Details
-
Bug
-
Status: Open (View Workflow)
-
 Major
Major
-
Resolution: Unresolved
-
10.6.16
-
None
Description
Environment - 3-node Galera cluster, Maxscale r/w splitting. CentOS 7.9, 10.6.16 Community Edition.
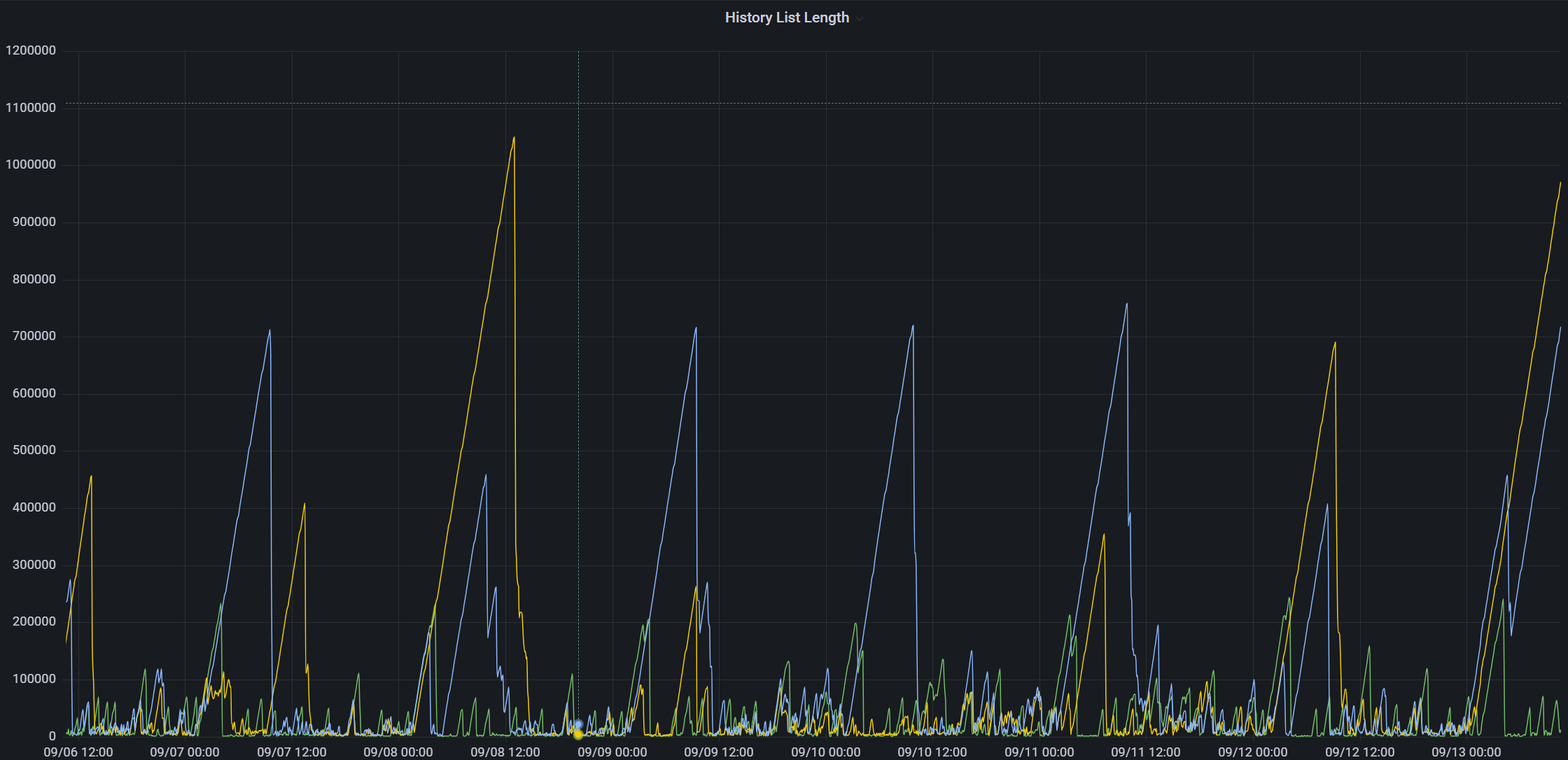
A busy database (continual traffic of 1,000+ updates/second), where a very long (5hrs+) query runs daily at ~3am on a "reader" node.
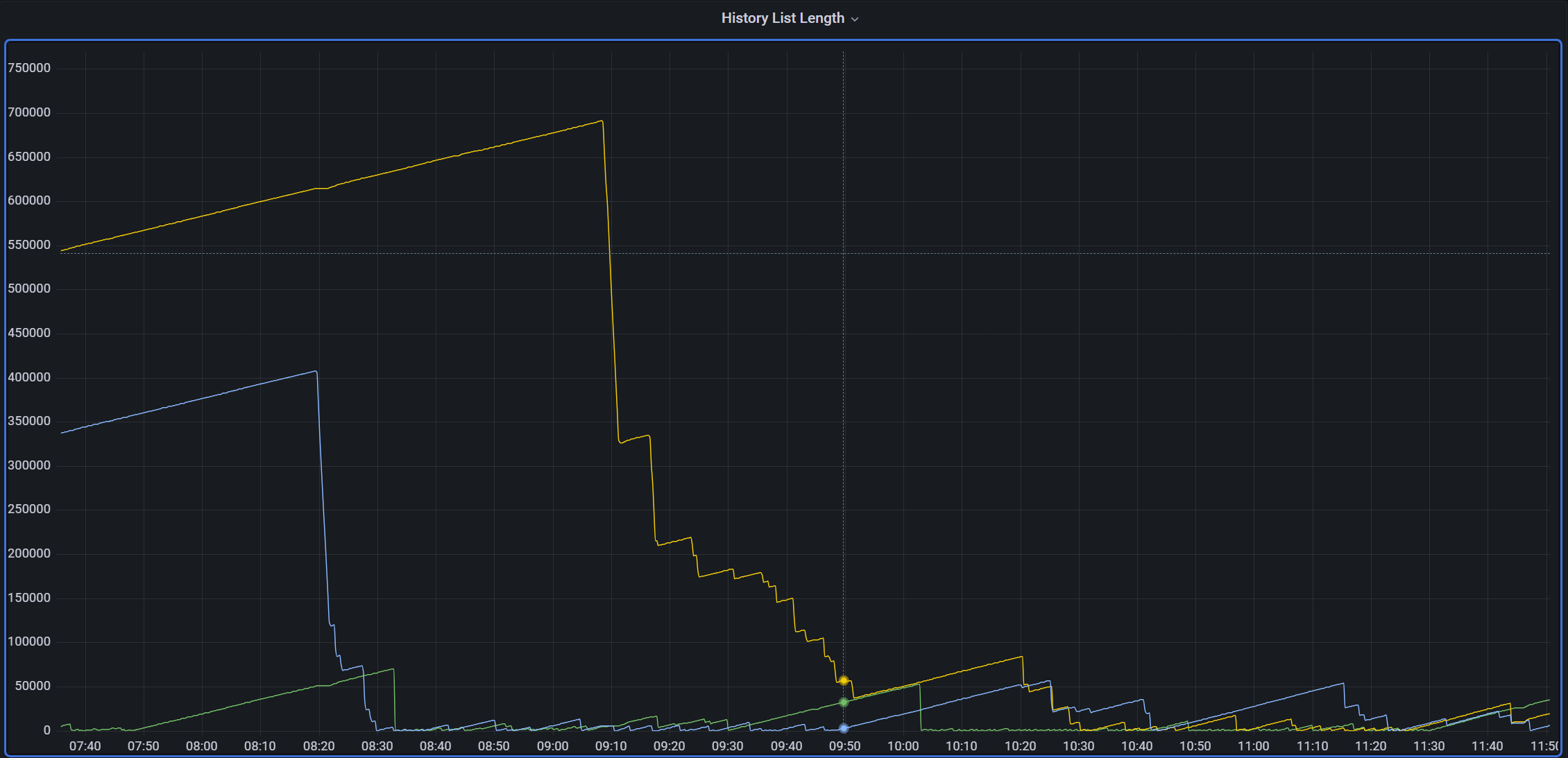
When this query completes, history list length is usually up in the 700,000+ range.
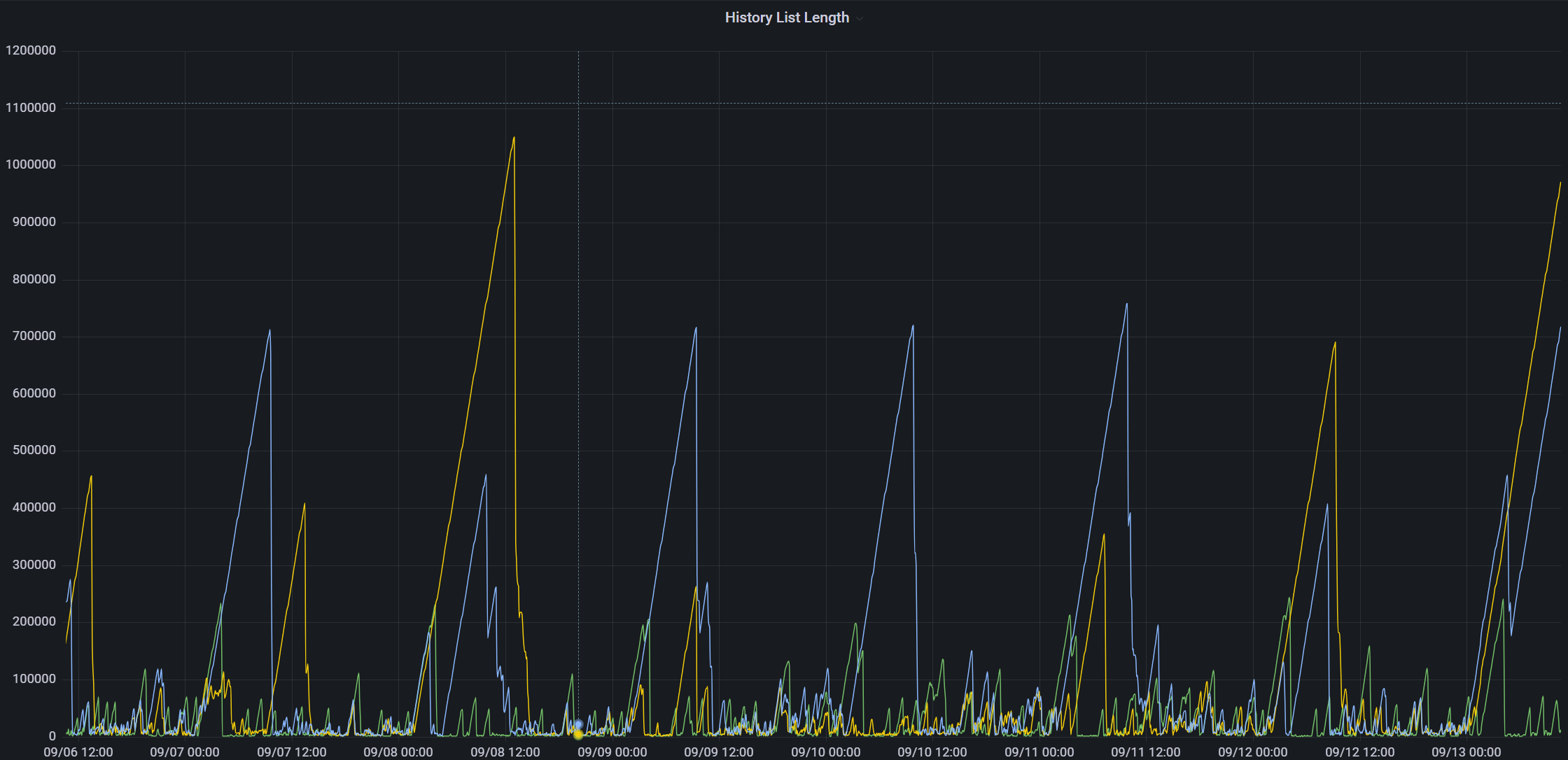
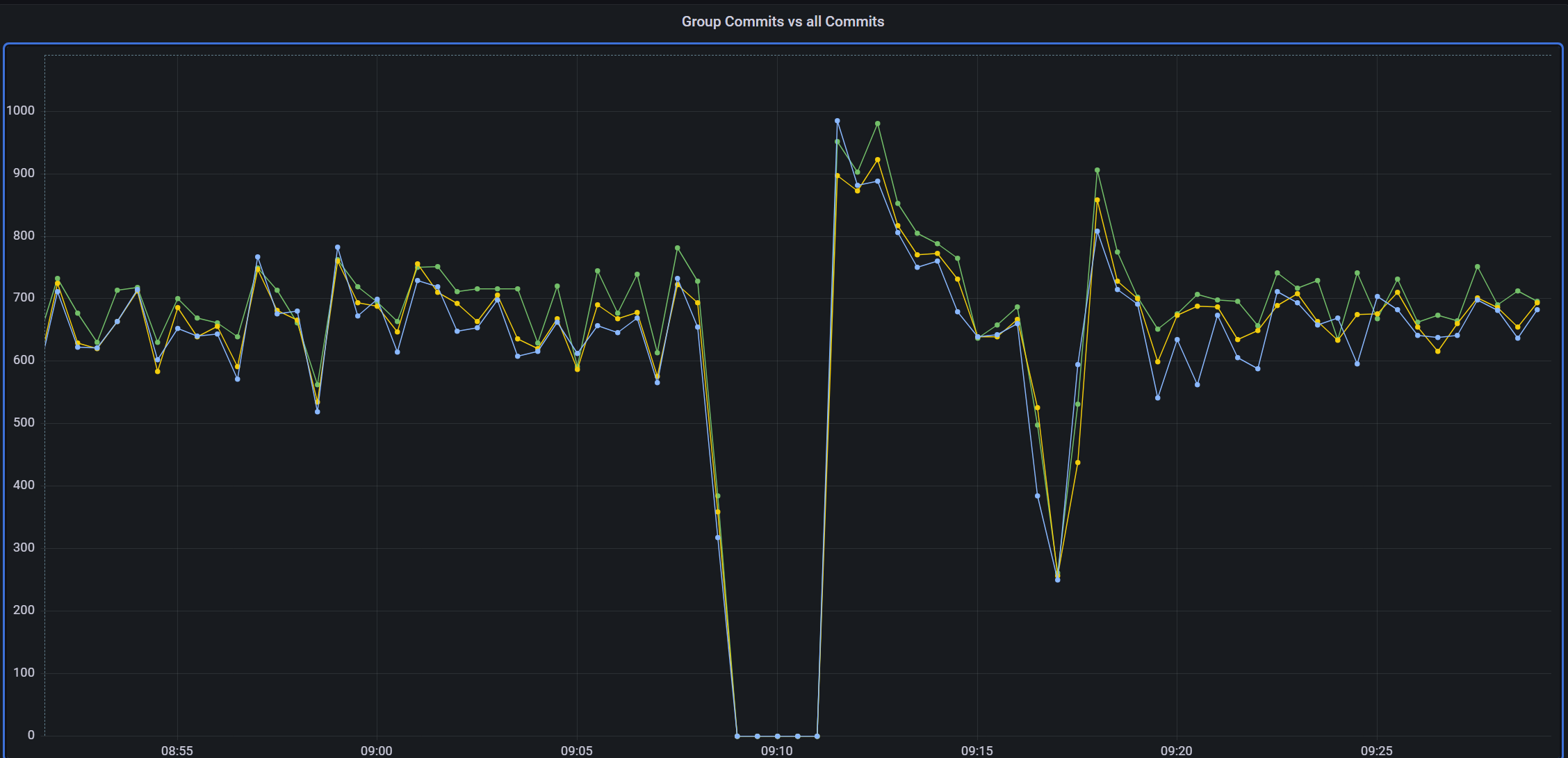
Some time after the query completes, the entire cluster stops processing transactions as the DB where this query was running stops everything it's doing while it's clearing out the undo data. It stops responding to anything so commits pile up on the writer node until the reader finishes:
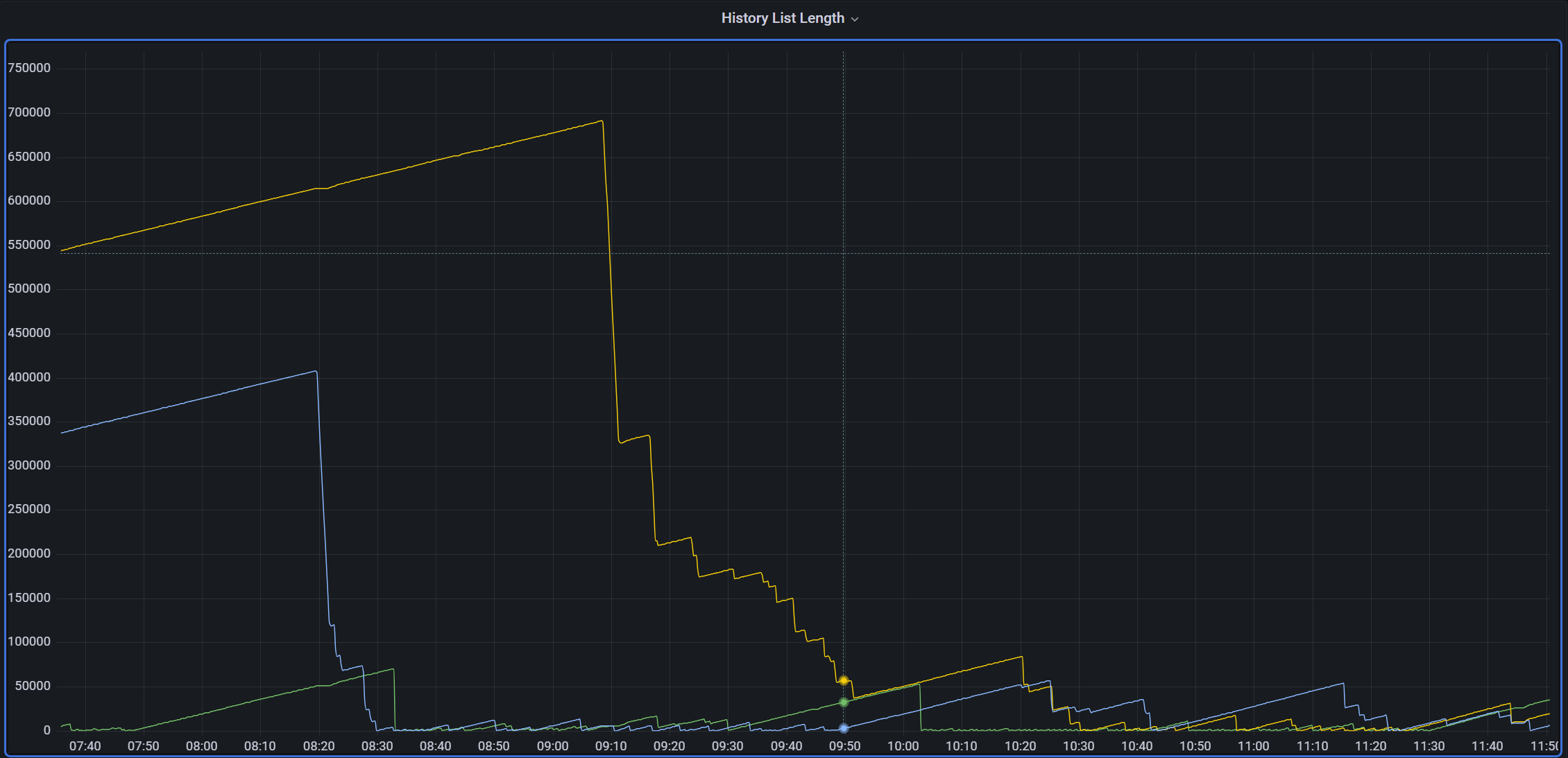
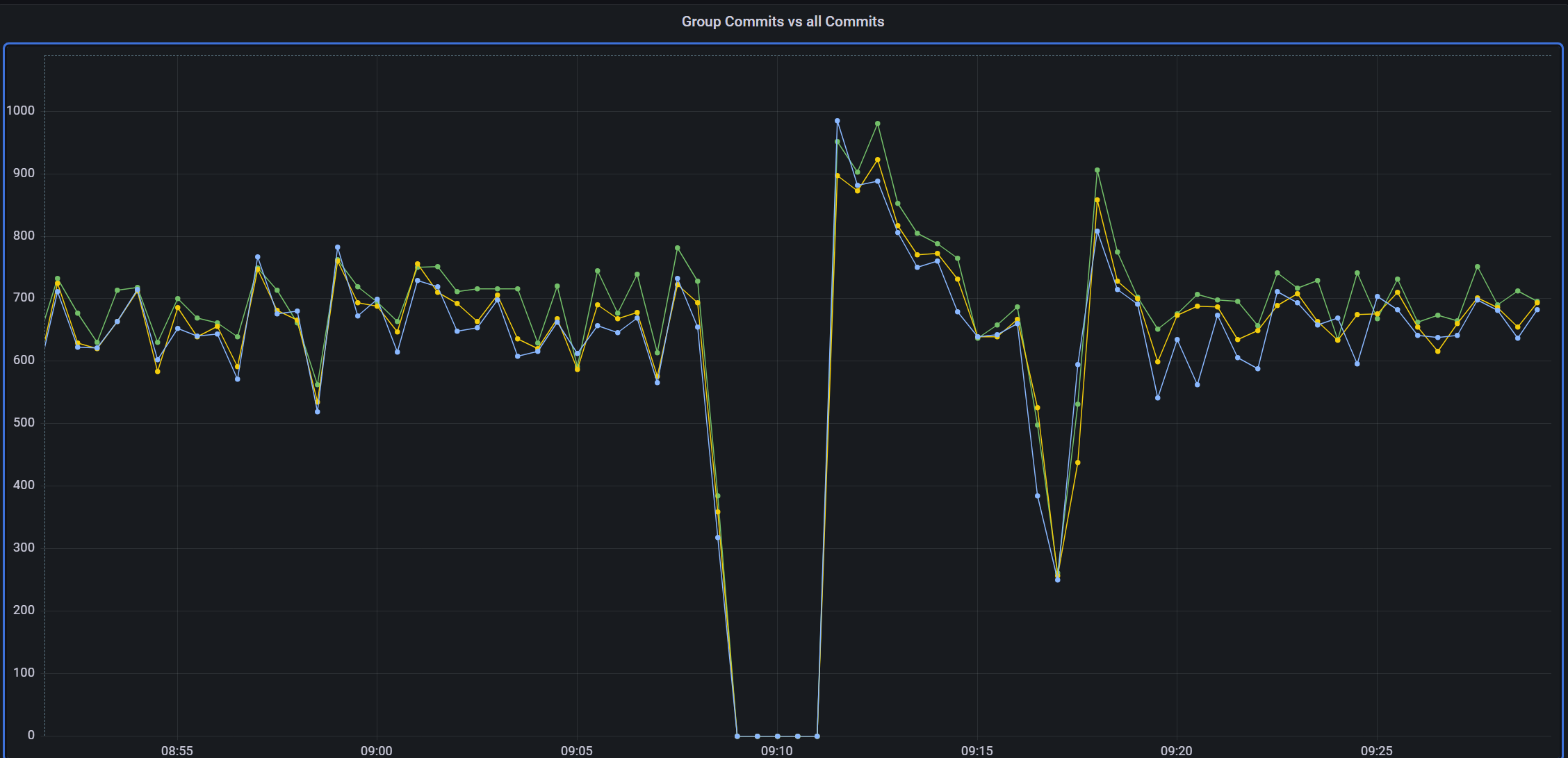
I've previously tinkered with the InnoDB purge settings but to no real effect.
I know there are changes in later 10.6 versions related to undo retention in busy databases, but I'm not clear on whether they would have any impact on this.