Details
-
Bug
-
Status: Stalled (View Workflow)
-
 Minor
Minor
-
Resolution: Unresolved
-
10.6.7
Description
Update 2025-12-15: We have been unsuccessful to reproduce this issue; however, Andrei thinks there is an improvement to be made to the error message. So the JIRA now tracks just updating the error message.
While testing MDEV-21117, often time hit the following error while old_master got stuck at being demoted as new_slave when old_slave got promoted to new_master.
*new_master(old_slave) error log
2022-04-25 15:03:26 0 [Note] /usr/sbin/mariadbd: ready for connections. |
Version: '10.6.7-3-MariaDB-enterprise-log' socket: '/var/lib/mysql/mysql.sock' port: 3306 MariaDB Enterprise Server |
2022-04-25 15:03:26 0 [Note] InnoDB: Buffer pool(s) load completed at 220425 15:03:26 |
2022-04-25 15:03:30 24 [Warning] Aborted connection 24 to db: 'unconnected' user: 'maxscale' host: '192.168.254.26' (Got timeout reading communication packets) |
2022-04-25 15:03:33 28 [Warning] Aborted connection 28 to db: 'unconnected' user: 'maxscale' host: '192.168.254.26' (Got timeout reading communication packets) |
2022-04-25 15:03:36 23 [Warning] Timeout waiting for reply of binlog (file: mariadb-bin.000010, pos: 461), semi-sync up to file , position 0. |
2022-04-25 15:03:36 23 [Note] Semi-sync replication switched OFF. |
2022-04-25 15:04:24 6 [ERROR] Error reading packet from server: Lost connection to server during query (server_errno=2013) |
2022-04-25 15:04:24 6 [Note] Slave I/O thread: Failed reading log event, reconnecting to retry, log 'mariadb-bin.000002' at position 23973467; GTID position '0-1-1036936' |
2022-04-25 15:04:24 6 [ERROR] Slave I/O: error reconnecting to master 'repl@192.168.254.24:3306' - retry-time: 60 maximum-retries: 100000 message: Can't connect to server on '192.168.254.24' (111 "Connection refused"), Internal MariaDB error code: 2003 |
2022-04-25 15:05:24 6 [Note] Slave: connected to master 'repl@192.168.254.24:3306',replication resumed in log 'mariadb-bin.000002' at position 23973467 |
2022-04-25 15:06:05 6 [ERROR] Error reading packet from server: Lost connection to server during query (server_errno=2013) |
2022-04-25 15:06:05 6 [Note] Slave I/O thread: Failed reading log event, reconnecting to retry, log 'mariadb-bin.000003' at position 29316013; GTID position '0-1-1096941' |
2022-04-25 15:06:05 6 [ERROR] Slave I/O: error reconnecting to master 'repl@192.168.254.24:3306' - retry-time: 60 maximum-retries: 100000 message: Can't connect to server on '192.168.254.24' (111 "Connection refused"), Internal MariaDB error code: 2003 |
2022-04-25 15:06:11 7 [Note] Error reading relay log event: slave SQL thread was killed |
2022-04-25 15:06:11 7 [Note] Slave SQL thread exiting, replication stopped in log 'mariadb-bin.000003' at position 29316013; GTID position '0-1-1096941', master: 192.168.254.24:3306 |
2022-04-25 15:06:11 6 [Note] Slave I/O thread killed during or after a reconnect done to recover from failed read |
2022-04-25 15:06:11 6 [Note] Slave I/O thread exiting, read up to log 'mariadb-bin.000003', position 29316013; GTID position 0-1-1096941, master 192.168.254.24:3306 |
2022-04-25 15:06:11 6 [Note] cannot connect to master to kill slave io_thread's connection |
2022-04-25 15:06:11 33 [Note] Deleted Master_info file '/var/lib/mysql/master.info'. |
2022-04-25 15:06:11 33 [Note] Deleted Master_info file '/var/lib/mysql/relay-log.info'. |
2022-04-25 15:06:12 3312 [Note] Start binlog_dump to slave_server(1), pos(, 4), using_gtid(1), gtid('0-1-1096912') |
|
*new_slave(old_master) error log
2022-04-25 15:06:12 0 [Note] Successfully truncated binlog file:./mariadb-bin.000003 from previous file size 29319436 to pos:29301832 to remove transactions starting from GTID 0-1-1096913 |
2022-04-25 15:06:12 0 [Note] Server socket created on IP: '0.0.0.0'. |
2022-04-25 15:06:12 0 [Warning] 'proxies_priv' entry '@% root@node1' ignored in --skip-name-resolve mode. |
2022-04-25 15:06:12 0 [Note] /usr/sbin/mariadbd: ready for connections. |
Version: '10.6.7-3-MariaDB-enterprise-log' socket: '/var/lib/mysql/mysql.sock' port: 3306 MariaDB Enterprise Server |
2022-04-25 15:06:12 5 [Note] Master connection name: '' Master_info_file: 'master.info' Relay_info_file: 'relay-log.info' |
2022-04-25 15:06:12 5 [Note] 'CHANGE MASTER TO executed'. Previous state master_host='', master_port='3306', master_log_file='', master_log_pos='4'. New state master_host='192.168.254.25', master_port='3306', master_log_file='', master_log_pos='4'. |
2022-04-25 15:06:12 5 [Note] Previous Using_Gtid=No. New Using_Gtid=Current_Pos |
2022-04-25 15:06:12 6 [Note] Slave I/O thread: Start semi-sync replication to master 'repl@192.168.254.25:3306' in log '' at position 4 |
2022-04-25 15:06:12 6 [Note] Slave I/O thread: connected to master 'repl@192.168.254.25:3306',replication starts at GTID position '0-1-1096912' |
2022-04-25 15:06:12 7 [Note] Slave SQL thread initialized, starting replication in log 'FIRST' at position 4, relay log './mariadb-relay-bin.000001' position: 4; GTID position '0-1-1096912' |
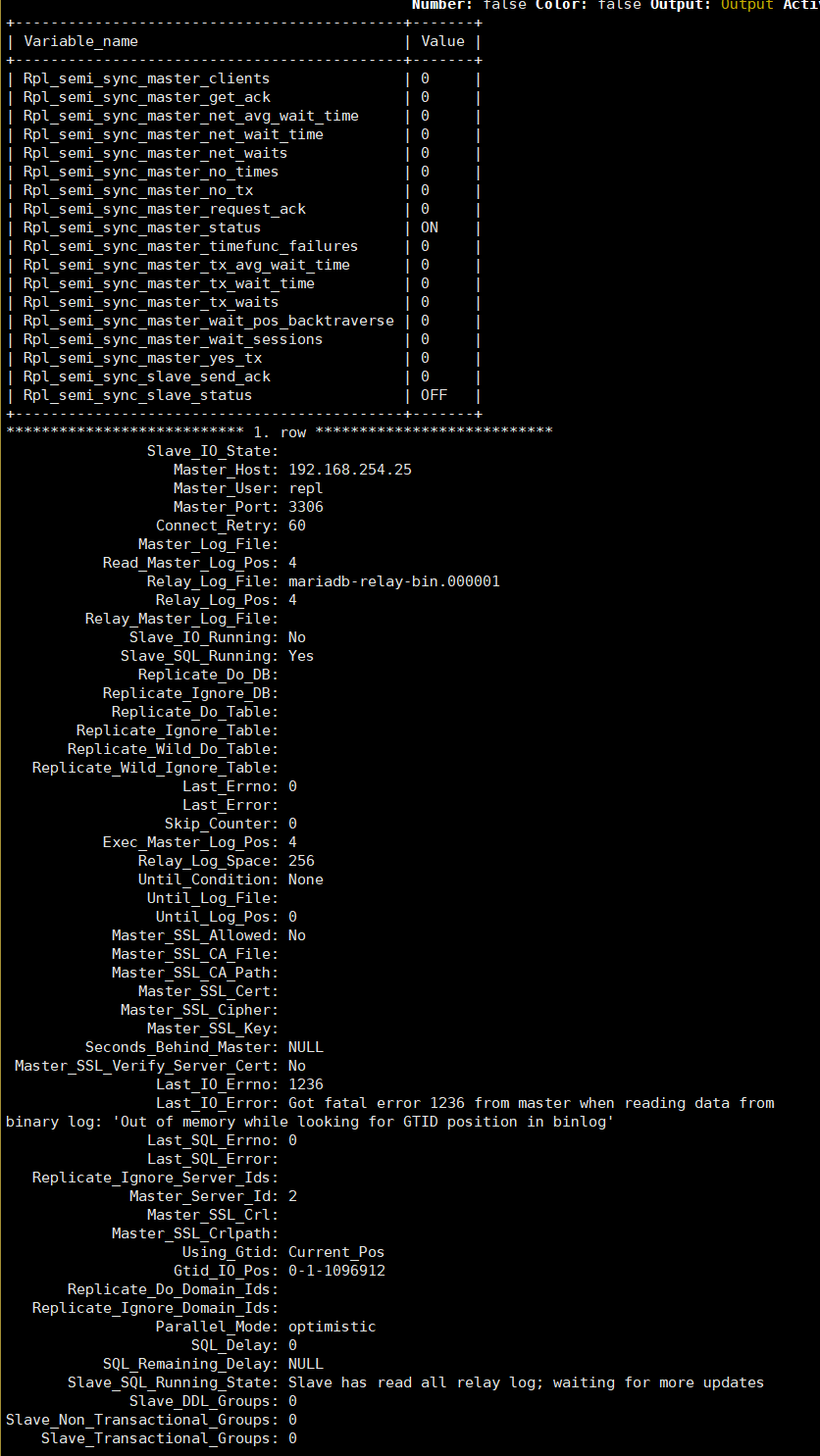
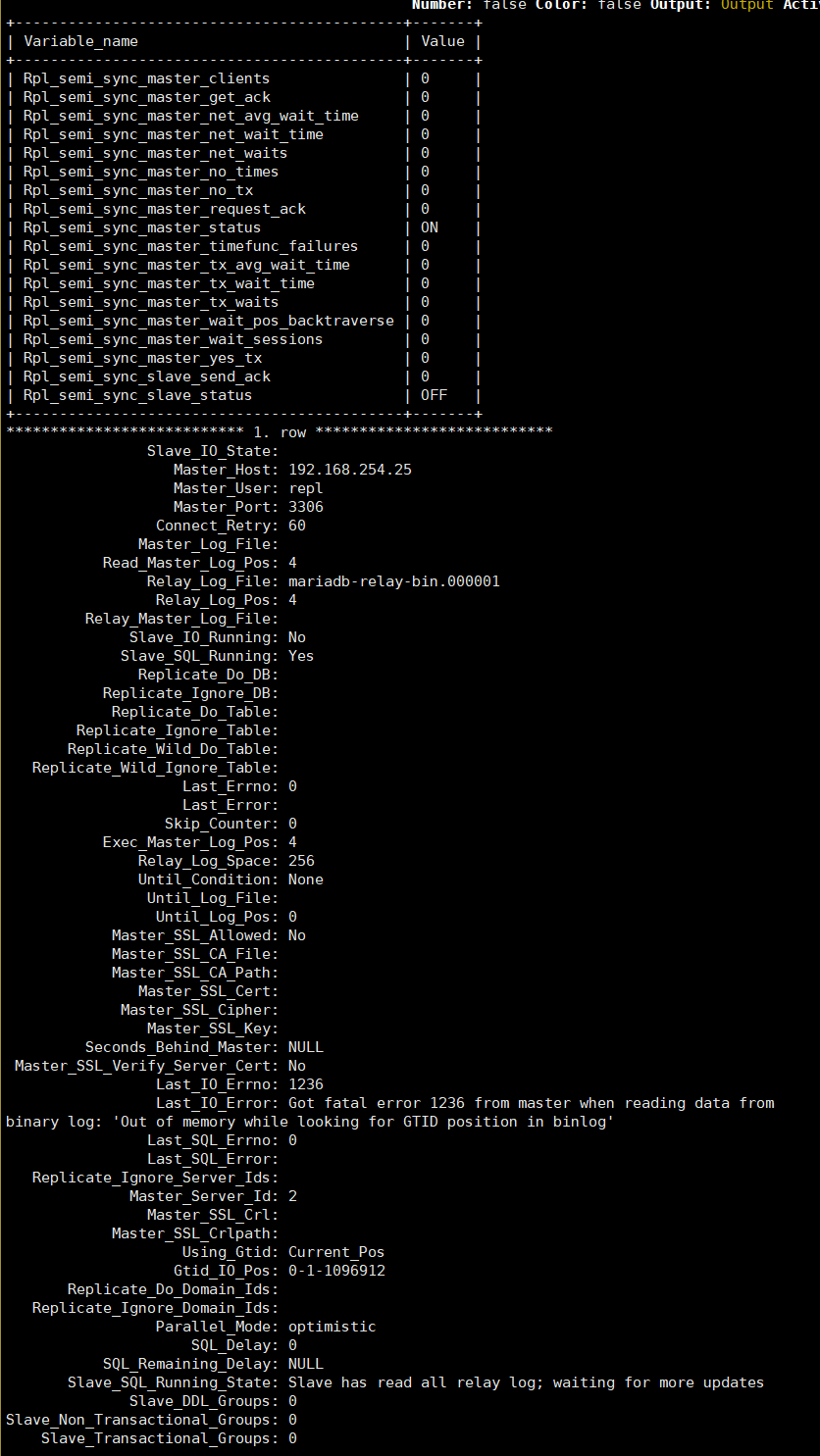
2022-04-25 15:06:12 6 [ERROR] Error reading packet from server: Out of memory while looking for GTID position in binlog (server_errno=1236) |
2022-04-25 15:06:12 6 [ERROR] Slave I/O: Got fatal error 1236 from master when reading data from binary log: 'Out of memory while looking for GTID position in binlog', Internal MariaDB error code: 1236 |
2022-04-25 15:06:12 6 [Note] Slave I/O thread exiting, read up to log 'FIRST', position 4; GTID position 0-1-1096912, master 192.168.254.25:3306 |
At this point, maxscale server list shows as:
┌─────────┬────────────────┬──────┬─────────────┬─────────────────┬─────────────┐
|
│ Server │ Address │ Port │ Connections │ State │ GTID │
|
├─────────┼────────────────┼──────┼─────────────┼─────────────────┼─────────────┤
|
│ primary │ 192.168.254.24 │ 3306 │ 0 │ Running │ 0-1-1096912 │ |
├─────────┼────────────────┼──────┼─────────────┼─────────────────┼─────────────┤
|
│ replica │ 192.168.254.25 │ 3306 │ 100 │ Master, Running │ 0-2-1302231 │ |
└─────────┴────────────────┴──────┴─────────────┴─────────────────┴─────────────┘
|
- slave status and rpl_semi_sync_% status -
*master/slave_config
[mariadb]
|
bind_address = 0.0.0.0 |
log_bin = mariadb-bin.log
|
server_id = 2 |
log_basename = mariadb
|
binlog_format = ROW
|
log_slave_updates = ON
|
skip_name_resolve = ON
|
|
log_error
|
slow_query_log
|
long_query_time=1 |
log_warnings=2 |
|
rpl_semi_sync_master_enabled=ON
|
rpl_semi_sync_master_timeout=1000000 |
rpl_semi_sync_master_wait_point=AFTER_SYNC
|
|
rpl_semi_sync_slave_enabled=ON
|
|
innodb-flush-log-at-trx-commit=2 |
sync-binlog=1 |
relay-log-purge=1 |
relay-log-recovery=1 |
innodb_rollback_on_timeout = ON
|
max_connections = 3000 |
|
slave_parallel_threads = 16 |
slave_parallel_workers = 16 |
gtid_strict_mode = ON
|
rpl_semi_sync_slave_enabled = ON
|
rpl_semi_sync_master_timeout=10000 |
|
innodb_autoinc_lock_mode=2 |
innodb_flush_method = O_DIRECT
|
innodb_lock_wait_timeout = 3 |
innodb_print_all_deadlocks = ON
|
performance_schema = ON
|
shutdown_wait_for_slaves = ON
|
slave_parallel_max_queued = 134217728 |
table_definition_cache = 15000 |
table_open_cache = 15000 |
thread_pool_size=64 |
wait_timeout=310 |
general_log = on
|