Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
10.11.9
-
None
-
Debian 12 Bookworm
Description
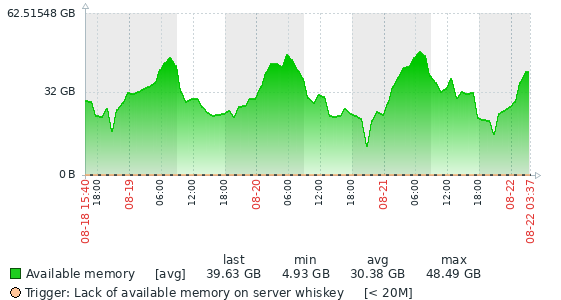
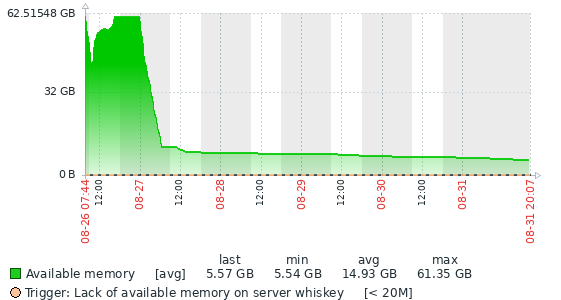
We run a pretty large database (about 5.5TB currently), and we were running into issues with the growing history list length that was well known under 10.11.6.
We upgraded to 10.11.9 (10.11.8 first on some servers), and we immediately noticed that the memory usage was wildly different. 10.11.6 seemed very good at freeing memory, and it was great to see an accurate representation of how many resources the servers are actually using.
With 10.11.9, you can see that the graph does a reverse hockey stick. It maximizes allocated memory based on innodb_buffer_pool_size, and then stays occupied, hardly fluctuating.
We had seen this same kind of usage in MariaDB 10.3 and 10.6, so it was really nice when earlier 10.11 had what looked like much more robust memory handling. We wouldn't have a big problem with it except that one of our replicas unexpectedly OOMed over the weekend.
So, what changed from 10.11.6 to 10.11.8? Is there a way to set more aggressive memory management?
Attachments
Issue Links
- blocks
-
MDEV-36197 Implement Buffer Pool Auto-Scaling Based on RAM Availability
-

- Open
-
- is part of
-
MDEV-29445 reorganise innodb buffer pool (and remove buffer pool chunks)
-
- Closed
-
- relates to
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
