table we depend on */
|
- found_ref= ~pos->table->table->map;
|
- if (!found_ref)
|
- {
|
- /*
|
- No more dependencies. We can use the cached values to improve things
|
- a bit
|
- */
|
- if (pos->type == JT_EQ_REF)
|
- found= COST_MULT(found, pos->identical_keys);
|
- else if (pos->use_join_buffer)
|
- found= COST_MULT(found, pos->loops / pos->refills);
|
- }
|
- break;
|
- }
|
if (unlikely(pos->use_join_buffer))
|
{
|
/* Each refill can change the cached key */
|
The query plan and the execution time are:
id select_type table type possible_keys key key_len ref rows r_rows filtered r_filtered Extra
|
1 SIMPLE LINEITEM ALL PRIMARY NULL NULL NULL 5797664 6001215.00 100.00 30.47 Using where; Using temporary; Using filesort
|
1 SIMPLE SUPPLIER eq_ref PRIMARY,SUPPLIER_FK1 PRIMARY 4 tpch.LINEITEM.L_SUPPKEY 1 1.00 100.00 100.00
|
1 SIMPLE ORDERS eq_ref PRIMARY,ORDERS_FK1 PRIMARY 4 tpch.LINEITEM.L_ORDERKEY 1 1.00 100.00 100.00
|
1 SIMPLE CUSTOMER eq_ref PRIMARY,CUSTOMER_FK1 PRIMARY 4 tpch.ORDERS.O_CUSTKEY 1 1.00 100.00 100.00
|
1 SIMPLE n2 eq_ref PRIMARY PRIMARY 4 tpch.CUSTOMER.C_NATIONKEY 1 1.00 100.00 7.92 Using where
|
1 SIMPLE n1 eq_ref PRIMARY PRIMARY 4 tpch.SUPPLIER.S_NATIONKEY 1 1.00 100.00 4.10 Using where
|
|
|
0.01s user 0.00s system 0% cpu 6.775 total
|
The performance seems unexpectedly improved after the patch. I am not proposing a patch to directly modify the code. I am wondering whether we can optimize the logic of function prev_record_reads() to enable the second query plan for a better performance.
I used 1 GB of data for the TPC-H benchmark. Configuring TPC-H requires some effort, so I also attach my entire database for your reference: https://drive.google.com/file/d/1PQF7FOHu2VQYUC9aUG69M2u_7BgNCeN_/view?usp=sharing
The username is root. and the password is root.