Details
-
Bug
-
Status: Closed (View Workflow)
-
 Critical
Critical
-
Resolution: Fixed
-
10.4.11, 10.4.19, 10.5.10
-
Debian Stretch
Description
I recently upgraded from 10.2 to 10.4 and had massive performance problems since then (plus 50% CPU load, very slow performance of many cron jobs which now take double the time). While I am still searching for many of the reasons, I found one query in particular in which MariaDB does not use a primary index, which leads to the query taking indefinitely long (1 hour+) instead of about 110ms. This is that query:
SELECT
|
p.product_id,
|
SUM(op.quantity) AS quantity_sold, |
COUNT(DISTINCT o.order_id) AS orders_number |
FROM
|
shop_aapo.orders o,
|
shop_aapo.orders_products op,
|
(
|
(
|
(
|
shop_aapo.products p
|
LEFT JOIN shop_aapo.admin_products_ausserhandel a ON (a.product_id = p.product_id AND a.admin_id = 1) |
)
|
LEFT JOIN shop_aapo.products_availability_sources_voigt v ON (p.product_id = v.product_id) |
)
|
LEFT JOIN shop_aapo.products_availability_sources_galexis_oldschool g ON (p.product_id = g.product_id AND g.last_checked > 1576505788) |
)
|
LEFT JOIN shop_aapo.products_availability_sources_galexis_csv g2 ON (g2.product_id = p.product_id AND g2.outdated = 0) |
WHERE
|
o.order_id = op.order_id
|
AND op.product_id = p.product_id |
AND o.order_status = "active" |
AND ( |
v.product_status IN ("C","K","U","Z","S") |
OR g.available_msg IN ("Ausser Handel","Fehlt beim Lieferanten") |
OR g2.status_np IN (5,7) |
OR g2.status_la IN (5,7) |
)
|
AND o.create_date >= 1569161788 |
AND ( |
a.product_id IS NULL |
OR a.snooze_ts < 1576073788 |
)
|
GROUP BY |
p.product_id
|
HAVING
|
quantity_sold>5
|
AND orders_number>2 |
ORDER BY |
quantity_sold DESC |
LIMIT
|
0, 51
|
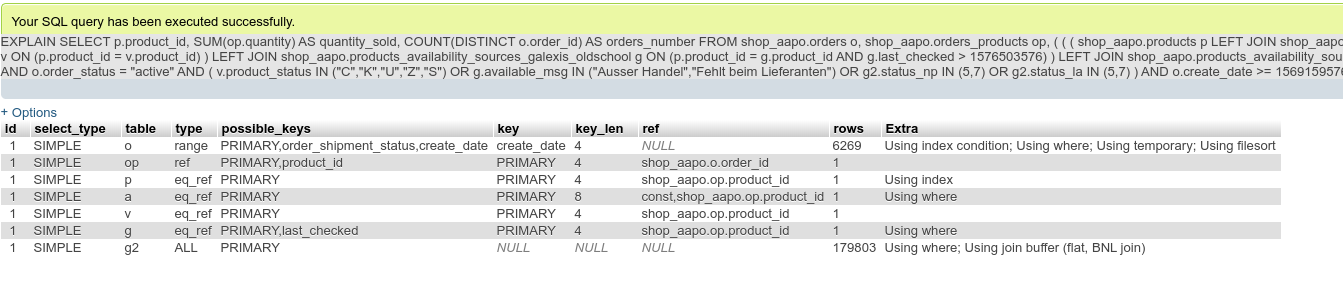
Many of the parts of the query are not important, what is important are all the LEFT JOINs I am doing - because each left join is using the PRIMARY index of a table, matching exactly one entry (or no entry), yet with the very last LEFT JOIN of the alias g2 MariaDB is not using that PRIMARY index, leading to the EXPLAIN output in mariadb_explain1.png I attached to this issue.
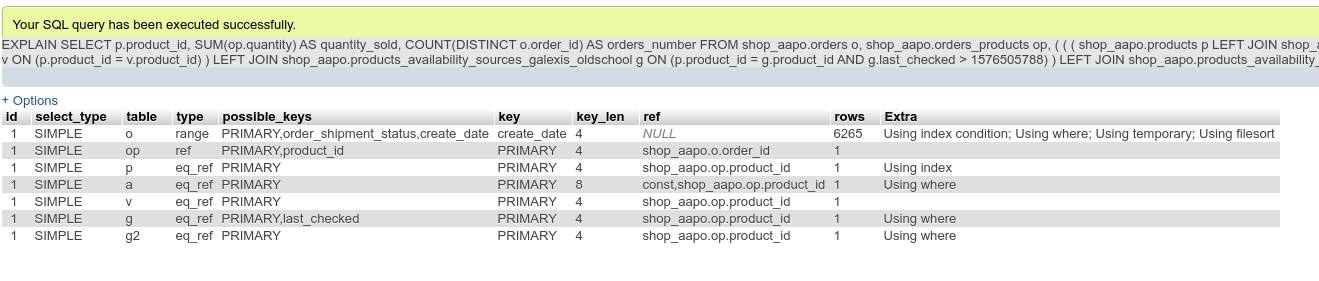
When I add "FORCE INDEX FOR JOIN (PRIMARY)" after "g2" in the query, then MariaDB correctly joins the table and you can see the EXPLAIN in mariadb_explain2.png attached to this issue.
I switched off all new optimizer switches since MariaDB 10.2, which did not solve this problem, so I am guessing this must be some other kind of bug. As you can see from the EXPLAIN MariaDB knows it could use the PRIMARY index, yet decides against it to do "Using where; Using join buffer", which is a million times slower unfortunately.
Attachments
Issue Links
- relates to
-
-

- Closed
-
-
-
- Stalled
-
