Details
Description
In an environment running Galera Cluster with 6 MariaDB nodes, 1 arbitrator node, some replicas and a ProxySQL, after a network issue that triggered a state transfer on two nodes,
for some reason, almost all the transactions hang in:
- “starting” state on the commit statement or on "".
- "acquiring total order isolation" on the "KILL CONNECTION" statement (The "KILL CONNECTION" was requested by the ProxySQL)
We tried to restart the service but it hangs on stopping, ProxySQL detected this node as down and switched the traffic to another node.
By looking at the backtrace it seems that we have a kind of "pthread_cond_wait() deadlock" executed by lock.wait() on the enter() function on the commit monitor during the commit order critical section.
Unfortunately, we didn't find a way to reproduce the problem
Attachments

Issue Links
- blocks
-
MDEV-30963 Assertion failure !lock.was_chosen_as_deadlock_victim in trx0trx.h:1065
-

- Closed
-
- causes
-
-

- Closed
-
-
-
- Closed
-
- includes
-
-
- Closed
-
- relates to
-
-
- Closed
-
-
-
- Open
-
Activity
i am seeing this in my cluster as well. There will be a system user that stuck in state "committing".
Why it could led to a galera cluster getting stuck/hung?
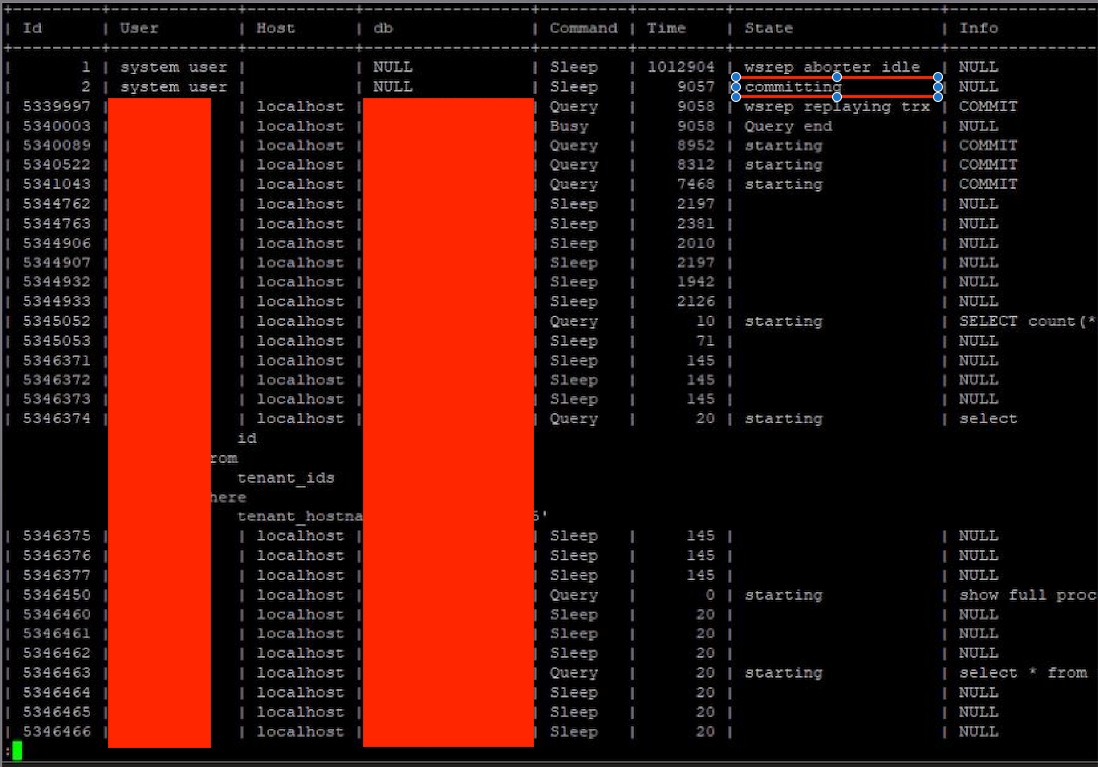
Probably a similar hang was reproduced by using conflicting sysbench load and DDL (TOI mode replication), no ProxySQL involved in the test scenario.
We can now reliably reproduce cluster hang, which is due to a deadlock between KILL CONNECTION execution and replication applier performing victim abort (for the connection which is target for the KILL command). However, stack traces of this hang are different than the stack traces attached in this MDEV. If the attached stack traces were recorded when the problem has not yet started, then we have matching problems.
Anyway, we are preparing a fix and test case for the problem now discovered. It also turns out that the KILL CONNECTION issue should not happen with 10.6 and later, as KILL execution has been refactored after 10.5
Review cycle and related fixes are still ongoing. The pull request and reviews for the PR can be tracked here: https://github.com/codership/mariadb-server/pull/293
@seppo, can this happen on 10.6.5 as well? My cluster is on 10.6.5
Pull request opened here https://jira.mariadb.org/browse/MDEV-29293.
I see that it has been previously claimed that this bug does not affect MariaDB Server 10.6 or later. Please clarify what should be done on merge to 10.6. If it is anything else than a null-merge (discarding the changes), we need to review and test the 10.6 version as well.
Am I right that this is basically yet another attempt at fixing MDEV-23328?
These changes seem to cause the test perfschema.nesting to fail.
I reviewed the InnoDB changes of the 10.6 version of this (PR#2609), and I think that there is some room for race conditions.
Latest version of PR fixes Marko's review comments and test failure. But Marko reviewed only 10.6 and InnoDB changes so review on sql-layer is needed.
Fix merged with head revision:
https://github.com/MariaDB/server/commit/6966d7fe4b7ccfb2b7d16ca4d7d5ab08234fa9ec
https://github.com/MariaDB/server/commit/3f59bbeeaec751e9aabdc544324546f3c8326f0f
https://github.com/MariaDB/server/commit/f307160218f8f9ed2528ffc685f49c4e2ae050b3
I have just came across this issue when trying to move a DB cluster from a percona cluster into a MariaDB using logical backups.
After a while of the applications running I ended up with hundreds of processes, which were stuck in starting commit state attached is a redacted sample of the process list process-list-sample.txt .
.
I have restarted the cluster and enabled wsrep debug, to try and get some additional information, as to what is happening when it locks up into this state.
Version information is:
OS: Debian 11
Kernel: 5.10.0-16-amd64 #1 SMP Debian 5.10.127-1
MariaDB: 10.5.15-0+deb11u1
Galera: 26.4.11-0+deb11u1