Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Fixed
-
10.6.18, 10.11.8, 11.0.6, 11.2.4, 11.1.5, 11.4.2
Description
I'm benchmarking 10.4 vs 10.11, using sysbench, and oltp_update_index.
It is a rather large benchmark, with about 23GB data , which is run with
sysbench --db-driver=mysql --range-size=100 --table-size=5000000 --tables=8 --threads=16 --events=0 --warmup-time=5 --time=600 oltp_update_index --rand-type=uniform
I run it "cold", i,e with slow shutdown after the load, and without bufferpool loading, i.e
innodb_fast_shutdown=0
|
innodb_buffer_pool_load_at_startup=OFF
|
innodb_buffer_pool_dump_at_shutdown=OFF
|
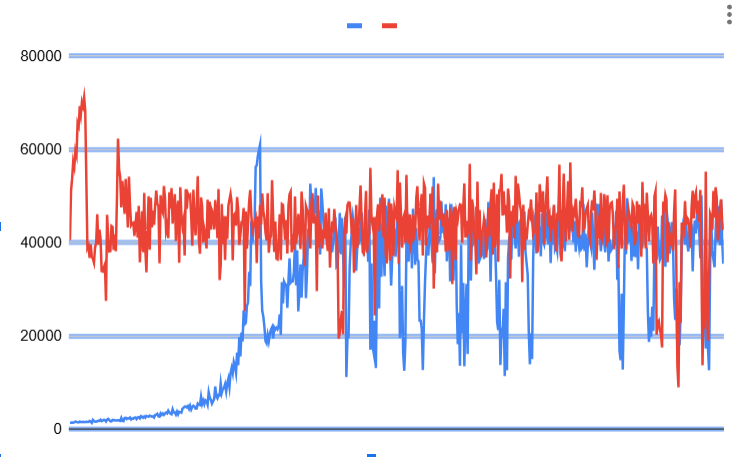
One thing I noticed, is a very slow warmup
compared 10.4, where it starts at about 40K tps, 10.11 starts at 2K tps, and reaches normal speed ~40-50K tps only after about 140 seconds. mysqld reads from SSD at 80MB/s in 10.4 at that time, and 8-10 times less in 10.11
Note, this is still mostly in-memory benchmark, the buffer pool is large enough.
I noticed a particular stack, that comes often during warmup, but not after, which I would attribute to that slowness.
NtDelayExecution
|
RtlDelayExecution
|
SleepEx
|
std::this_thread::sleep_until<std::chrono::steady_clock,std::chrono::duration<__int64,std::ratio<1,1000000000> > >
|
std::this_thread::sleep_for
|
buf_page_get_low
|
btr_latch_prev
|
btr_cur_t::search_leaf row_ins_sec_index_entry_low
|
row_ins_sec_index_entry
|
row_upd_sec_index_entry
|
row_upd_sec_step row_upd row_upd_step
|
row_update_for_mysql
|
ha_innobase::update_row
|
handler::ha_update_row
|
mysql_update
|
mysql_execute_command
|
Prepared_statement::execute
|
Prepared_statement::execute_loop
|
mysql_stmt_execute_common
|
mysqld_stmt_execute
|
dispatch_command
|
do_command
|
....
|
Note, that Windows' Sleep can't be less that 1ms, and by default, they would still amount to 14ms or something like that.
According to Marko, this sleeping is due to MDEV-33543, something change buffer, and it is not needed in 11.x anymore.
UPD: If I revert 90b95c6149c72f43aa2324353a76f370d018a5ac (MDEV-33543), there is no warmup, performance is much better
Attachments
Issue Links
- is caused by
-
-

- Closed
-
- relates to
-
-
- Closed
-
