Details
-
Bug
-
Status: Closed (View Workflow)
-
 Major
Major
-
Resolution: Fixed
-
10.5(EOL), 10.6
Description
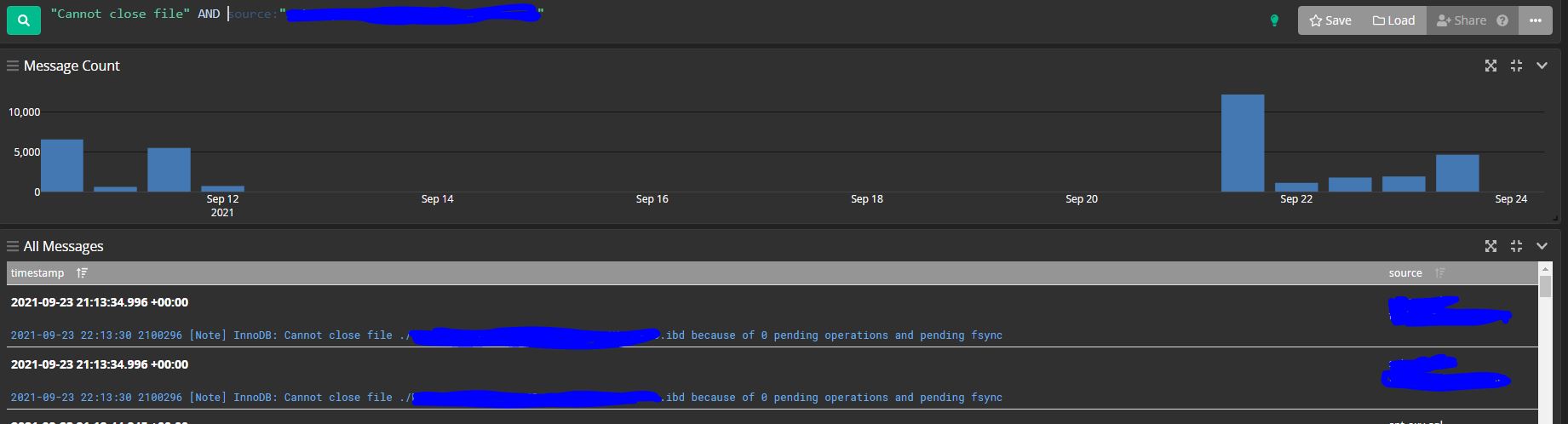
Within ~1 min test on current 10.6 with default log_warnings level I'm getting in the error log ~8500 records like this:
2021-03-22 2:58:35 8 [Note] InnoDB: Cannot close file ./test/FTS_00000000000012c8_00000000000015f9_INDEX_1.ibd because of 0 pending operations and pending fsync
|
2021-03-22 2:58:35 8 [Note] InnoDB: Cannot close file ./test/FTS_00000000000012c8_00000000000015f9_INDEX_2.ibd because of 0 pending operations and pending fsync
|
2021-03-22 2:58:35 8 [Note] InnoDB: Cannot close file ./test/FTS_00000000000012c8_00000000000015f9_INDEX_4.ibd because of 0 pending operations and pending fsync
|
2021-03-22 2:58:35 8 [Note] InnoDB: Cannot close file ./test/FTS_00000000000012c8_00000000000015f9_INDEX_5.ibd because of 1 pending operations and pending fsync
|
2021-03-22 2:58:35 8 [Note] InnoDB: Cannot close file ./test/FTS_00000000000012c8_00000000000015f9_INDEX_6.ibd because of 0 pending operations and pending fsync
|
...
|
10.5 seems to produce only those with "0 pending operations", so there are less of them, but still, ~4000 in a few-minute test. And these ones (with zero) are especially confusing.
I think if these are real problems which a user needs to take care of, there should be warnings or errors (and given the persistence, maybe we are missing at least a debug assertion or something); and if these are just technical notifications, there shouldn't be so many of them.
Attachments


Issue Links
- is caused by
-
-
- Closed
-
- relates to
-
-
- Closed
-
-
-
- Open
-
-
-
- Closed
-
