Details
-
Bug
-
Status: Closed (View Workflow)
-
 Blocker
Blocker
-
Resolution: Fixed
-
10.5.9
-
None
-
[root@localhost~]# cat /etc/redhat-release
CentOS Linux release 7.8.2003 (Core)
[root@localhost~]# uname -r
4.14.105-19-0013
[root@localhost~]# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6126 CPU @ 2.60GHz
[root@localhost~]# free -g
total used free shared buff/cache available
Mem: 125 46 42 1 35 75
Swap: 3 0 3
The SSD device is Intel P4610 3.2TB and the database version is MariaDB 10.5.9 Community Edition[ root@localhost ~]# cat /etc/redhat-release CentOS Linux release 7.8.2003 (Core) [ root@localhost ~]# uname -r 4.14.105-19-0013 [ root@localhost ~]# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 48 On-line CPU(s) list: 0-47 Thread(s) per core: 2 Core(s) per socket: 12 Socket(s): 2 NUMA node(s): 2 Vendor ID: GenuineIntel CPU family: 6 Model: 85 Model name: Intel(R) Xeon(R) Gold 6126 CPU @ 2.60GHz [ root@localhost ~]# free -g total used free shared buff/cache available Mem: 125 46 42 1 35 75 Swap: 3 0 3 The SSD device is Intel P4610 3.2TB and the database version is MariaDB 10.5.9 Community Edition
Description
Repeat steps are as follows (100% reproducible) :
1. Run the Sysbench benchmark using either Intel P4610 or ScaleFlux CSD 2000 and set the logical sector to 4K (take Intel P4610 as an example below)
[root@localhost~]# isdct start -intelssd 0 -nvmeformat LBAFormat=1
[root@localhost~]# nvme list
Node SN Model Namespace Usage Format FW Rev
---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- --------
/dev/nvme0n1 PHLJ8230004W4P0DXX INTEL SSDPE2KX040XX 1 3.84 TB / 3.84 TB 4 KiB + 0 B VDV10131
2. Use the ext4 file system to format and mount the Intel P4610
[root@localhost~]# mkfs.ext4 /dev/nvme0n1
[root@localhost~]# mount /dev/nvme0n1 -o discard /data/nvme0n1
3. Use the binary tar package of MariaDB 10.5.9 to initialize the installation (steps are abbreviated). The configuration options are as follows
[client]
socket=/data/sfdv0n1/mariadb-10.5.9/mysql.sock
[mysqld_safe]
user=mysql
log_error=/data/sfdv0n1/mariadb-10.5.9/error.log
[mysqld]
socket=/data/sfdv0n1/mariadb-10.5.9/mysql.sock
datadir=/data/sfdv0n1/mariadb-10.5.9
basedir=/opt/app/mariadb-10.5.9
user=mysql
log_error=/data/sfdv0n1/mariadb-10.5.9/error.log
explicit_defaults_for_timestamp=1
innodb_page_size=16384
innodb_buffer_pool_size =32G
innodb_buffer_pool_instances=8
innodb_page_cleaners=8
innodb_log_file_size =8G
innodb_log_buffer_size = 128M
innodb_flush_log_at_trx_commit=1
innodb_thread_concurrency=0
innodb_open_files=100000
innodb_file_per_table=1
innodb_flush_method=O_DIRECT
innodb_change_buffering=all
innodb_adaptive_flushing=1
innodb_old_blocks_time=1000
innodb_use_native_aio=1
innodb_lock_wait_timeout=120
lock_wait_timeout=60
innodb_io_capacity_max = 100000
innodb_flush_neighbors = 0
innodb_log_write_ahead_size=8192
innodb_doublewrite=1
innodb_compression_algorithm=zlib
max_connections=65536
max_prepared_stmt_count=1048576
4. Running sysbench requires more than 20GB of data to be written to disk. The sysbench command looks like this
[root@localhost~]# sysbench --db-driver=mysql --time=900 --threads=16 --report-interval=1 --mysql-socket=/data/sfdv0n1/mariadb-10.5.9/mysql.sock --mysql-user=qbench --mysql-password=qbench --mysql-db=sysbench --tables=32 --table-size=20000000 oltp_read_write --db-ps-mode=disable --percentile=99 --mysql-ignore-errors=1062,1213 --mysql_storage_engine=innodb --create_table_options="page_compressed=1" --rand-type=uniform prepare
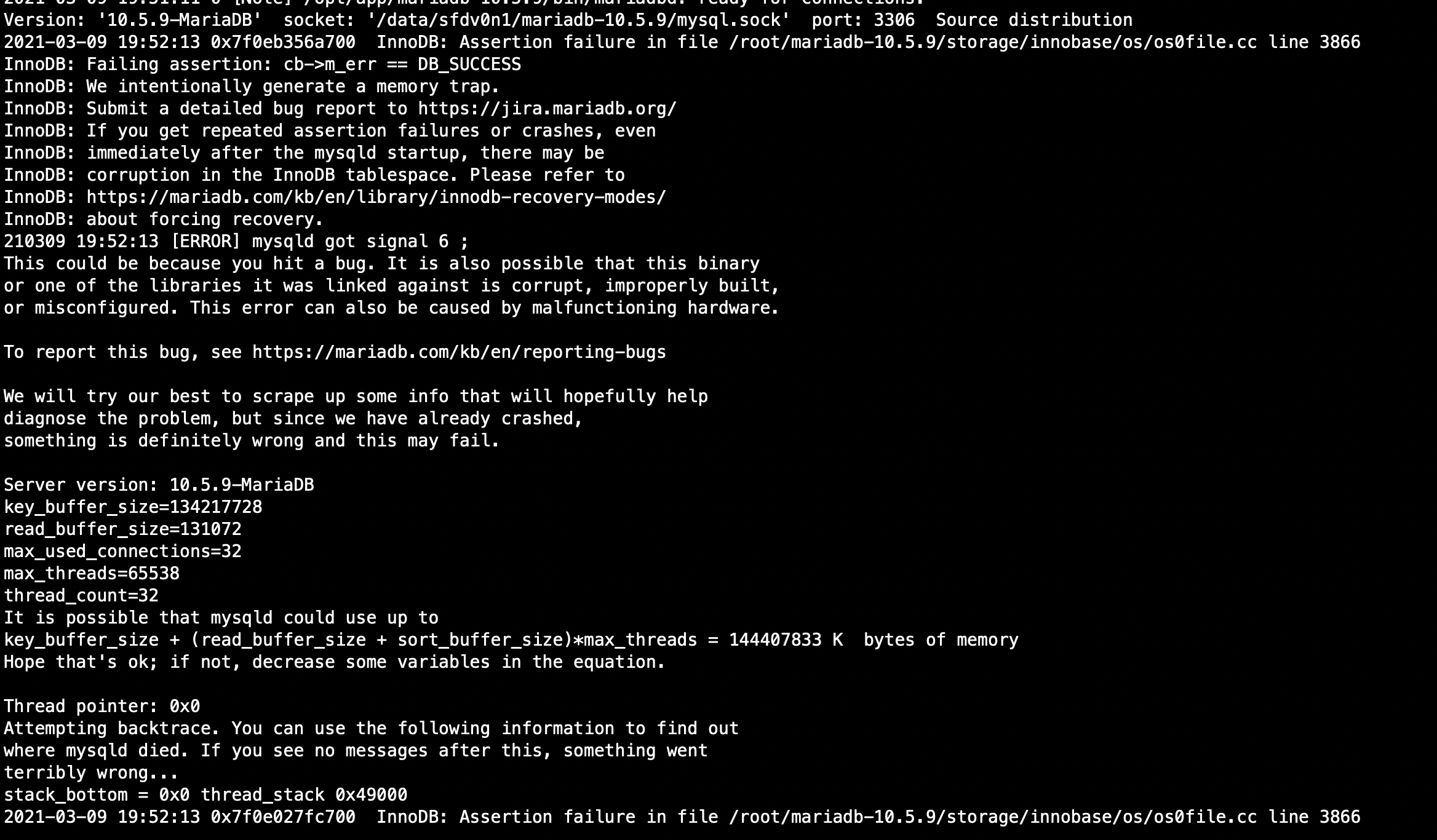
5. After a minute or so, the sysbench tells you that the connection is broken. If you look at the MariaDB error log, you can see a crash prompt similar to the one shown in the figure below
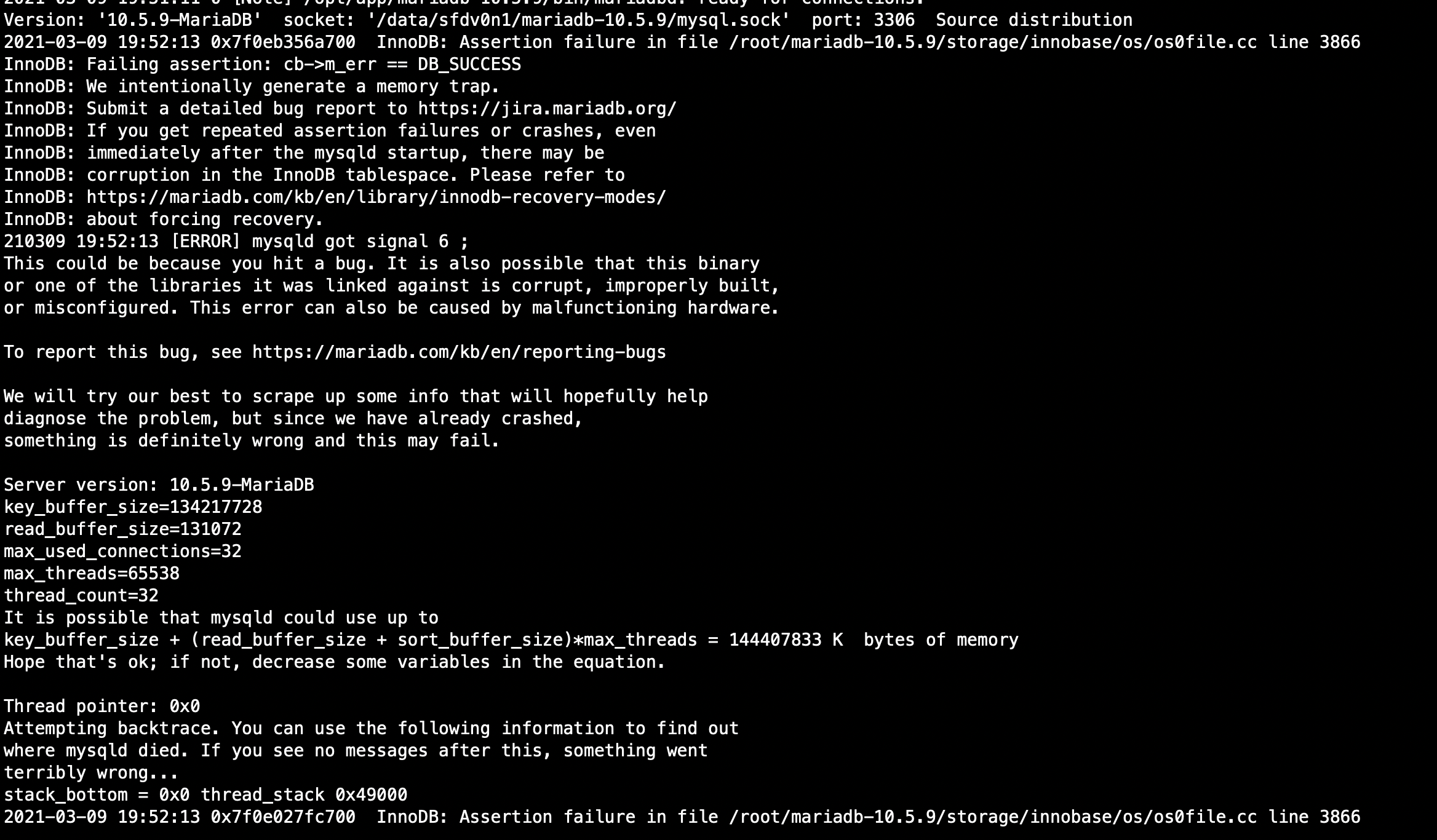
PS: if the logic of SSD equipment sector is set to 512 bytes, will not appear afore-mentioned crash phenomenon, we again in many different servers, once the logical sector is set to 4 k of SSD equipment, enabling the page compression would be a collapse of the Server process, and once the logic of SSD equipment sector is set to 512 bytes, enable page compression will not appear the phenomenon of Server process crashes, seems page compression of SSD equipment 4 k logical sector support not friendly enough?
Attachments
Issue Links
- relates to
-
-

- Closed
-
-
-
- Closed
-
-
-
- Closed
-
-
MDEV-16264 Implement a common work queue for InnoDB background tasks
-

- Closed
-
Activity
It occurred to me that my NVMe supports a 512-byte block size, so I would be unable to repeat the problem on my hardware:
sudo smartctl -a /dev/nvme0n1
|
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-4-amd64] (local build)
|
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
|
|
|
=== START OF INFORMATION SECTION ===
|
Model Number: INTEL SSDPED1D960GAY
|
Serial Number: …
|
Firmware Version: E2010435
|
PCI Vendor/Subsystem ID: 0x8086
|
IEEE OUI Identifier: 0x5cd2e4
|
Controller ID: 0
|
NVMe Version: <1.2
|
Number of Namespaces: 1
|
Namespace 1 Size/Capacity: 960 197 124 096 [960 GB]
|
Namespace 1 Formatted LBA Size: 512
|
…
|
It could be that all our test environments have SSDs with 512-byte sector size.
It might be easiest if you can provide remote access to a system where this could be debugged.
My attempts to configure a SATA SSD as well as my Intel NVMe drive to use 4096-byte sector size instead of 512-byte size failed. Apparently, the proprietary Intel tool isdct has been replaced with intelmas.
I have tried to provide more information on this issue, as follows
1. When setting ROW_FORMAT= compressed when creating InnoDB tables, no matter the logical block size of SSD device is set to 4KB or 512 bytes, it will not cause MariaDB Server process crash phenomenon
2. I tried to set the size of logical sector to 4K on Intel P4610 and ScaleFlux CSD 2000, and reappeared the crash of MariaDB Server process. At the same time, I collected the strace information and core dump information of the process. For details, please refer to the zip file "core_dump_and_strace_file.tar. It can be installed using the software package "isdct-3.0.26.400-1.x86_64.rpm" or "isdct_3.0.26.400-1_amd64.deb"
- PS:Since uploading limits the size of a single file to 10MB, I will provide you with the relevant package files by other means
Thank you. In the strace_intel_nvmessd_p4610-4k.txt, I see the following:
io_setup(1, [140188571918336]) = 0
|
open("/tmp/ib8vq1xh", O_RDWR|O_CREAT|O_EXCL|O_CLOEXEC, 0600) = 8
|
unlink("/tmp/ib8vq1xh") = 0
|
io_submit(140188571918336, 1, [{pwrite, fildes=8, str="\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., nbytes=16384, offset=0}]) = 1
|
io_getevents(140188571918336, 1, 1, [{data=0, obj=0x7ffc9e6628c0, res=16384, res2=0}], NULL) = 1
|
close(8) = 0
|
io_destroy(140188571918336) = 0
|
io_setup(2048, [140188570193920]) = 0
|
I believe that all these calls except the last one are part of is_linux_native_aio_supported().
This "probe" write is for innodb_page_size (default 16384) bytes, using an aligned buffer, and I do not think that it can be related to the crash.
I would expect there to be further io_submit() and io_getevents() calls in the trace before the crash, and I am not seeing that. In fact, I am not seeing any other io_ system calls between the above and the SIGABRT. As far as I can tell, no .ibd files should be open at the time of the crash. A probe is opening and closing all files. The only file descriptors that could be open in O_DIRECT mode at the time of the crash are "./ibtmp1" (file descriptor 12) and "./ibdata1" (file descriptor 10). I found only synchronous pread64() for file descriptor 10, and no asynchronous callback.
For the other trace, strace_scaleflux-csd2000-4k.txt, it looks similar (including the file descriptor numbers for the data files).
I did not check the core dumps yet, because in order to interpret those, I would need a copy of the mariadbd executable that you were using, as well as a copy of all shared libraries (listed by ldd mariadbd). Maybe it would be easier if you posted the output of the following:
gdb -ex 'set height 0' -ex 'print *cb' -ex 'thread apply all backtrace full' -ex 'quit' mariadbd core_intel_nvmessd_p4610-4k.20772
|
For this to be useful, debug symbols for mariadbd should be available. If you are using a MariaDB package instead of compiling it from the source code, then the debugging symbols are usually available in a separate package that needs to be additionally installed. We need the debugging symbols in order to see the local variables and the function parameter values.
I am not familiar with the internals of strace. Maybe it can lose a trace of some system calls if the monitored process is killed? After all, there was no evidence of any write to a data file in the traces, and if I remember correctly, neither the system tablespace nor the temporary tablespace should ever be written in smaller than innodb_page_size blocks.
Because the crash occurs very early after startup, this should be easy to fix, once I get remote access to a system. We are working on that.
I got remote access to a system, but possibly used the wrong device because I was unable to repeat the failure yet. This will take some time, because the sysadmin is in a different time zone.
I am able to repeat problems. In the test innodb.innodb-page_compression_zip, another surprise emerged. An error is being reported for a 512-byte write to the following table:
create table innodb_normal (c1 int, b char(20)) engine=innodb; |
…
|
alter table innodb_normal page_compressed=1 page_compression_level=8, |
algorithm=instant;
|
This looks like a possible regression due to MDEV-16328 in 10.3.10. At the time the data file was created, it was completely acceptable to invoke os_file_set_nocache() on it. But, on the ALTER TABLE we did not remove the O_DIRECT attribute.
After I worked around that failure by modifying the test case, a 512-byte write was attempted on another file, on which we had enabled O_DIRECT earlier:
|
mariadb-10.5.9 |
#0 os_file_set_nocache (fd=44,
|
file_name=0x7fffc402e408 "./test/innodb_page_compressed1.ibd",
|
operation_name=0x55555701006f "CREATE")
|
at /home/mariadb/mariadb-10.5.9/storage/innobase/os/os0file.cc:3479
|
#1 0x000055555672f865 in os_file_create_func (
|
name=0x7fffc402e408 "./test/innodb_page_compressed1.ibd", create_mode=52,
|
purpose=61, type=100, read_only=false, success=0x7ffff03cbb94)
|
at /home/mariadb/mariadb-10.5.9/storage/innobase/os/os0file.cc:1426
|
#2 0x000055555698e58a in pfs_os_file_create_func (key=51,
|
name=0x7fffc402e408 "./test/innodb_page_compressed1.ibd", create_mode=180,
|
purpose=61, type=100, read_only=false, success=0x7ffff03cbb94,
|
src_file=0x5555570fb938 "/home/mariadb/mariadb-10.5.9/storage/innobase/fil/fil0fil.cc", src_line=2329)
|
at /home/mariadb/mariadb-10.5.9/storage/innobase/include/os0file.ic:168
|
#3 0x0000555556997ea1 in fil_ibd_create (space_id=7,
|
name=0x7fffc4029ca8 "test/innodb_page_compressed1",
|
path=0x7fffc402e408 "./test/innodb_page_compressed1.ibd", flags=268435509,
|
size=4, mode=FIL_ENCRYPTION_DEFAULT, key_id=1, err=0x7ffff03cc0f0)
|
at /home/mariadb/mariadb-10.5.9/storage/innobase/fil/fil0fil.cc:2326
|
…
|
#21 0x0000555555e8561f in mysql_parse (thd=0x7fffc4000db8,
|
rawbuf=0x7fffc4017930 "create table innodb_page_compressed1 (c1 int, b char(20)) engine=innodb page_compressed=1 page_compression_level=1", length=114,
|
parser_state=0x7ffff03cf510)
|
Either we must ensure to never enable O_DIRECT on page_compressed files, or we must make the write size a multiple of the underlying block size.
There is a data field fil_node_t::block_size that is supposed to store the file system block size. But, it is only being assigned in fil_node_t::read_page0(), that is, when accessing pre-existing data files for the first time since the server started up. Here is a minimal test case to demonstrate this.
--source include/have_innodb.inc
|
create table t1 (c1 int, b char(20)) engine=innodb; |
--source include/restart_mysqld.inc
|
alter table t1 page_compressed=1, algorithm=instant; |
flush table t1 for export; |
unlock tables;
|
drop table t1; |
If the line to restart the server is present, the server will not crash, because after restart, we would invoke fil_node_t::read_page0() to correctly initialize fil_node_t::block_size. If it is missing, the server will crash during the flush table t1 for export statement, because we left fil_node_t::block_size at the value 0 when creating the file.
xiaoboluo768, I think that you can apply the idea of my above test case to work around the bug: First create the tables normally (without a page_compression attribute), then restart the server and execute ALTER TABLE to enable compression, and finally insert the data.
I should have a fix for this soon.
I think I should wait for this problem to be fixed and then I will run the stress test script for testing, because the test is not very urgent at the moment
There was an earlier attempt to fix this bug: MDEV-21584 Linux aio returned OS error 22
However, because we were unable to test it on a system that has a larger block size than 512 bytes, the fix turned out to be incomplete.
I have a fix for 10.5 and 10.6 that makes the tests pass on the remote system.
The earlier attempt of fixing this (MDEV-21584) intended to disable O_DIRECT for page_compressed tables, but the check was incorrect for files that were created with innodb_checksum_algorithm=full_crc32, and the check was omitted during file creation (executed only when opening pre-existing files). But, as far as I can tell, there is no need to disable O_DIRECT; we only have to ensure that fil_node_t::block_size is set correctly.
Before my fix, I got failures also for ROW_FORMAT=COMPRESSED tables using KEY_BLOCK_SIZE=1 (1024 bytes) or KEY_BLOCK_SIZE=2 (2048 bytes). It easiest to refuse O_DIRECT for them. I intend to deprecate and remove that format; MDEV-23497 is the first step towards that.
wlad is now checking that after my fix, everything will work correctly on Microsoft Windows, and then I will have to port and test the fix on 10.2, 10.3, 10.4. I believe that all major versions will differ a little in this area.
I verified that already MariaDB 10.2 is broken. Furthermore, MDEV-21584 unnecessarily disabled O_DIRECT on page_compressed data files. And it failed to disable the equivalent (FILE_FLAG_NO_BUFFERING) for ROW_FORMAT=COMPRESSED tables with 1024- or 2048-byte page size on Microsoft Windows.
I tested 10.2, 10.4 and 10.6 based branches without and with my fix. I will keep this ticket open until the fix has been merged up to 10.6.
On 10.4, I used the following invocation:
./mtr --parallel=$(nproc) --big-test --suite=innodb,innodb_zip,encryption,mariabackup --mysqld=--loose-innodb-flush-method=O_DIRECT --mysqld=--loose-innodb-checksum-algoritm=full_crc32
|
while mysql-test/var was a symlink to a directory in the SSD with 4KiB block size. 10.4 would normally use innodb_checksum_algorithm=crc32; the default was changed for 10.5 in MDEV-19534.
Thank you for the report. The crash occurs due to the following:
{ut_a(cb->m_err == DB_SUCCESS);This code was refactored in
MDEV-16264.I see that you are using innodb_flush_method=O_DIRECT, which should ensure that DMA is being used. Without it, the Linux kernel could use more CPU in the io_submit() call. In 10.6, we finally changed that to be the default (
MDEV-24854).I suspect that the this is somehow related to the use of page_compressed=1 tables. We have tested MariaDB on various hardware (including NVMe). I think that I ran the ./mtr regression test suite on my NVMe (Intel Optane 960, INTEL SSDPED1D960GAY) when I implemented
MDEV-24854. It includes some tests with page_compressed=1.I think that we need more information to fix this. Could you provide some strace output that could hint what could have gone wrong?
Did I get it right that this does not occur if you are not page_compressed tables? What about ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=1 (using 1KiB block size)? I understood that we should avoid setting O_DIRECT on the files in either case. The strace output would help verify that.
If I have understood it correctly, for the ScaleFlux hardware, we would probably want to change page_compressed code so that the various IORequest::PUNCH will never be used, but instead sequences of NUL bytes will be written. That is, we would want to let the file system treat the data files as regular files, and the smart storage would transparently compress the individual sectors.