Details
-
Bug
-
Status: Closed (View Workflow)
-
 Blocker
Blocker
-
Resolution: Fixed
-
N/A
Description
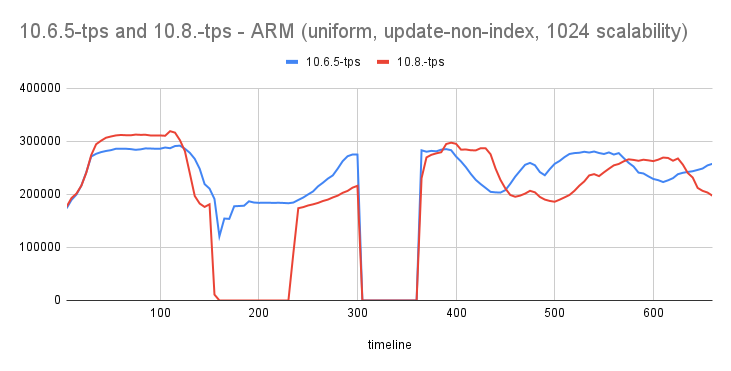
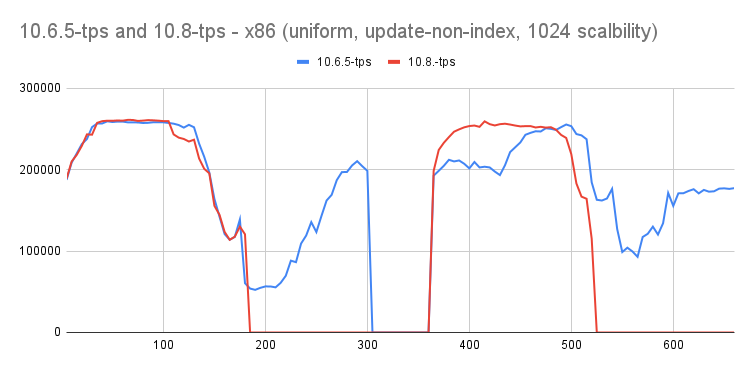
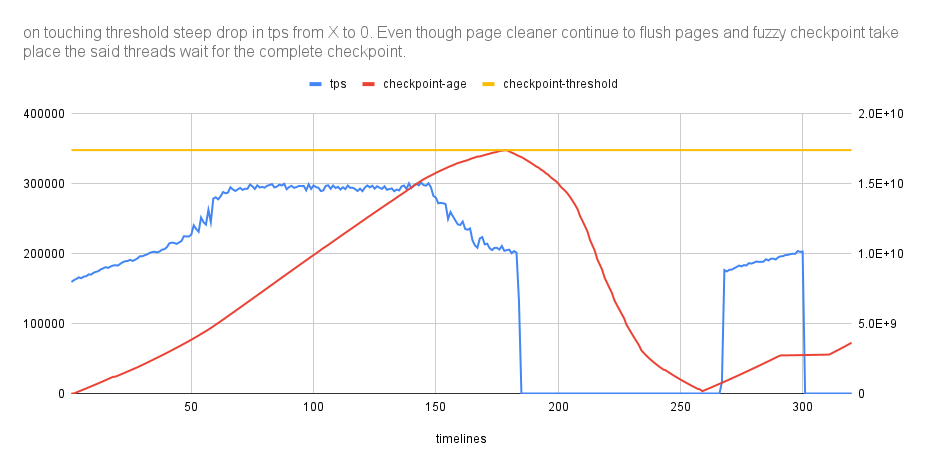
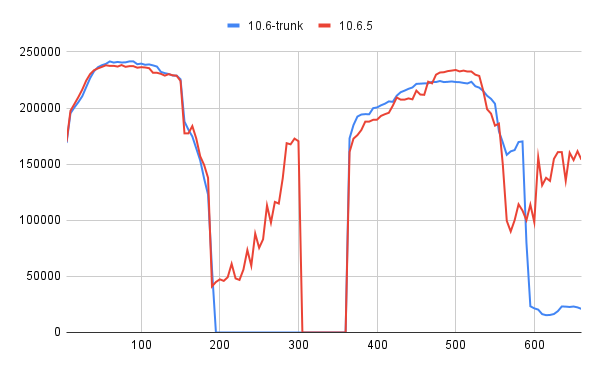
- while benchmarking 10.8 (#4b14874c2809a8b0f2d04a969132e062fb22b145) work-in-progress release I observed there is a regression with update-non-index, uniform workload (1024 scalability).
- tps often drops to 0.
Attachments

Issue Links
- is caused by
-
-

- Closed
-
