Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Incomplete
-
10.10.2
-
None
-
None
-
Ubuntu 22.04
Description
Hi experts,
we are facing regularly (at least once a week, today 3 times) an outage in our 5 node cluster (+1 additional node for backup tasks).
In every case one of the nodes is staying at this point:
MariaDB [(none)]> show processlist;
|
+--------+-------------+--------------------+---------------------------------+---------+-------+----------------------------------------------------------+------------------------------------------------------------------------------------------------------+----------+
|
| Id | User | Host | db | Command | Time | State | Info | Progress |
|
+--------+-------------+--------------------+---------------------------------+---------+-------+----------------------------------------------------------+------------------------------------------------------------------------------------------------------+----------+
|
| 1 | system user | | NULL | Sleep | 85248 | wsrep aborter idle | NULL | 0.000 |
|
| 2 | system user | | **** | Sleep | 0 | Update_rows_log_event::find_row(46124856) on table `ocr` | UPDATE ocr SET ascii='7jgoqHVSDCCQfQt/17uwcDkwcjq428o5yt+adtVkQtUvbGI5vNN3F7T9OMFD5Td7TS9RW00gbJU/It | 0.000 |
|
| 6 | system user | | NULL | Sleep | 1 | wsrep applier committed | NULL | 0.000 |
|
| 5 | system user | | NULL | Sleep | 1 | wsrep applier committed | NULL | 0.000 |
|
| 7 | system user | | NULL | Sleep | 4 | wsrep applier committed | NULL | 0.000 |
|
| 9 | system user | | NULL | Sleep | 0 | wsrep applier committed | NULL | 0.000 |
|
| 8 | system user | | NULL | Sleep | 0 | wsrep applier committed | NULL | 0.000 |
|
| 13 | system user | | NULL | Sleep | 0 | wsrep applier committed | NULL | 0.000 |
|
| 11 | system user | | NULL | Sleep | 1 | wsrep applier committed | NULL | 0.000 |
|
| 12 | system user | | NULL | Sleep | 1 | wsrep applier committed | NULL | 0.000 |
|
| 15 | system user | | NULL | Sleep | 0 | wsrep applier committed | NULL | 0.000 |
|
| 14 | system user | | NULL | Sleep | 1 | wsrep applier committed | NULL | 0.000 |
|
| 16 | system user | | NULL | Sleep | 1 | wsrep applier committed | NULL
|
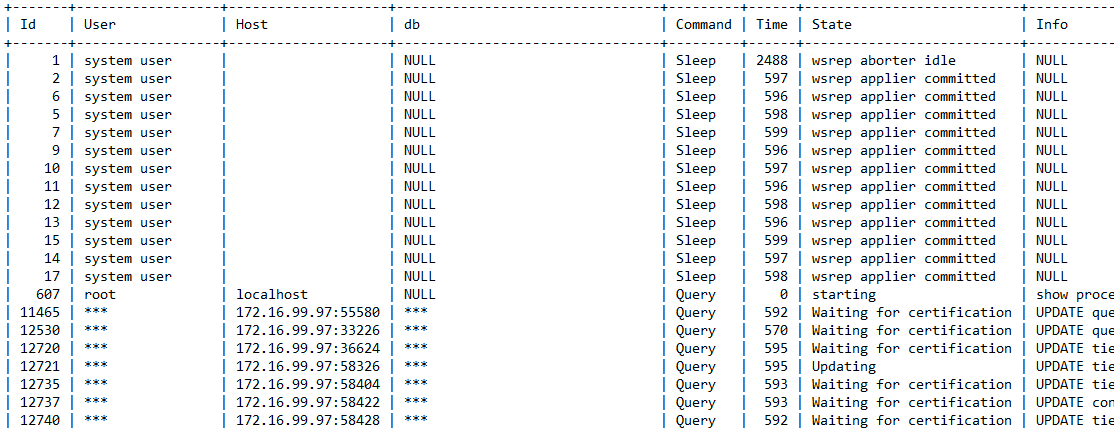
All other queries are staying then in Updating or Waiting for certification state (see screenshot attachment).
Every time we need to find out which node has the Update_rows_log_event hanging and then restart that VM. Stopping the database service almost everytime will not work. Often we have to reboot the VM. After that all other nodes will work normaly and after restarted the affected node is syncing again.
But we are losing the queued queries on that machine.
I think this happened while there is many traffic on the different nodes.
But it is an assumption.
Are there any hint how we can find out what is happening? How can we examine ?
We cannot find any hint in journalctl. How can we proceed ?
Regards
Marc
Attachments
Issue Links
- relates to
-
-
- Closed
-